Hash
First of all, let's go through the basics and get acquainted with such a concept as a hash!
Hash algorithm - is a mathematical function that takes in data of any size and produces a output called a hash or message digest. The output is a unique representation of the input data, which can be used to verify that the data has not been tampered with. Hash algorithms are used to ensure the integrity and authenticity of data. In simple terms, a hash is a unique digital fingerprint of a piece of data. It's like a code that represents the data. The code is generated by a mathematical function called a hash function. If the data changes even a little bit, the hash will be different.
There are primary key characteristics for hash:
-
Deterministic: A hash function should always produce the same output for a given input. This means that if you hash the same data twice, you should get the same hash value both times.
-
Irreversibility: It should be computationally infeasible to reconstruct the original input data from its hash value. This property is important for security, as it protects the original data from being discovered by attackers who only have access to the hash value.
-
Uniformity: A hash function should produce a uniform distribution of hash values across all possible inputs. This means that each hash value should be equally likely to occur, and there should be no patterns or biases in the distribution of hash values.
-
Unpredictability: It should be computationally infeasible to predict the hash value of an input based on the hash values of other inputs or the properties of the hash function itself. This property is important for security, as it makes it difficult for attackers to create a collision (two different inputs that produce the same hash value).
-
Irreversibility: It should be computationally infeasible to reconstruct the original input data from its hash value. This property is important for security, as it protects the original data from being discovered by attackers who only have access to the hash value.
-
Resistance to collision attacks: A hash function should be resistant to collision attacks, which involve finding two different inputs that produce the same hash value. Collision attacks can be used to create fraudulent digital signatures or to bypass access controls, so it is important for a hash function to be designed to resist them.
Other characteristics of hashes you can find on the Wikipedia page:
https://en.wikipedia.org/wiki/Hash_function
Data verification. Blacklist and Whitelist.
In the context of antivirus software, hash algorithms are used to detect malware or exclude false-positive alerts. Antivirus software maintains a database of known malware hashes (blacklist) and trusted software hashes (whitelist). When a file is scanned, its hash is compared to the hashes in the database. The most commonly used hash algorithms for data verification are MD5, SHA-1, SHA-256 and SHA-512.
The use of hashes in antivirus blacklists and whitelists helps to speed up the scanning process, since the antivirus program doesn't need to perform a detailed analysis of each file to determine if it is malicious or not. Instead, it can compare the hash values of files against those in the blacklist/whitelist to quickly identify known threats or trusted apps.
Blacklist. In the context of cybersecurity and antivirus software, a blacklist is a list of known malicious files or parts of these files. When an antivirus program scans a computer or network, it compares the files and entities it encounters against the blacklist to identify any threats. If a file or entity matches an entry on the blacklist, the antivirus program will take action to remove or quarantine it to prevent it from causing harm.
While blacklists can be useful in detecting and preventing known threats, they are not always effective in protecting against new and unknown threats. Attackers can use various techniques, such as obfuscation or polymorphism, to modify the code or behavior of a file or entity to evade detection by antivirus programs.
Therefore, antivirus programs often use a combination of techniques, such as whitelisting and behavior-based detection, to complement the use of blacklists and provide more comprehensive protection against a wider range of threats.
Whitelist. In the context of cybersecurity and antivirus software, a whitelist is a list of trusted files that are known to be safe. If a file or entity matches an entry on the whitelist, the antivirus program will allow it to open/run without taking any action, since it is considered safe.
Whitelists are useful in preventing false positives in antivirus and security programs. False positives occur when a program or file is flagged as malicious or harmful when it is actually safe. By using a whitelist, security programs can bypass these false positives, which can save time and prevent unnecessary alerts.
Using hashes and blacklists/whitelists can be an effective way to protect against known threats and prevent false positives in antivirus and security programs.
Why do antiviruses use several hash algorithms?
Antivirus programs use multiple hash algorithms for several reasons:
-
While blacklists can be effective in detecting and preventing known threats, they are not foolproof. Attackers can use various techniques to evade detection, such as modifying the data to avoid matching the signatures in the blacklist. These techniques are named as “collision attacks”. A collision attack is a type of cryptographic attack where an attacker tries to find two different inputs, such as files or messages, that produce the same hash value when run through a hash function (collision). The goal of a collision attack is to create a pair of inputs that can be used to subvert a system that relies on the integrity of hash values, such as digital signatures, password authentication, or data integrity checks. If an attacker can find a collision, he can use it to bypass the security measures that rely on the hash function. To mitigate the risk of collision attacks, antiviruses use strong hash functions that are resistant to attacks, and use several hash functions simultaneously. For example, if an antivirus program only used MD5 hash algorithm, an attacker could potentially create a malicious file that has the same MD5 hash as a legitimate file, and trick the antivirus program into treating the malicious file as safe. However, using multiple hash algorithms, such as MD5, SHA-1, and SHA-256, makes it more difficult for an attacker to create a collision attack that would work against all of the algorithms simultaneously.
-
Efficiency: Different hash algorithms have different computational requirements, and some may be more efficient than others depending on the file size, type, or other factors. Using multiple hash algorithms allows antivirus programs to select the most appropriate algorithm for a given situation, which can save time and processing power. For example, SHA-256 may be more computationally intensive than MD5, so an antivirus program may choose to use MD5 for smaller files and SHA-256 for larger files.
-
Flexibility: Different hash algorithms are designed for different use cases and applications. By using multiple hash algorithms, antivirus programs can adapt to different needs and scenarios, such as detecting malware, verifying file integrity, or detecting tampering or modification. For example, a forensic investigator may use a different hash algorithm than an antivirus program to ensure that data has not been modified during an investigation.
