Det portable eksekverbare (PE) formatet
Det første man bør starte med er PE-formatet. Kunnskap og forståelse av dette formatet er en forutsetning for å utvikle antivirusmotorer for Windows-plattformen (historisk sett er det store flertallet av virus i verden rettet mot Windows).
Portable Executable (PE)-formatet er et filformat brukt av Windows operativsystemet for å lagre kjørbare filer, som .EXE og .DLL filer. Det ble introdusert med lanseringen av Windows NT i 1993, og har siden blitt standardformatet for kjørbare filer på Windows-systemer.
Før innføringen av PE-formatet brukte Windows en rekke forskjellige formater for kjørbare filer, inkludert New Executable (NE) formatet for 16-bit programmer og Compact Executable (CE) formatet for 32-bit programmer. Disse formatene hadde sitt eget unike sett med regler og konvensjoner, noe som gjorde det vanskelig for operativsystemet å pålitelig laste inn og kjøre programmer.
For å standardisere oppsettet og strukturen til kjørbare filer, introduserte Microsoft PE-formatet med lanseringen av Windows NT. PE-formatet ble designet for å være et felles format for både 32-bit og 64-bit programmer.
En av de viktigste egenskapene til PE-formatet er bruken av en standardisert header, som er plassert i begynnelsen av filen og inneholder en rekke felt som gir operativsystemet viktig informasjon om den kjørbare filen. Denne headeren inkluderer IMAGE_DOS_HEADER og IMAGE_NT_HEADER strukturene, som er delt inn i to hovedseksjoner: IMAGE_FILE_HEADER og IMAGE_OPTIONAL_HEADER.
De fleste overskriftene i PE-formatet er deklarert i headerfilen WinNT.h
IMAGE_DOS_HEADER
IMAGE_DOS_HEADER-strukturen er en eldre topptekst som brukes for å støtte bakoverkompatibilitet med MS-DOS. Den brukes til å lagre informasjon om filen som kreves av MS-DOS, som plasseringen av programmets kode og data i filen, og programmets inngangspunkt. Dette tillot programmer som var skrevet for MS-DOS å kjøre på Windows NT, forutsatt at de var kompilert som PE-filer.
typedef struct _IMAGE_DOS_HEADER
{
WORD e_magic;
WORD e_cblp;
WORD e_cp;
WORD e_crlc;
WORD e_cparhdr;
WORD e_minalloc;
WORD e_maxalloc;
WORD e_ss;
WORD e_sp;
WORD e_csum;
WORD e_ip;
WORD e_cs;
WORD e_lfarlc;
WORD e_ovno;
WORD e_res[4];
WORD e_oemid;
WORD e_oeminfo;
WORD e_res2[10];
DWORD e_lfanew; // offset of IMAGE_NT_HEADER
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
Det er følgende interessante felt for oss:
-
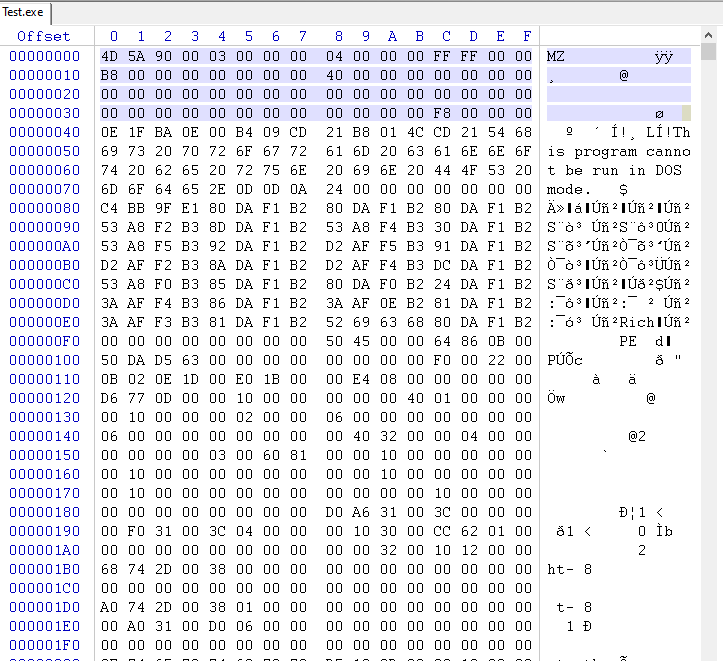
e_magic feltet brukes for å identifisere filen som en gyldig PE-fil. Som du kan se, er e_magic-feltet et 16-bit usignert heltall som spesifiserer "maginummeret" til filen. Maginummeret er en spesiell verdi som identifiserer filen som en gyldig PE-fil. Det er satt til verdien 0x5A4D (heksadesimal), som er ASCII-representasjonen av tegnene "MZ" (IMAGE_DOS_SIGNATURE).
-
e_lfanew feltet brukes for å spesifisere plasseringen av IMAGE_NT_HEADERS strukturen, som inneholder informasjon om utformingen og egenskapene til PE-filen. Som du kan se, er e_lfanew-feltet et 32-bit signert heltall som spesifiserer plasseringen av IMAGE_NT_HEADERS strukturen i filen. Det er vanligvis satt til forskyvningen av strukturen i forhold til begynnelsen av filen.
Historie
På begynnelsen av 1980-tallet jobbet Microsoft med et nytt operativsystem kalt MS-DOS, som var designet for å være et enkelt, lettvekt operativsystem for personlige datamaskiner. En av de nøkkel funksjonene til MS-DOS var dens evne til å kjøre eksekverbare filer, som er programmer som kan kjøres på en datamaskin.
For å gjøre det enkelt å identifisere kjørbare filer bestemte utviklerne av MS-DOS seg for å bruke et spesielt "magisk nummer" i begynnelsen av hver kjørbar fil. Dette magiske nummeret skulle brukes til å skille kjørbare filer fra andre typer filer, som datafiler eller konfigurasjonsfiler.
Mark Zbikowski, som var en utvikler på MS-DOS teamet, kom med ideen om å bruke bokstavene "MZ" som magisk nummer. I ASCII-koden er bokstaven "M" representert ved den heksadesimale verdien 0x4D, og bokstaven "Z" er representert ved den heksadesimale verdien 0x5A. Når disse verdiene kombineres, danner de det magiske nummeret 0x5A4D, som er ASCII-representasjonen av bokstavene "MZ".