Using multiple hash algorithms is a best practice in cybersecurity and antivirus software development, as it provides robustness, compatibility, efficiency, and flexibility in detecting and preventing cyber threats.
How do antiviruses recognize similar but not identical data and files?
Similar but not identical files can be a problem in cybersecurity because they can be used by attackers to evade detection by antivirus software.
For example, an attacker may take a known malware file and make slight modifications to its code or structure, such as changing variable names or reordering instructions. These modifications can be enough to create a new file that is similar but not identical to the original malware file, and which may not be detected by antivirus software that relies on traditional hash-based detection methods.
Additionally, attackers may use similar but not identical files to create polymorphic malware, which can change its code or structure with each infection to avoid detection. Polymorphic malware can be very difficult to detect using traditional antivirus techniques, which rely on recognizing specific patterns or signatures in the malware code.
To solve this problem, antiviruses use fuzzy hashes.
Fuzzy hashing is a technique used by some antivirus software to detect similar but not identical files, including polymorphic malware. By breaking a file into smaller pieces and comparing hashes of those pieces to those of other files, fuzzy hashing can identify files that have similar code or structure, even if they are not identical.
Fuzzy hashing works by identifying sequences of bytes that appear frequently across the file. These sequences, also known as "chunks," are then hashed using a cryptographic hash function to generate a hash value. The hash values of the chunks are then compared to those of other files to identify chunks that are similar.
The advantage of fuzzy hashing is that it can detect similarities even when files have been modified or obfuscated, making it a powerful tool for identifying variants of known malware. For example, if an attacker modifies a known malware file by changing the names of variables or functions, traditional hash-based detection methods may not detect the modified file. However, fuzzy hashing can still detect the modified file by identifying chunks that are similar to those of the original malware file. Unlike cryptographic hashing algorithms like MD5, SHA-1 or SHA-512, fuzzy hashing algorithms produce variable-length hash values that are based on the similarity of the input data.
Advantages of fuzzy hashes:
-
Detection of similar files: Fuzzy hashes can detect similar files even if they have been modified slightly, which is useful for identifying variants of known malware.
-
Reduced false positives: Fuzzy hashes can reduce the number of false positives generated by traditional hash-based detection methods. This is because fuzzy hashes can detect files that are similar but not identical to known malware.
-
Resilience to obfuscation: Fuzzy hashes are more resilient to obfuscation techniques used by attackers to evade detection. This is because the fuzzy hashing algorithm breaks the file into smaller pieces and generates hashes for each piece, making it more difficult for an attacker to modify the file in a way that evades detection.
Fuzzy hashing has some limitations that can impact its effectiveness in detecting similar but not identical files:
-
False positives: Fuzzy hashing can produce false positives, where legitimate files are flagged as malicious because they have similar code or structure to known malware. This can occur if the files share common libraries or frameworks.
-
Performance: Fuzzy hashing can be computationally intensive, especially for large files. This can slow down the scanning process and impact system performance.
-
Size limitations: Fuzzy hashing may not work well on very small files or files with low entropy, as there may not be enough unique chunks to generate meaningful hashes.
-
Tampering: Fuzzy hashing may not be effective if an attacker specifically targets it and modifies a file to avoid detection. For example, an attacker could deliberately change the structure of a file to prevent it from being identified by fuzzy hashing.
What is the difference between cryptographic hash algorithms and fuzzy hash algorithms?
Cryptographic hash algorithms and fuzzy hash algorithms are both used in cybersecurity, but they have different purposes and characteristics.
Cryptographic hash algorithms, such as SHA-256 and MD5, are designed to provide data integrity and authenticity by generating fixed-length, unique hash values that are nearly impossible to reverse-engineer. Cryptographic hash algorithms are used to verify the integrity of data.
Fuzzy hash algorithms, such as SSDEEP, are designed to identify similar but not identical data, such as files that have been modified or repackaged by malware authors. Fuzzy hashing uses a sliding window technique to break data into small chunks and generate variable-length, probabilistic hashes that are compared against a database of known malware hashes to identify potentially malicious files.
Cryptographic hash algorithms are designed to be collision-resistant, meaning that it is extremely difficult to find two inputs that produce the same hash output. Fuzzy hash algorithms do not need to be collision-resistant since they are designed to detect similarities between files rather than produce unique hash outputs
The main difference between cryptographic hash algorithms and fuzzy hash algorithms is their level of determinism. Cryptographic hash algorithms produce fixed-length, deterministic hashes that are unique for each input, while fuzzy hash algorithms produce variable-length, probabilistic hashes that are similar for similar inputs.
What fuzzy hashing algorithms will we use in our solution?
In our solution we are going to use SSDEEP and TLSH.
ssdeep is a fuzzy hashing algorithm that is used for identifying similar but not identical data, such as malware variants. It works by generating a hash value that represents the similarity of the input data, rather than a unique identifier like cryptographic hash functions. The output of ssdeep is variable-length and probabilistic, which allows it to detect even minor differences between two files. ssdeep is commonly used in malware analysis and detection, and it is also integrated into various security tools and antivirus software.
TLSH (Trend Micro Locality Sensitive Hash) is a fuzzy hashing algorithm that is used for identifying similar but not identical data, such as malware variants. It works by creating a hash value that captures the unique features of the input data, such as byte frequency and order. The output of TLSH is variable-length and probabilistic, which allows it to detect similarities even if the input data has been modified or obfuscated. TLSH is commonly used in malware analysis and detection, and it is also integrated into various security tools and antivirus software.
ssdeep and TLSH both use distance metrics to determine the similarity between two hash values. However, the distance metrics used by ssdeep and TLSH are different.
ssdeep uses the "fuzzy hash distance" metric to calculate the distance between two hash values. This distance metric is based on the number of matching and non-matching blocks between the two hashes, as well as the size of the hashes. The distance metric is a percentage value that ranges from 0 to 100, where 0 means the two hashes are identical, and 100 means the two hashes are completely dissimilar.
TLSH, on the other hand, uses the "total diff" metric to calculate the distance between two hash values. This distance metric is based on the difference between the locality-sensitive features of the two input data sets. The output of the "total diff" metric is a value between 0 and 1000, where 0 means the two hash values are identical, and 1000 means the two hash values are completely different.
Building the hashing module
For our solution, we will use open-source libraries:
1. PolarSSL: https://polarssl.org/
PolarSSL is a free and open-source software library for implementing cryptographic protocols such as Transport Layer Security (TLS), Secure Sockets Layer (SSL), Datagram Transport Layer Security (DTLS). It provides various cryptographic algorithms and protocols, including hash functions, symmetric and asymmetric encryption, digital signatures, and key exchange algorithms. PolarSSL is designed to be lightweight and efficient, making it suitable for use in resource-constrained environments.
2. ssdeep: http://ssdeep.sf.net/
3. TLSH: https://github.com/trendmicro/tlsh/
After implementing the libraries in the project, we add a simple code:
struct HashData
{
BYTE md5[16];
BYTE sha1[20];
BYTE sha512[64];
std::string ssdeep;
std::string tlsh;
};
HashData hash(const void* buff, uint64_t size)
{
HashData snap = {};
hashes::md5(buff, size, snap.md5);
hashes::sha1(buff, size, snap.sha1);
hashes::sha4(buff, size, snap.sha512);
snap.ssdeep = hashes::ssdeepHash(buff, size);
snap.tlsh = hashes::tlshHash(buff, size);
return snap;
}
Checking the hashing module
It's time to test the hashing module! To do this, we will create a text file with the following content:
All the World`s a Stage by William Shakespeare
All the world`s a stage,
And all the men and women merely players;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first, the infant,
Mewling and puking in the nurse`s arms.
Then the whining schoolboy, with his satchel
And shining morning face, creeping like snail
Unwillingly to school. And then the lover,
Sighing like furnace, with a woeful ballad
Made to his mistress` eyebrow. Then a soldier,
Full of strange oaths and bearded like the pard,
Jealous in honor, sudden and quick in quarrel,
Seeking the bubble reputation
Even in the cannon`s mouth. And then the justice,