I dag brukes fortsatt "MZ"-signaturen for å identifisere PE-filer, som er hovedformatet for kjørbare filer brukt på Windows-operativsystemet. Det lagres i e_magic-feltet til IMAGE_DOS_HEADER -strukturen, som er den første strukturen i en PE-fil.
IMAGE_NT_HEADER
IMAGE_NT_HEADER er en datastruktur som ble introdusert med Windows NT-operativsystemet, som ble utgitt i 1993. Den ble designet for å gi operativsystemet en standard måte å lese og tolke innholdet i kjørbare filer (PE filer) på.
Med lanseringen av Windows NT introduserte Microsoft IMAGE_NT_HEADER som en måte å standardisere layout og struktur på kjørbare filer. Dette gjorde det lettere for operativsystemet å laste og kjøre programmer, ettersom det bare måtte støtte ett enkelt format.
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_nt_headers32
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_nt_headers64
typedef struct _IMAGE_NT_HEADERS32
{
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
typedef struct _IMAGE_NT_HEADERS64
{
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER64 OptionalHeader;
} IMAGE_NT_HEADERS64, *PIMAGE_NT_HEADERS64;
IMAGE_NT_HEADER er en struktur som vises i begynnelsen av hver bærbar eksekverbar (PE) fil i Windows-operativsystemet. Den inneholder en rekke felter som gir operativsystemet viktig informasjon om den eksekverbare filen, slik som dens størrelse, utforming og tiltenkte formål.
IMAGE_NT_HEADER-strukturen er delt inn i to hovedseksjoner: IMAGE_FILE_HEADER og IMAGE_OPTIONAL_HEADER.

IMAGE_FILE_HEADER
IMAGE_FILE_HEADER inneholder informasjon om den kjørbare filen som helhet, inkludert maskintypen (f.eks. x86, x64), antall seksjoner i filen, og dato og tid for når filen ble opprettet.
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_file_header
typedef struct _IMAGE_FILE_HEADER
{
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
Strukturen har følgende felter:
-
Machine: Dette feltet angir målarkitekturen som filen ble bygget for. Verdien av dette feltet bestemmes av kompilatoren når filen er bygget. Noen vanlige verdier er:
-
IMAGE_FILE_MACHINE_I386: Filen er ment å kjøre på x86-arkitektur, også kjent som 32-bits.
-
IMAGE_FILE_MACHINE_AMD64: Filen er ment å kjøre på x64-arkitektur, også kjent som 64-bits.
-
IMAGE_FILE_MACHINE_ARM: Filen er ment å kjøre på ARM-arkitektur.
-
-
NumberOfSections: Dette feltet angir antall seksjoner i PE-filen. En PE-fil er delt inn i flere seksjoner, og hver seksjon inneholder forskjellige typer informasjon som kode, data og ressurser. Dette feltet brukes av operativsystemet for å bestemme hvor mange seksjoner som er til stede i filen.
-
TimeDateStamp: Dette feltet inneholder tidsstemplet for når filen ble bygget. Tidsstemplet er lagret som en 4-byte verdi som representerer antall sekunder siden 1. januar 1970, 00:00:00 UTC. Dette feltet kan brukes til å fastslå når filen sist ble bygget, noe som kan være nyttig for feilsøking eller versjonshåndtering.
-
PointerToSymbolTable: Dette feltet angir filoffseten til COFF (Common Object File Format) symboltabellen, hvis til stede. COFF-symboltabellen inneholder informasjon om symboler brukt i filen, slik som funksjonsnavn, variabelnavn og linjenumre. Dette feltet brukes kun til feilsøkingsformål og er vanligvis ikke til stede i slippversjoner.
-
NumberOfSymbols: Dette feltet angir antall symboler i COFF-symboltabellen, hvis til stede. Dette feltet brukes sammen med PointerToSymbolTable for å lokalisere COFF-symboltabellen i filen.
-
SizeOfOptionalHeader: Dette feltet angir størrelsen på den valgfrie overskriften, som inneholder tilleggsinformasjon om filen. Den valgfrie overskriften inneholder vanligvis informasjon om filens startpunkt, importerte biblioteker, og størrelsen på stakk og haug.
-
Characteristics: Dette feltet angir ulike egenskaper ved filen. Noen vanlige verdier er:
-
IMAGE_FILE_EXECUTABLE_IMAGE: Filen er en kjørbar fil.
-
IMAGE_FILE_DLL: Filen er et dynamisk lenkebibliotek (DLL).
-
IMAGE_FILE_32BIT_MACHINE: Filen er en 32-bits fil.
-
IMAGE_FILE_DEBUG_STRIPPED: Filen har blitt strippet for feilsøkingsinformasjon.
-
Disse feltene gir viktig informasjon om filen som brukes av operativsystemet når det laster filen inn i minnet og utfører den. Ved å forstå feltene i IMAGE_FILE_HEADER-strukturen, kan du få en dypere forståelse av hvordan PE-filer er strukturert og hvordan operativsystemet bruker dem.
De fleste av de mulige verdiene for hvert felt er erklært i header-filen WinNT.h
IMAGE_OPTIONAL_HEADER
Strukturen IMAGE_FILE_HEADER etterfølges av den valgfrie overskriften, som er beskrevet av strukturen IMAGE_OPTIONAL_HEADER. Den valgfrie overskriften inneholder tilleggsinformasjon om bildet, som adressen til inngangspunktet, størrelsen på bildet, og adressen til importkatalogen.
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_optional_header32
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_optional_header64
typedef struct _IMAGE_OPTIONAL_HEADER32
{
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
typedef struct _IMAGE_OPTIONAL_HEADER64
{
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
ULONGLONG ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
ULONGLONG SizeOfStackReserve;
ULONGLONG SizeOfStackCommit;
ULONGLONG SizeOfHeapReserve;
ULONGLONG SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER64, *PIMAGE_OPTIONAL_HEADER64;
Her er en detaljert beskrivelse av hvert felt i IMAGE_OPTIONAL_HEADER strukturen:
-
Magic: Dette feltet spesifiserer hvilken type valgfritt hode som er til stede i PE-filen. Den vanligste verdien er IMAGE_NT_OPTIONAL_HDR32_MAGIC for en 32-bits fil eller IMAGE_NT_OPTIONAL_HDR64_MAGIC for en 64-bits fil.
-
MajorLinkerVersion og MinorLinkerVersion: Disse feltene spesifiserer versjonen av lenkeren som ble brukt for å bygge filen. Lenkeren er et verktøy som brukes til å kombinere objektfiler og biblioteker til en enkelt utførbar fil.
-
SizeOfCode: Dette feltet spesifiserer størrelsen på kodeavsnittet i filen. Kodeavsnittet inneholder maskinkoden for den utførbare filen.
-
SizeOfInitializedData: Dette feltet spesifiserer størrelsen på avsnittet med initialiserte data i filen. Avsnittet med initialiserte data inneholder data som er initialisert ved kjøretid, slik som globale variabler.
-
SizeOfUninitializedData: Dette feltet spesifiserer størrelsen på avsnittet med uinitialiserte data i filen. Avsnittet med uinitialiserte data inneholder data som ikke er initialisert ved kjøretid, slik som bss-seksjonen.
-
AddressOfEntryPoint: Dette feltet spesifiserer den virtuelle adressen til programmets inngangspunkt. Inngangspunktet er startadressen til programmet og er den første instruksjonen som utføres når filen lastes inn i minnet.
-
BaseOfCode: Dette feltet spesifiserer den virtuelle adressen til begynnelsen av kodeavsnittet.
-
ImageBase: Dette feltet spesifiserer den foretrukne virtuelle adressen der filen bør lastes inn i minnet. Denne adressen brukes som en grunnadresse for alle virtuelle adresser i filen.
-
SectionAlignment: Dette feltet spesifiserer avsnittenes justering innenfor filen. Avsnittene i filen er vanligvis justert i flertall av denne verdien for å forbedre ytelsen.
-
FileAlignment: Dette feltet spesifiserer avsnittenes justering innenfor filen på disken. Avsnittene i filen er vanligvis justert i flertall av denne verdien for å forbedre diskens ytelse.
-
MajorOperatingSystemVersion og MinorOperatingSystemVersion: Disse feltene spesifiserer den minste nødvendige versjonen av operativsystemet som trengs for å kjøre filen.
-
MajorImageVersion og MinorImageVersion: Disse feltene spesifiserer versjonen av bildet. Bildeversjonen brukes til å identifisere filens versjon for versjonsstyringsformål.
-
MajorSubsystemVersion og MinorSubsystemVersion: Disse feltene spesifiserer versjonen av subsystemet som kreves for å kjøre filen. Subsystemet er miljøet hvor filen kjører, slik som Windows Console eller Windows GUI.
-
Win32VersionValue: Dette feltet er reservert og vanligvis satt til 0.
-
SizeOfImage: Dette feltet spesifiserer størrelsen på bildet, i byte, når det er lastet inn i minnet.
-
SizeOfHeaders: Dette feltet spesifiserer størrelsen på topptekstene, i byte. Topptekstene inkluderer IMAGE_FILE_HEADER og IMAGE_OPTIONAL_HEADER.
-
CheckSum: Dette feltet brukes til å sjekke filens integritet. Sjekksummen beregnes ved å summere innholdet i filen og lagre resultatet i dette feltet. Sjekksummen brukes til å oppdage endringer i filen som kan oppstå på grunn av manipulering eller korrupsjon.
-
Subsystem: Dette feltet spesifiserer subsystemet som er nødvendig for å kjøre filen. De mulige verdiene inkluderer IMAGE_SUBSYSTEM_NATIVE, IMAGE_SUBSYSTEM_WINDOWS_GUI, IMAGE_SUBSYSTEM_WINDOWS_CUI, IMAGE_SUBSYSTEM_OS2_CUI osv.
-
DllCharacteristics: Dette feltet spesifiserer kjennetegn ved filen, som om den er et dynamisk-lenkebibliotek (DLL) eller om den kan flyttes ved lasting. De mulige verdiene inkluderer IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASE, IMAGE_DLLCHARACTERISTICS_NX_COMPAT osv.
-
SizeOfStackReserve: Dette feltet spesifiserer størrelsen på stakken, i byte, som er reservert for programmet. Stakken brukes til å lagre midlertidige data, slik som funksjonskallinformasjon.
-
SizeOfStackCommit: Dette feltet spesifiserer størrelsen på stakken, i byte, som er forpliktet for programmet. Den forpliktede stakken er delen av stakken som faktisk er reservert i minnet.
-
SizeOfHeapReserve: Dette feltet spesifiserer størrelsen på haugen, i byte, som er reservert for programmet. Haugen brukes til å allokere minne dynamisk ved kjøretid.
-
SizeOfHeapCommit: Dette feltet spesifiserer størrelsen på haugen, i byte, som er forpliktet for programmet. Den forpliktede haugen er delen av haugen som faktisk er reservert i minnet.
-
LoaderFlags: Dette feltet er reservert og vanligvis satt til 0.
-
NumberOfRvaAndSizes: Dette feltet spesifiserer antall datakatalogoppføringer i IMAGE_OPTIONAL_HEADER. Datakatalogene inneholder informasjon om import, eksport, ressurser, osv. i filen.
-
DataDirectory: Dette feltet er et array av IMAGE_DATA_DIRECTORY-strukturer som spesifiserer plasseringen og størrelsen på datakatalogene i filen.
IMAGE_SECTION_HEADER
En seksjon, i sammenheng med en PE (Portable Executable)-fil, er en sammenhengende blokk med minne i filen som holder en spesifikk type data eller kode. I en PE-fil brukes seksjoner til å organisere og lagre forskjellige deler av filen, som kode, data, ressurser osv.
Hver seksjon i en PE-fil har et unikt navn og beskrives av en IMAGE_SECTION_HEADER-struktur, som inneholder informasjon om seksjonen som dens størrelse, plassering, egenskaper og så videre. Følgende er feltene til IMAGE_SECTION_HEADER:
En IMAGE_SECTION_HEADER er en datastruktur brukt i Portable Executable (PE) filformatet, som benyttes på Windows operativsystemet for å definere oppsettet av en fil i minnet. PE filformatet brukes for kjørbare filer, DLLs, og andre typer filer som lastes inn i minnet av Windows operativsystemet. Hver seksjonshode beskriver en sammenhengende blokk av data innenfor filen, og inkluderer informasjon som navnet på seksjonen, den virtuelle minneadressen der seksjonen skal lastes, og størrelsen på seksjonen. Seksjonshodene kan brukes til å lokalisere og få tilgang til spesifikke deler av filen, som kode- eller dataseksjonene.