In fair round belly with good capon lined,
With eyes severe and beard of formal cut,
Full of wise saws and modern instances;
And so he plays his part. The sixth age shifts
Into the lean and slippered pantaloon,
With spectacles on nose and pouch on side;
His youthful hose, well saved, a world too wide
For his shrunk shank, and his big manly voice,
Turning again toward childish treble, pipes
And whistles in his sound. Last scene of all,
That ends this strange eventful history,
Is second childishness and mere oblivion,
Sans teeth, sans eyes, sans taste, sans everything.
TEST 1: сreate two identical files with the same content (text above) and calculate hashes.
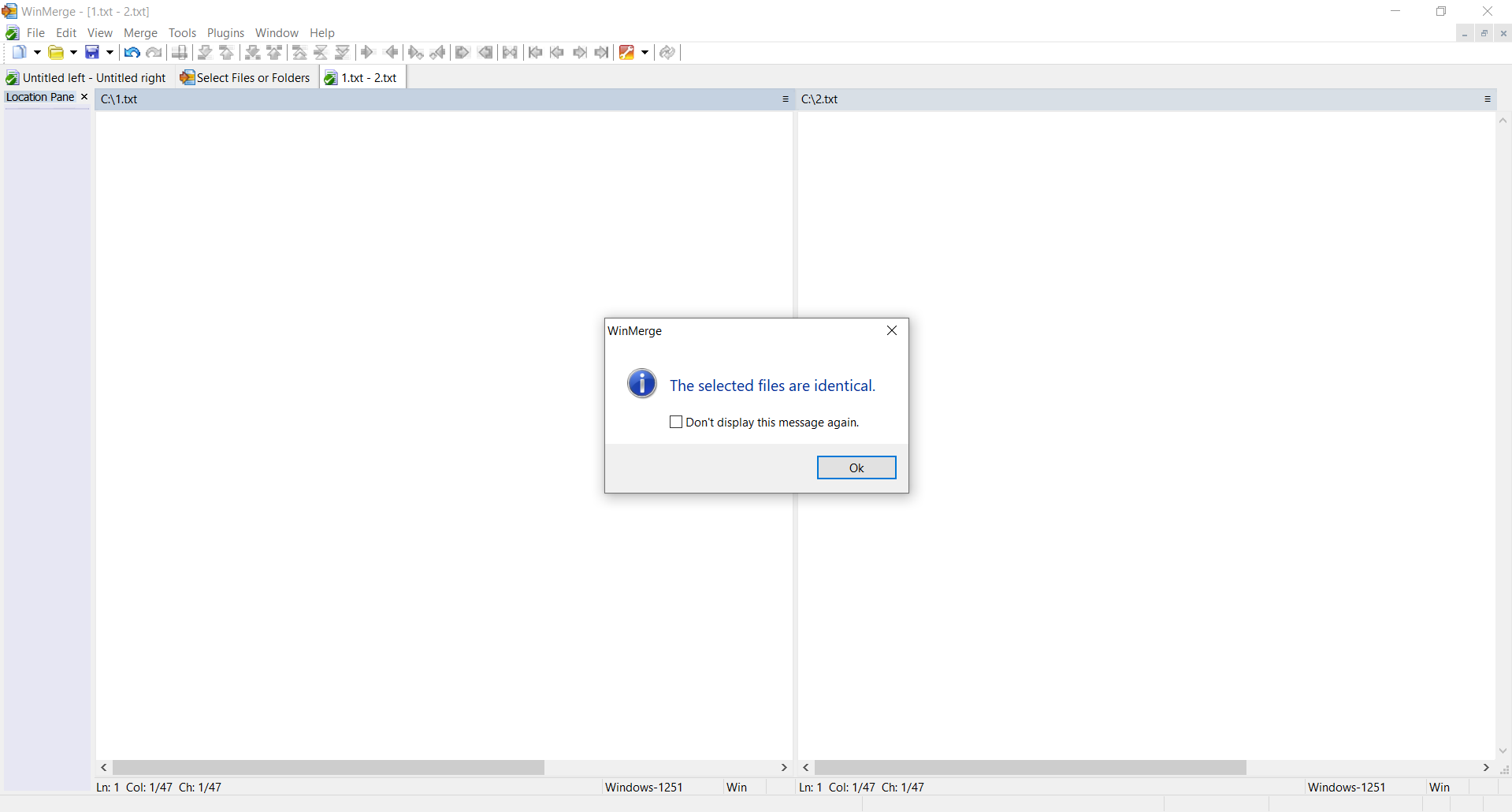
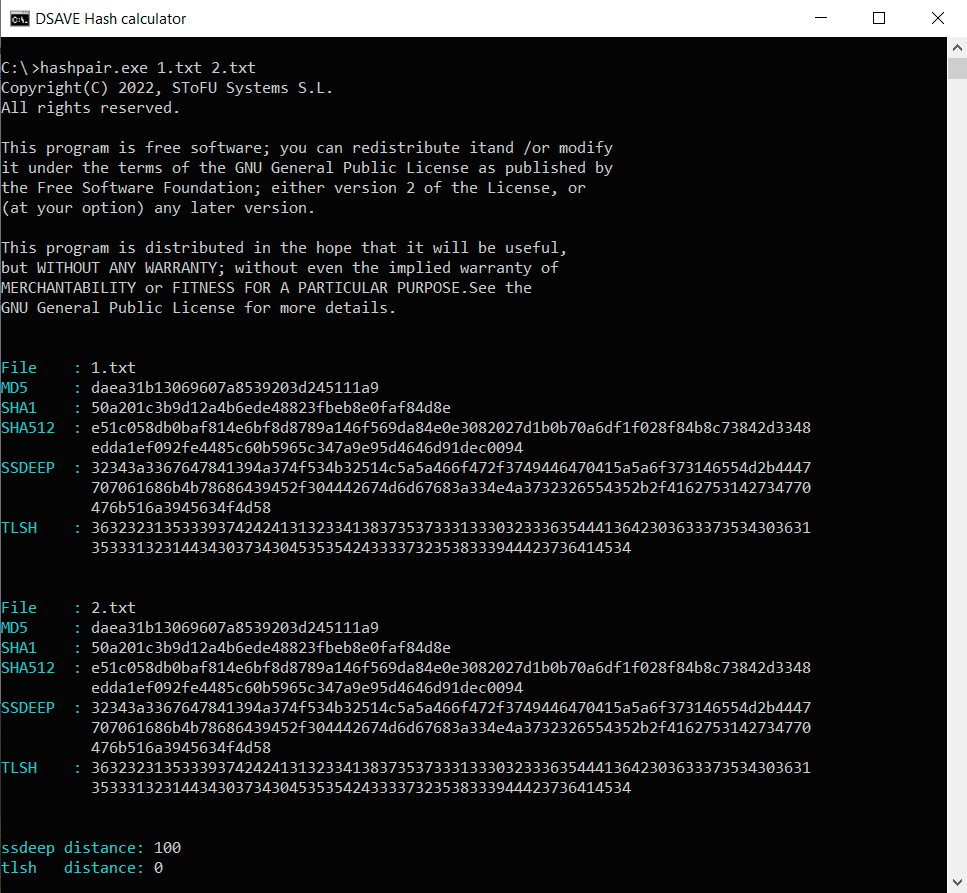
SSDEEP says the files are 100% identical. TLSH says there are 0% differences between files.
TEST 2: Create two identical files with the same content, make changes in the second file and calculate hashes
Second file content:
All the World`s a Stage by William Shakespeare
O lovely maidens, fall in love,
But not with Muscovites,
For Muscovites are foreign folk,
They do not treat you right.
A Muscovite will love for sport,
And laughing go away;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first, the infant,
Mewling and puking in the nurse`s arms.
Then the whining schoolboy, with his satchel
And shining morning face, creeping like snail
Unwillingly to school. And then the lover,
Sighing like furnace, with a woeful ballad
Made to his mistress` eyebrow. Then a soldier,
Full of strange oaths and bearded like the pard,
Jealous in honor, sudden and quick in quarrel,
Seeking the bubble reputation
Even in the cannon`s mouth. And then the justice,
In fair round belly with good capon lined,
With eyes severe and beard of formal cut,
Full of wise saws and modern instances;
And so he plays his part. The sixth age shifts
Into the lean and slippered pantaloon,
With spectacles on nose and pouch on side;
His youthful hose, well saved, a world too wide
For his shrunk shank, and his big manly voice,
Turning again toward childish treble, pipes
And whistles in his sound. Last scene of all,
That ends this strange eventful history,
Is second childishness and mere oblivion,
Sans teeth, sans eyes, sans taste, sans everything.