IMAGE_SECTION_HEADER-strukturen er definert i Windows Platform SDK, og kan finnes i winnt.h-headerfilen. Her er et eksempel på hvordan strukturen er definert i C++:
#pragma pack(push, 1)
typedef struct _IMAGE_SECTION_HEADER
{
BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; // 8
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
#pragma pack(pop)
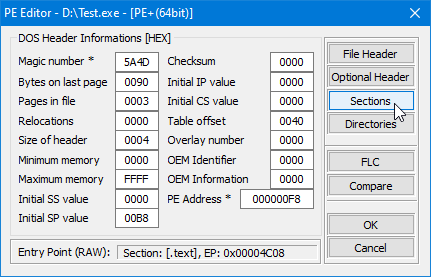
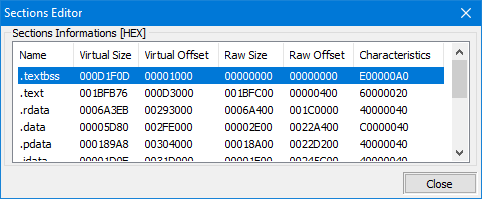
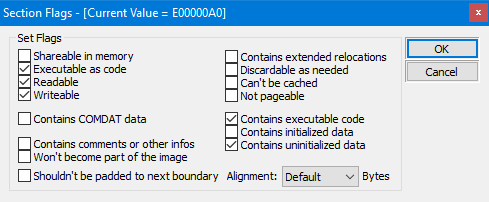
Som du kan se, er strukturen definert som en C++ struct og den inneholder felt for seksjonens navn, virtuell størrelse, virtuell adresse, størrelse på rådata, og peker til rådata, relokasjoner, linjenummer, og antall relokasjoner og linjenummer. I tillegg inneholder Characteristics-feltet flagg som beskriver egenskapene til seksjonen, slik som om den er kjørbar, lesbar eller skrivbar.
-
Name: Denne 8-byte arrayen brukes for å spesifisere navnet på seksjonen. Navnet kan være hvilken som helst null-terminert streng, men det brukes typisk til å gi meningsfulle navn til ulike deler av filen, for eksempel ".text" for kjørbar kode, ".data" for initialiserte data, ".rdata" for skrivebeskyttede data, og ".bss" for uinitialiserte data. Navnet på seksjonen brukes av operativsystemet for å lokalisere seksjonen innenfor filen, og brukes også av feilsøkere og andre verktøy for å identifisere seksjonen og dens innhold.
-
VirtualSize: Dette feltet spesifiserer størrelsen på seksjonen i minne, i bytes. Denne verdien representerer mengden minne som seksjonen vil okkupere i minne når filen er lastet inn i minnet. Den virtuelle størrelsen på seksjonen brukes av operativsystemet for å bestemme mengden minne som må allokering til seksjonen når filen er lastet inn i minnet.
-
VirtualAddress: Dette feltet spesifiserer startadressen til seksjonen i minne, i bytes. Denne verdien er startadressen hvor seksjonen vil bli lastet inn i minne og brukes av operativsystemet for å bestemme plasseringen i minne hvor seksjonen vil bli lastet. Den virtuelle adressen til seksjonen brukes også av operativsystemet for å løse adresser innenfor seksjonen slik at de kan oversettes korrekt til minneadresser når filen er lastet inn i minnet.
-
SizeOfRawData: Dette feltet spesifiserer størrelsen på seksjonen i filen, i bytes. Denne verdien representerer mengden plass i filen som seksjonen vil okkupere, og brukes av operativsystemet for å bestemme størrelsen på seksjonen i filen. Størrelsen på rådataene til en seksjon brukes av operativsystemet for å lokalisere seksjonen i filen, og for å bestemme størrelsen på seksjonen når den er lastet inn i minnet.
-
PointerToRawData: Dette feltet spesifiserer forskyvningen til seksjonen i filen, i bytes. Denne verdien representerer plasseringen av seksjonen i filen og brukes til å bestemme hvor dataene for seksjonen kan bli funnet. Pekeren til rådataene til en seksjon brukes av operativsystemet for å lokalisere seksjonen i filen, og for å bestemme plasseringen av seksjonen når den er lastet inn i minnet.
-
PointerToRelocations: Dette feltet spesifiserer forskyvningen til flytteinformasjonen for seksjonen, i bytes. Flytteinformasjonen brukes til å justere adresser innenfor seksjonen, slik at de kan bli korrekt løst når filen er lastet i minnet. Pekeren til relokasjonene til en seksjon brukes av operativsystemet for å lokalisere flytteinformasjonen for seksjonen samt bestemme hvordan adresser innen seksjonen når filen er lastet inn i minnet.
-
PointerToLinenumbers: Dette feltet spesifiserer forskyvningen til linjenummerinformasjon for seksjonen, i bytes. Linjenummerinformasjonen brukes til feilsøkning og gir informasjon om kildkoden som genererte seksjonen. Pekeren til linjenumrene til en seksjon brukes av feilsøkere og andre verkتy for å identifisere kildkoden sом gеnеrеrtе seksjonеn og for å gi mer detaljert informasjon om innholdet i seksjonen.
-
NumberOfRelocations: Dette feltet spesifiserer antallet flytteoppføringer for seksjonen. En flytteoppføring er en post som beskriver hvordan en adresse innen seksjonen skal justeres, slik at den kan bli korrekt løst__("Resolved") når filen blir lastet i minnet. Antallet relokasjoner til en seksjon brukes av operativsystemet for å bestemme størrelsen på flytteinformasjonen for seksjonen, og for å vite hvor mange flytteoppføringer som må behandles når filen lastes inn i minnet.
-
NumberOfLinenumbers: Dette feltet spesifiserer antallet linjenummerdata for seksjonen. En linjenummerdata er en post som gir informasjon om kilden sом har generert seksjonen og brukes til feilsøkning. Antallet linjenummer til en seksjon brukes av feilsøkere og andre verkتy for å bestemme størrelsen på linjenummerinformasjonen for seksjonen, og for å vite hvor mange linjenummerinnlegg som må behandles for å få informasjon om kildkoden som genererte seksjonen.
-
Characteristics: Dette feltet er et sett med flagg som spesifiserer atributter
Disse feltene brukes av operativsystemet og andre programmer for å håndtere filens minneoppsett, og for å lokalisere og få tilgang til spesifikke deler av filen, som kode- eller dataseksjonene.
VIKTIG: I sammenheng med IMAGE_NT_HEADER -strukturen, som brukes i Portable Executable (PE) filformatet, refererer VirtualAddress- og PhysicalAddress-feltene til forskjellige ting.
VirtualAddress-feltet brukes til å spesifisere den virtuelle adressen der seksjonen som inneholder IMAGE_NT_HEADER-strukturen lastes inn i minnet ved kjøretid. Denne adressen er relativ til basadressen til prosessen og brukes av programmet for å få tilgang til seksjonens data.
PhysicalAddress-feltet brukes til å spesifisere filforskyvningen til seksjonen som inneholder IMAGE_NT_HEADER-strukturen i PE-filen. Det brukes av operativsystemet for å lokalisere seksjonens data i filen når den lastes inn i minnet.
Alle overskriftsfeltene og forskyvningene for IMAGE_NT_HEADER er definert for minnet og opererer på virtuelle adresser. Hvis du trenger å forskyve et felt på disken, må du konvertere den virtuelle adressen til en fysisk adresse ved å bruke rva2offset funksjonen i koden nedenfor.
Oppsummert brukes VirtualAddress av programmet for å få tilgang til seksjonen i minnet, og PhysicalAddress brukes av operativsystemet for å lokalisere seksjonen i filen.

IMPORT
Når et program kompileres, genererer kompilatoren objektfiler som inneholder maskinkode for programmets funksjoner. Objektfilene har imidlertid kanskje ikke all informasjonen som kreves for at programmet skal kjøre. For eksempel kan objektfilene inneholde kall til funksjoner som ikke er definert i programmet, men som i stedet blir tilbudt av eksterne biblioteker.
Dette er hvor importtabellen kommer inn. Importtabellen lister de eksterne avhengighetene til programmet og funksjonene som programmet trenger å importere fra disse avhengighetene. Den dynamiske kobleren bruker denne informasjonen under kjøretid for å løse adressene til de importerte funksjonene og koble dem inn i programmet.
For eksempel, vurder et program som bruker funksjoner fra Windows-operativsystemet. Programmet kan inneholde kall til MessageBox-funksjonen fra user32.dll-biblioteket, som viser en meldingsboks på skjermen. For å løse adressen til MessageBox-funksjonen, må programmet inkludere en import for user32.dll i sin importtabell.
På samme måte, hvis et program trenger å bruke funksjoner fra et tredjepartsbibliotek, må det inkludere en import for det biblioteket i sin importtabell. For eksempel, et program som bruker funksjoner fra OpenSSL-biblioteket ville inkludere en import for libssl.dll-biblioteket i sin importtabell.
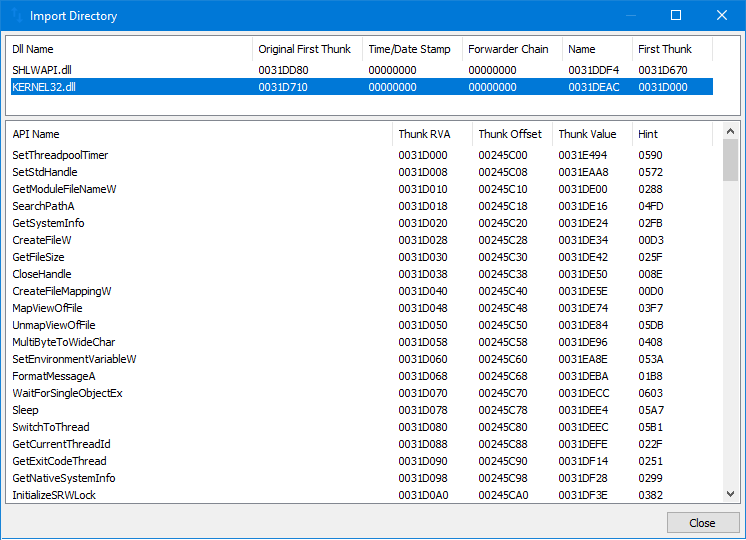
IMAGE_IMPORT_DIRECTORY
IMAGE_IMPORT_DIRECTORY er en datastruktur som brukes av Windows-operativsystemet for å importere funksjoner og data fra dynamiske lenkebiblioteker (DLL-er) til en portabel kjørbar (PE) fil. Den er en del av IMAGE_DATA_DIRECTORY, som er en tabell av datastrukturer som er lagret i IMAGE_OPTIONAL_HEADER av en PE-fil.
IMAGE_IMPORT_DIRECTORY brukes av Windows-lasteren for å løse de importerte funksjonene og dataene som brukes av PE-filen. Dette gjøres ved å kartlegge adressene til de importerte funksjonene og dataene til adressene til de tilsvarende funksjonene og dataene i DLL-ene. Dette lar PE-filen bruke funksjonene og dataene fra DLL-ene som om de var en del av selve PE-filen.
IMAGE_IMPORT_DIRECTORY består av en serie med IMAGE_IMPORT_DESCRIPTOR strukturer, hvor hver av dem beskriver en enkelt DLL som importeres av PE-filen. Hver IMAGE_IMPORT_DESCRIPTOR struktur inneholder følgende felt:
-
OriginalFirstThunk: en peker til en tabell over importerte funksjoner.
-
TimeDateStamp: datoen og tiden da DLL-en sist ble oppdatert.
-
ForwarderChain: en kjede av videresendte importerte funksjoner.
-
Name: navnet på DLL-en som en null-terminert streng.