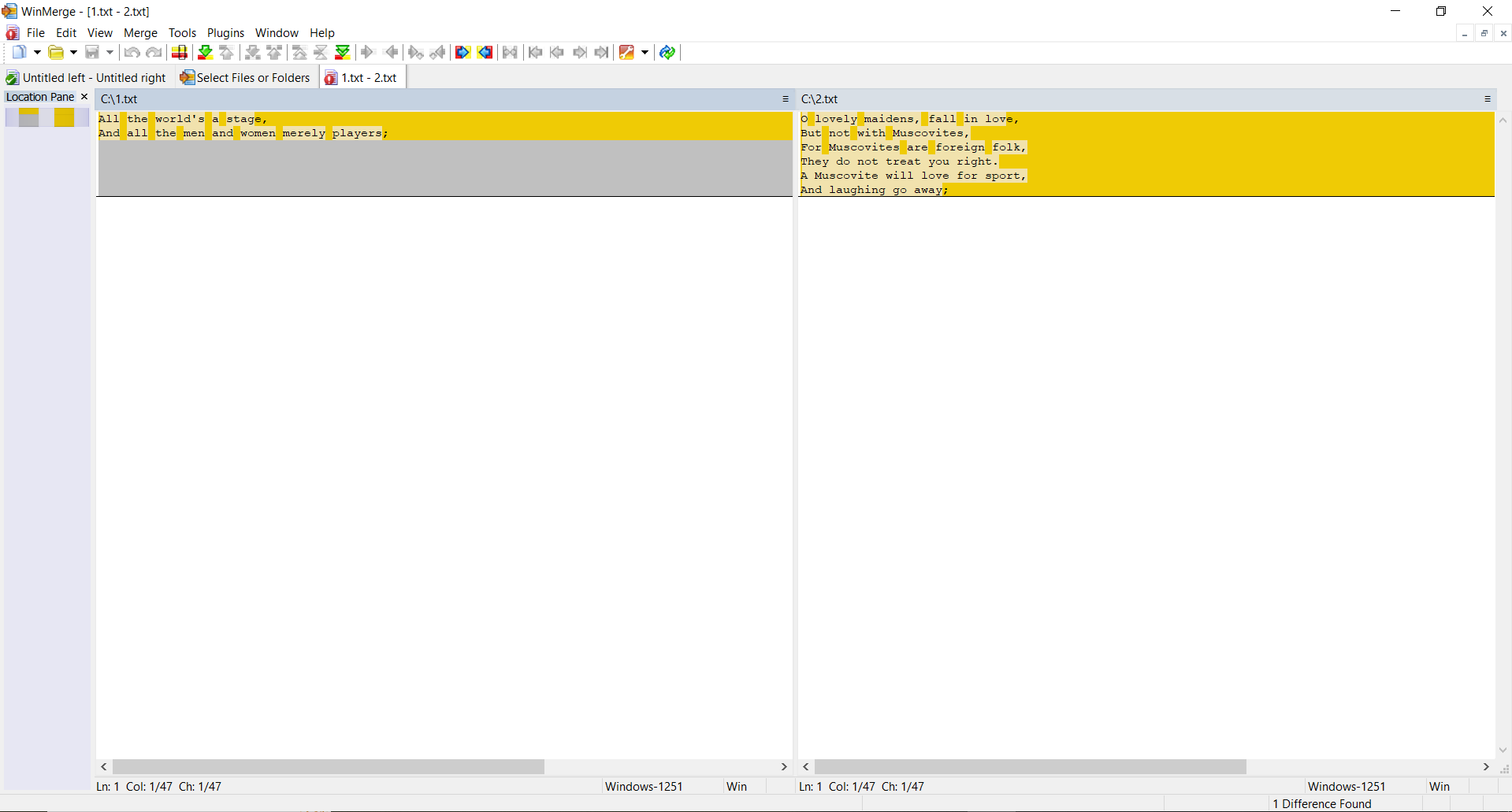
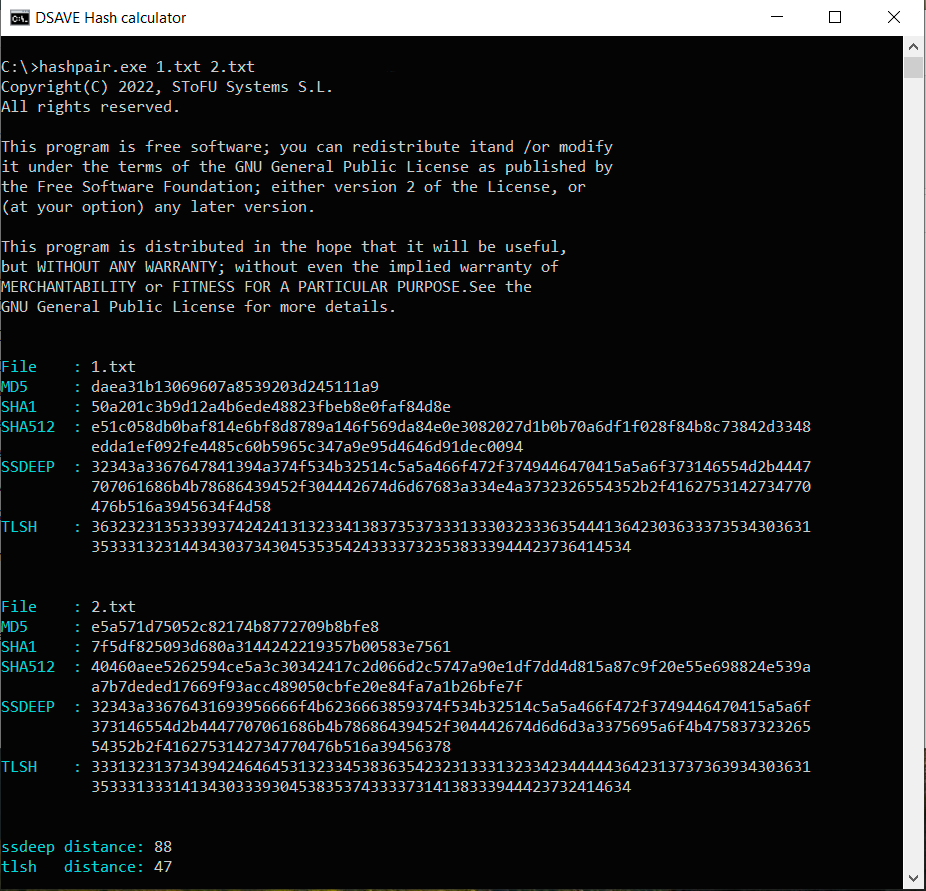
SSDEEP says the files are 88% identical. TLSH says there are 4.7% differences between the files.