-
FirstThunk: en peker til en tabell over importerte funksjoner som er bundet til DLL-en.
typedef struct _IMAGE_IMPORT_DESCRIPTOR
{
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date ime stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name;
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;
OriginalFirstThunk tabellen (eller FirstThunk hvis OriginalFirstThunk er 0)
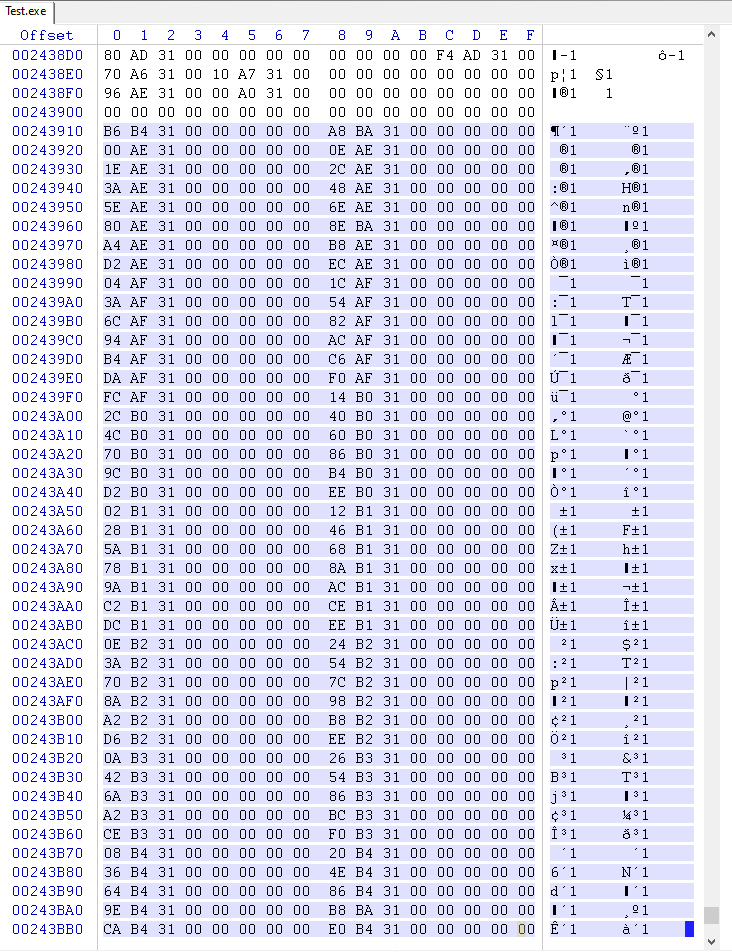
Strenger pekt på av tabell med forskyvninger (OriginalFirstThunk-tabellen eller FirstThunk hvis OriginalFirstThunk er 0)

HVORDAN FUNGERER DET?
Importmekanismen implementert av Microsoft er kompakt og vakker!
Adressene til alle funksjoner fra tredjepartsbiblioteker (inkludert Windows-systembiblioteker) som applikasjonen bruker, lagres i en spesiell tabell - importtabellen. Denne tabellen fylles når modulen lastes inn (vi snakker om andre mekanismer for å fylle import senere).
Videre, hver gang en funksjon blir kalt fra et tredjepartsbibliotek, genererer kompilatoren vanligvis følgende kode:
call dword ptr [__cell_with_address_of_function] // for x86 architecture
call qword ptr [__cell_with_address_of_function] // for x64 architecture
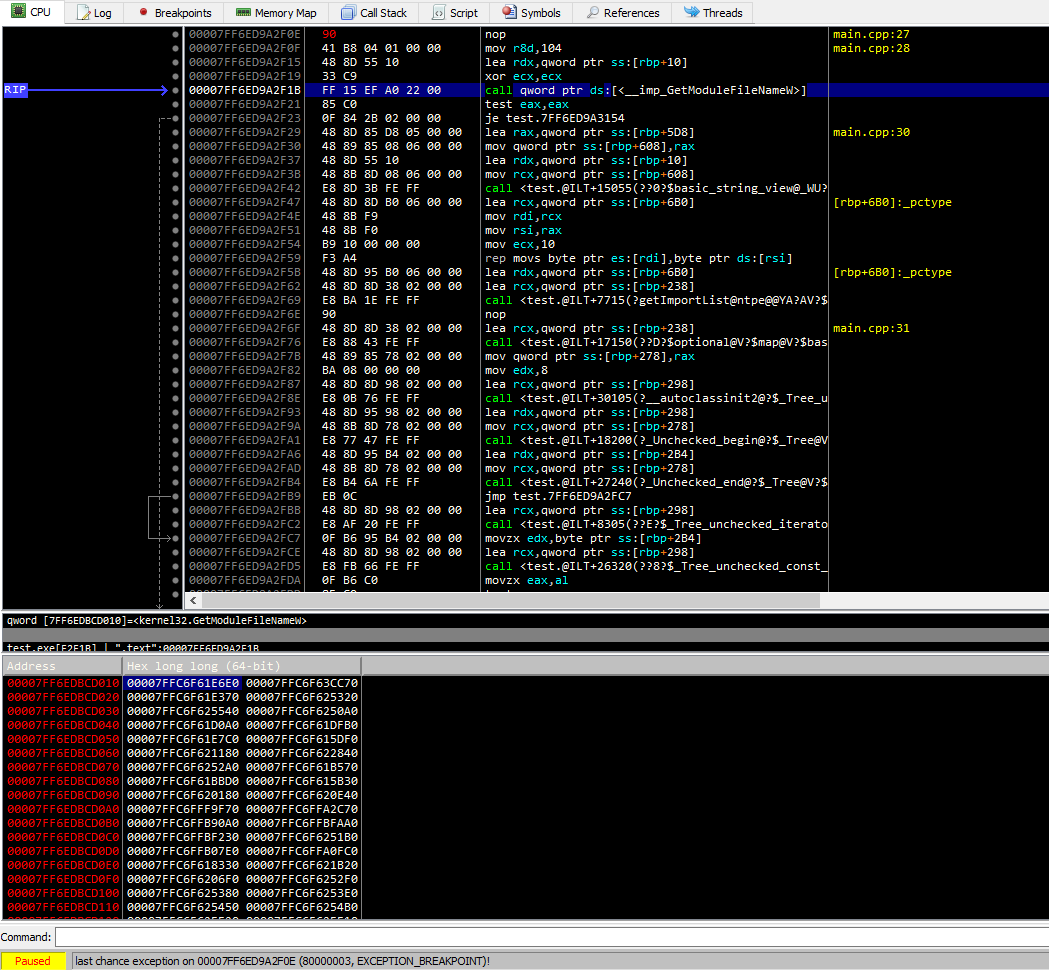
Dermed, for å kunne kalle en funksjon fra et bibliotek, trenger systemlasteren bare å skrive adressen til denne funksjonen én gang på ett sted i bildet.
C++ PARSER
Og nå skal vi skrive den enkleste parseren (kompatibel med x86 og x64) for importtabellen til den kjørbare filen!
#include "stdafx.h"
/*
*
* Copyright (C) 2022, SToFU Systems S.L.
* All rights reserved.
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation; either version 2 of the License, or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License along
* with this program; if not, write to the Free Software Foundation, Inc.,
* 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
*
*/
namespace ntpe
{
static constexpr uint64_t g_kRvaError = -1;
// These types is defined in NTPEParser.h
// typedef std::map< std::string, std::set< std::string >> IMPORT_LIST;
// typedef std::vector< IMAGE_SECTION_HEADER > SECTIONS_LIST;
//**********************************************************************************
// FUNCTION: alignUp(DWORD value, DWORD align)
//
// ARGS:
// DWORD value - value to align.
// DWORD align - alignment.
//
// DESCRIPTION:
// Aligns argument value with the given alignment.
//
// Documentation links:
// Alignment: https://learn.microsoft.com/en-us/cpp/cpp/alignment-cpp-declarations?view=msvc-170
//
// RETURN VALUE:
// DWORD aligned value.
//
//**********************************************************************************
DWORD alignUp(DWORD value, DWORD align)
{
DWORD mod = value % align;
return value + (mod ? (align - mod) : 0);
};
//**********************************************************************************
// FUNCTION: rva2offset(IMAGE_NTPE_DATA& ntpe, DWORD rva)
//
// ARGS:
// IMAGE_NTPE_DATA& ntpe - data from PE file.
// DWORD rva - relative virtual address.
//
// DESCRIPTION:
// Parse RVA (relative virtual address) to offset.
//
// RETURN VALUE:
// int64_t offset.
// g_kRvaError (-1) in case of error.
//
//**********************************************************************************
int64_t rva2offset(IMAGE_NTPE_DATA& ntpe, DWORD rva)
{
/* retrieve first section */
try
{
/* if rva is inside MZ header */
PIMAGE_SECTION_HEADER sec = ntpe.sectionDirectories;
if (!ntpe.fileHeader->NumberOfSections || rva < sec->VirtualAddress)
return rva;
/* walk on sections */
for (uint32_t sectionIndex = 0; sectionIndex < ntpe.fileHeader->NumberOfSections; sectionIndex++, sec++)
{
/* count section end and allign it after each iteration */
DWORD secEnd = ntpe::alignUp(sec->Misc.VirtualSize, ntpe.SecAlign) + sec->VirtualAddress;
if (sec->VirtualAddress <= rva && secEnd > rva)
return rva - sec->VirtualAddress + sec->PointerToRawData;
};
}
catch (std::exception&)
{
}
return g_kRvaError;
};
//**********************************************************************************
// FUNCTION: getNTPEData(char* fileMapBase)
//
// ARGS:
// char* fileMapBase - the starting address of the mapped file.
//
// DESCRIPTION:
// Parses following data from mapped PE file.
//
// Documentation links:
// PE format structure: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format
//
// RETURN VALUE:
// std::optional< IMAGE_NTPE_DATA >.
// std::nullopt in case of error.
//
//**********************************************************************************
#define initNTPE(HeaderType, cellSize) \
{ \
char* ntstdHeader = (char*)fileHeader + sizeof(IMAGE_FILE_HEADER); \
HeaderType* optHeader = (HeaderType*)ntstdHeader; \
data.sectionDirectories = (PIMAGE_SECTION_HEADER)(ntstdHeader + sizeof(HeaderType)); \
data.SecAlign = optHeader->SectionAlignment; \
data.dataDirectories = optHeader->DataDirectory; \
data.CellSize = cellSize; \
}
std::optional< IMAGE_NTPE_DATA > getNTPEData(char* fileMapBase, uint64_t fileSize)
{
try
{
/* PIMAGE_DOS_HEADER from starting address of the mapped view*/
PIMAGE_DOS_HEADER dosHeader = (IMAGE_DOS_HEADER*)fileMapBase;
/* return std::nullopt in case of no IMAGE_DOS_SIGNATUR signature */
if (dosHeader->e_magic != IMAGE_DOS_SIGNATURE)
return std::nullopt;
/* PE signature adress from base address + offset of the PE header relative to the beginning of the file */
PDWORD peSignature = (PDWORD)(fileMapBase + dosHeader->e_lfanew);
if ((char*)peSignature <= fileMapBase || (char*)peSignature - fileMapBase >= fileSize)
return std::nullopt;
/* return std::nullopt in case of no PE signature */
if (*peSignature != IMAGE_NT_SIGNATURE)
return std::nullopt;
/* file header address from PE signature address */
PIMAGE_FILE_HEADER fileHeader = (PIMAGE_FILE_HEADER)(peSignature + 1);
if (fileHeader->Machine != IMAGE_FILE_MACHINE_I386 &&
fileHeader->Machine != IMAGE_FILE_MACHINE_AMD64)
return std::nullopt;
/* result IMAGE_NTPE_DATA structure with info from PE file */
IMAGE_NTPE_DATA data = {};
/* base address and File header address assignment */
data.fileBase = fileMapBase;
data.fileHeader = fileHeader;
/* addresses of PIMAGE_SECTION_HEADER, PIMAGE_DATA_DIRECTORIES, SectionAlignment, CellSize depending on processor architecture */
switch (fileHeader->Machine)
{
case IMAGE_FILE_MACHINE_I386:
initNTPE(IMAGE_OPTIONAL_HEADER32, 4);
return data;
case IMAGE_FILE_MACHINE_AMD64:
initNTPE(IMAGE_OPTIONAL_HEADER64, 8);
return data;
}
}
catch (std::exception&)
{
}
return std::nullopt;
}
//**********************************************************************************
// FUNCTION: getImportList(IMAGE_NTPE_DATA& ntpe)
//
// ARGS:
// IMAGE_NTPE_DATA& ntpe - data from PE file.