TEST 3: calculate hashes for two completely different text files
Second file content:
"Katerina", poem of Taras Shevchenko
(translated by John Weir)
O lovely maidens, fall in love,
But not with Muscovites [2],
For Muscovites are foreign folk,
They do not treat you right.
A Muscovite will love for sport,
And laughing go away;
He`ll go back to his Moscow land
And leave the maid a prey
To grief and shame...
It could be borne
If she were all alone,
But scorn is also heaped upon
Her mother frail and old.
The heart e`en languishing can sing –
For it knows how to wait;
But this the people do not see:
“A strumpet!“ they will say.
O lovely maidens, fall in love,
But not with Muscovites,
For Muscovites are foreign folk,
They leave you in a plight.
Young Katerina did not heed
Her parent`s warning words,
She fell in love with all her heart,
Forgetting all the world.
The orchard was their trysting-place;
She went there in the night
To meet her handsome Muscovite,
And thus she ruined her life.
Her anxious mother called and called
Her daughter home in vain;
There where her lover she caressed,
The whole night she remained.
Thus many nights she kissed her love
With passion strong and true,
The village gossips meanwhile hissed:
“A girl of ill repute!”
Let people talk, let gossips prate,
She does not even hear:
She is in love, that`s all she cares,
Nor feels disaster near.
Bad tidings came of strife with Turks,
The bugles blew one morn:
Her Muscovite went off to war,
And she remained at home.
A kerchief o`er her braids they placed
To show she`s not a maid,
But Katerina does not mind,
Her lover she awaits.
He promised her that he’d return
If he was left alive,
That he`d come back after the war –
And then she`d be his wife,
An army bride, a Muscovite
Herself, her ills forgot,
And if in meantime people prate,
Well, let the people talk!
She does not worry, not a bit –
The reason that she weeps
Is that the girls at sundown sing
Without her on the streets.
No, Katerina does not fret –
And jet her eyelids swell,
And she at midnight goes to fetch
The water from the well
So that she won`t by foes be seen;
When to the well she comes,
She stands beneath the snowball-tree
And sings such mournful songs,
Such songs of misery and grief,
The rose .itself must weep.
Then she comes home - content that she
By neighbours was not seen.
No, Katerina does not fret.
She`s carefree as can be -
With her new kerchief on her head
She looks out on the street.
So at the window day by day
Six months she sat in vain....
With sickness then was overcome,
Her body racked with pain.
Her illness very grievous proved.
She barely breathed for days ...
When it was over - by the stove
She rocked her tiny babe.
The gossips` tongues now got free rein.
The other mothers jibed
That soldiers marching home again
At her house spent the night.
“Oh, you have reared a daughter fair.
And not alone beside
The stove she sits - she`s drilling there
A little Muscovite.
She found herself a brown-eyed son...
You must have taught her how!...
Oh fie on ye, ye prattle tongues,
I hope yourselves you`ll feel
Someday such pains as she who bore
A son that you should jeer!
Oh, Katerina, my poor dear!
How cruel a fate is thine!
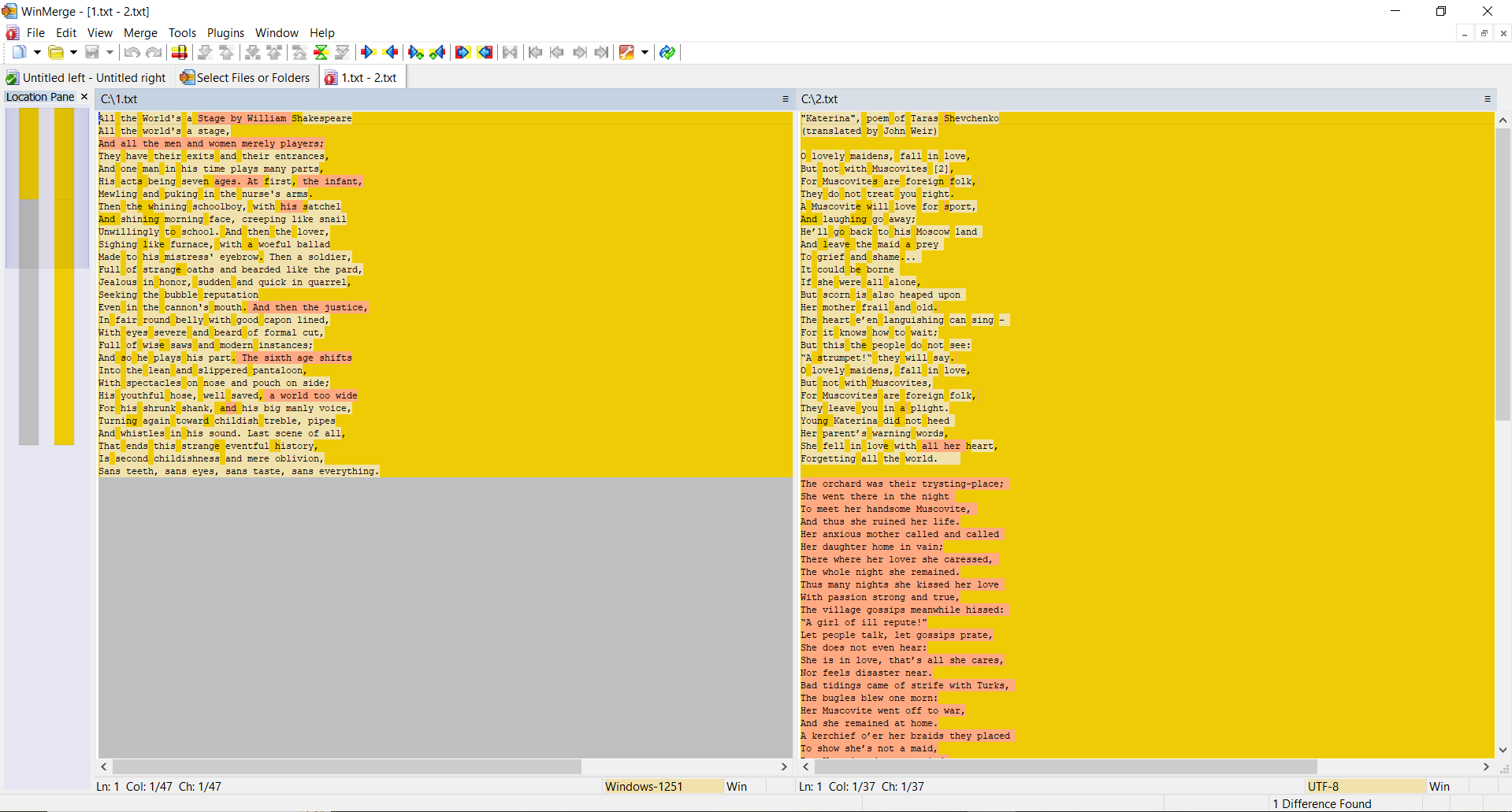
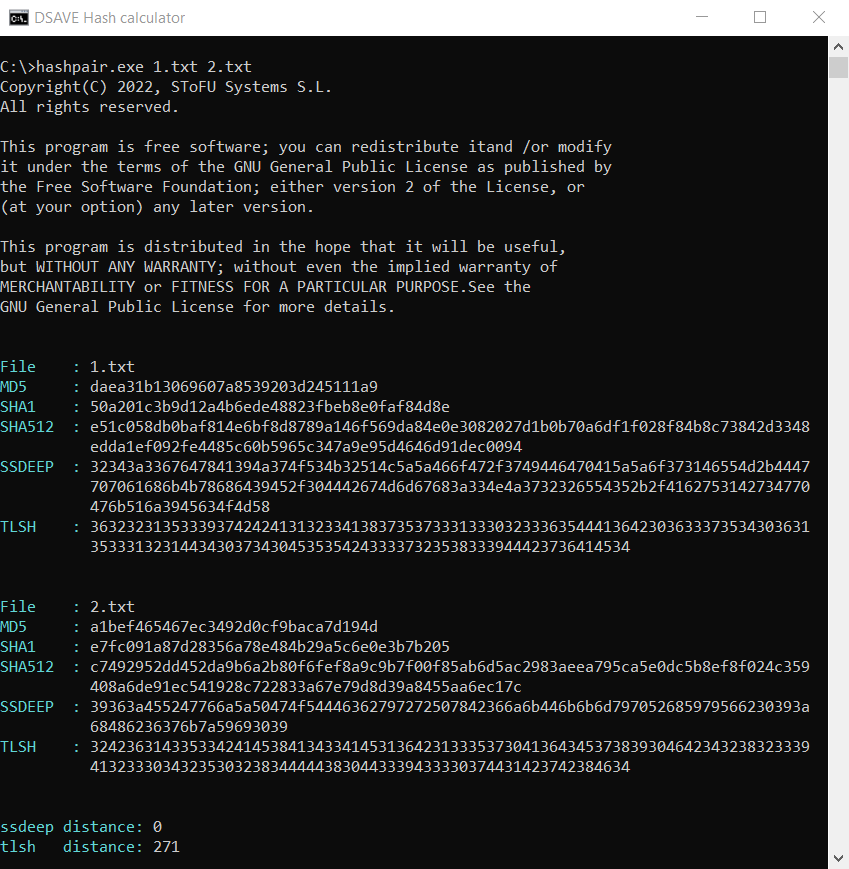
SSDEEP says the files are completely different, with 0% matches. However, TLSH says the files are only 27.1% different.
Why is that? After all, we consider the distance between two completely different text files, right?
The thing is that, as we said above, the TLSH algorithm takes into account frequencies.
Despite the fact that the texts are different, nevertheless they are written in the same language, use the same alphabet and have a number of the same words. This feature of this hashing algorithm helps to detect modifications of malicious files.