//
// DESCRIPTION:
// Retrieves IMPORT_LIST(std::map< std::string, std::set< std::string >>) with all loaded into PE libraries names and imported functions.
// Map key: loaded dll's names.
// Map value: set of imported functions names.
//
// Documentation links:
// Import Directory Table: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#import-directory-table
//
// RETURN VALUE:
// std::optional< IMPORT_LIST >.
// std::nullopt in case of error.
//
//**********************************************************************************
std::optional< IMPORT_LIST > getImportList(IMAGE_NTPE_DATA& ntpe)
{
try
{
/* if no imaage import directory in file returns std::nullopt */
if (ntpe.dataDirectories[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress == 0)
return std::nullopt;
IMPORT_LIST result;
/* import table offset */
DWORD impOffset = rva2offset(ntpe, ntpe.dataDirectories[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress);
/* imoprt table descriptor from import table offset + file base adress */
PIMAGE_IMPORT_DESCRIPTOR impTable = (PIMAGE_IMPORT_DESCRIPTOR)(impOffset + ntpe.fileBase);
/* while names in import table */
while (impTable->Name != 0)
{
/* pointer to DLL name from offset of current section name + file base adress */
std::string modname = rva2offset(ntpe, impTable->Name) + ntpe.fileBase;
std::transform(modname.begin(), modname.end(), modname.begin(), ::toupper);
/* start adress of names in look up table from import table name RVA */
char* cell = ntpe.fileBase + ((impTable->OriginalFirstThunk) ? rva2offset(ntpe, impTable->OriginalFirstThunk) : rva2offset(ntpe, impTable->FirstThunk));
/* while names in look up table */
for (;; cell += ntpe.CellSize)
{
int64_t rva = 0;
/* break if rva = 0 */
memcpy(&rva, cell, ntpe.CellSize);
if (!rva)
break;
/* if rva > 0 function was imported by name. if rva < 0 function was imported by ordinall */
if (rva > 0)
result[modname].emplace(ntpe.fileBase + rva2offset(ntpe, rva) + 2);
else
result[modname].emplace(std::string("#ord: ") + std::to_string(rva & 0xFFFF));
};
impTable++;
};
return result;
}
catch (std::exception&)
{
return std::nullopt;
}
};
//**********************************************************************************
// FUNCTION: getImportList(IMAGE_NTPE_DATA& ntpe)
//
// ARGS:
// std::wstring_view filePath - path to file.
//
// DESCRIPTION:
// Retrieves IMPORT_LIST(std::map< std::string, std::set< std::string >>) with all loaded into PE libraries names and imported functions bu path.
// Map key: loaded dll's names.
// Map value: set of imported functions names.
//
// Documentation links:
// Import Directory Table: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#import-directory-table
//
// RETURN VALUE:
// std::optional< IMPORT_LIST >.
// std::nullopt in case of error.
//
//**********************************************************************************
std::optional< IMPORT_LIST > getImportList(std::wstring_view filePath)
{
std::vector< char > buffer;
/* obtain base address of mapped file from tools::readFile function */
bool result = tools::readFile(filePath, buffer);
/* return nullopt if readFile failes or obtained buffer is empty */
if (!result || buffer.empty())
return std::nullopt;
/* get IMAGE_NTPE_DATA from base address of mapped file */
std::optional< IMAGE_NTPE_DATA > ntpe = getNTPEData(buffer.data(), buffer.size());
if (!ntpe)
return std::nullopt;
/* return result of overloaded getImportList function with IMAGE_NTPE_DATA as argument */
return getImportList(*ntpe);
}
//**********************************************************************************
// FUNCTION: getSectionsList(IMAGE_NTPE_DATA& ntpe)
//
// ARGS:
// IMAGE_NTPE_DATA& ntpe - data from PE file.
//
// DESCRIPTION:
// Retrieves SECTIONS_LIST from IMAGE_NTPE_DATA.
// SECTIONS_LIST - vector of sections headers from portable executable file.
// Sections names exmaple: .data, .code, .src
//
// Documentation links:
// IMAGE_SECTION_HEADER: https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_section_header
// Section Table (Section Headers): https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#section-table-section-headers
//
// RETURN VALUE:
// std::optional< SECTIONS_LIST >.
// std::nullopt in case of error.
//
//**********************************************************************************
std::optional< SECTIONS_LIST > getSectionsList(IMAGE_NTPE_DATA& ntpe)
{
try
{
/* result vector of section directories */
SECTIONS_LIST result;
/* iterations through all image section headers poiners in IMAGE_NTPE_DATA structure */
for (uint64_t sectionIndex = 0; sectionIndex < ntpe.fileHeader->NumberOfSections; sectionIndex++)
{
/* pushing IMAGE_SECTION_HEADER from iamge section headers */
result.push_back(ntpe.sectionDirectories[sectionIndex]);
}
return result;
}
catch (std::exception&)
{
}
/* returns nullopt in case of error */
return std::nullopt;
}
}
Du kan finne koden til hele prosjektet på vår github:
https://github.com/SToFU-Systems/DSAVE
Liste over brukte verktøy
- PE Tools: https://github.com/petoolse/petools Dette er et åpen kildekode-verktøy for manipulering av PE-headerfelt. Støtter x86 og x64 filer.
- WinDbg: https://learn.microsoft.com/en-us/windows-hardware/drivers/debugger/debugger-download-tools Microsofts system-debugger. Uunnværlig i arbeidet til en systemprogrammerer for Windows OS.
- x64Dbg: https://x64dbg.com Enkel, lettvekts åpen kildekode x64/x86 debugger for Windows.
- WinHex: http://www.winhex.com/winhex/hex-editor.html WinHex er en universell hex-redaktør, spesielt nyttig innen datateknisk etterforskning, datarekonstruksjon, redigering av data på lavt nivå.
HVA ER NESTE?
Vi setter pris på din støtte og ser frem til din fortsatte deltakelse i vårt fellesskap
I neste artikkel vil vi sammen med deg skrive fuzzy hashing-modulen og ta for oss spørsmålet om svarte og hvite lister. Enkleste importtabellanalysator.
Eventuelle spørsmål til forfatterne av artikkelen kan sendes til e-post: articles@stofu.io
Takk for oppmerksomheten og ha en fin dag!