TEST 4: сompare 2 Windows system files
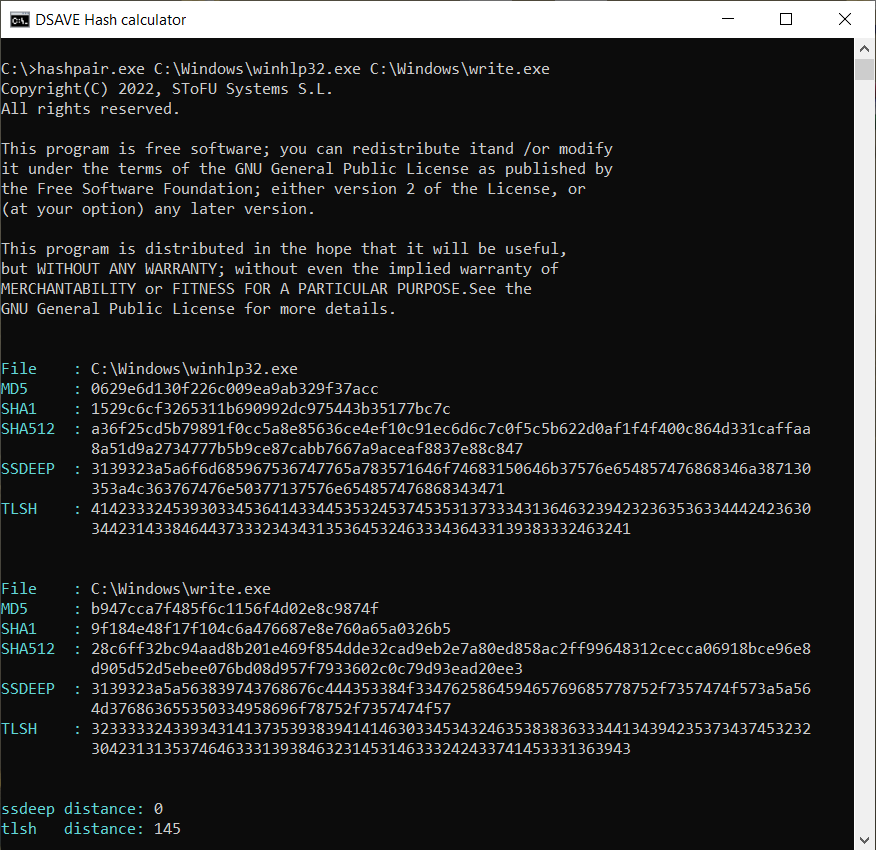
SSDEEP says the files are completely different, with 0% matches.
However, the TLSH algorithm says that the files differ by only 14.5%. This is partly due to the fact that most likely the files were built by the same compiler, by the same company, possibly using the same code patterns. The files have similar VERSION_INFO and MZ headers.
TEST 5: сompare 2 system file and our hashpair.exe file
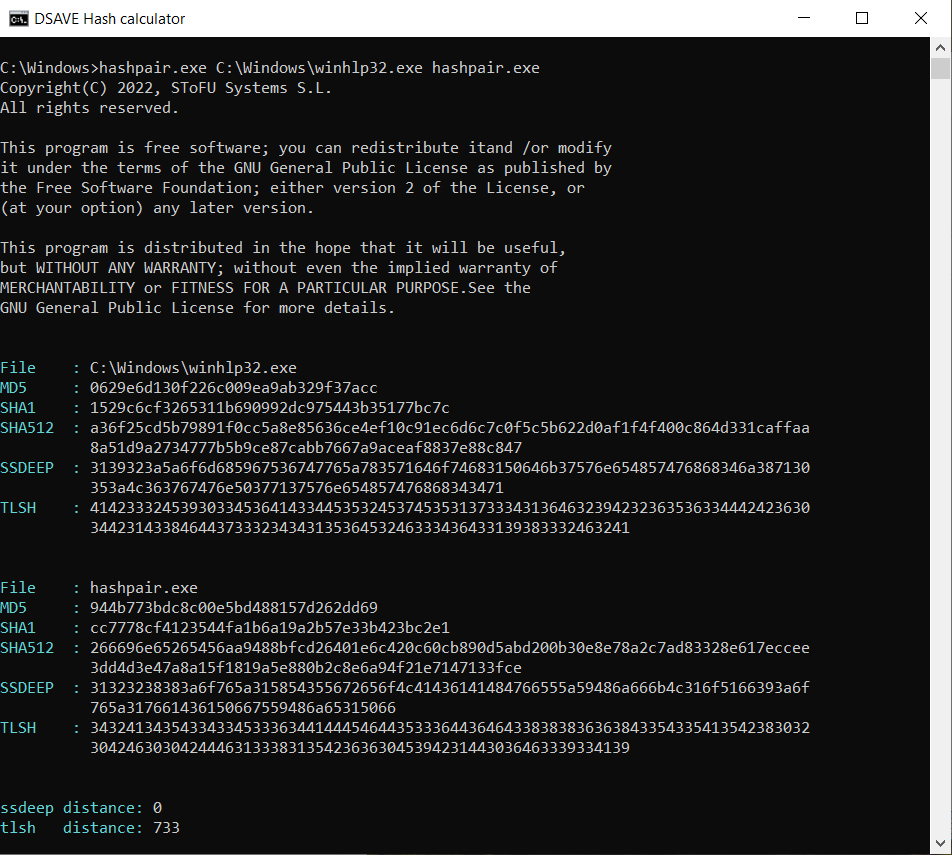
SSDEEP says the files are completely different, with 0% matches.
TLSH algorithm says that the files differ significantly, by 73.3%. These files were compiled by different companies, using different libraries and different compilers. These files have different VERSION_INFO and different MZ headers. Thus, the TLSH algorithm allows you to categorize executable files, helping to identify similar malicious files or malicious files of the same family.
List of tools used
1. WinMerge: https://winmerge.org
WinMerge is an Open Source differencing and merging tool for Windows. WinMerge can compare both folders and files, presenting differences in a visual text format that is easy to understand and handle.
2. Notepad++: https://notepad-plus-plus.org/downloads
Notepad++ is a free (as in “free speech” and also as in “free beer”) source code editor and Notepad replacement that supports several languages. Running in the MS Windows environment, its use is governed by GNU General Public License.
GITHUB
You can find the code of the entire project on our github:
https://github.com/SToFU-Systems/DSAVE
WHAT IS NEXT?
We appreciate your support and look forward to your continued engagement in our community
In the next article we will write together with you the simplest PE resource parser.
Any questions of the authors of the article can be sent to the e-mail: articles@stofu.io
Thank you for your attention and have a nice day!




