Hash
Zunächst einmal gehen wir die Grundlagen durch und machen uns mit einem Konzept wie Hash vertraut!
Hash-Algorithmus - ist eine mathematische Funktion, die Daten beliebiger Größe aufnimmt und eine Ausgabe namens Hash oder Nachrichten-Hash erzeugt. Die Ausgabe ist eine einzigartige Darstellung der Eingabedaten, die verwendet werden kann, um zu überprüfen, ob die Daten nicht manipuliert wurden. Hash-Algorithmen werden verwendet, um die Integrität und Authentizität von Daten zu gewährleisten. Einfach ausgedrückt, ist ein Hash ein einzigartiger digitaler Fingerabdruck eines Datenstücks. Es ist wie ein Code, der die Daten repräsentiert. Der Code wird von einer mathematischen Funktion erzeugt, die als Hash-Funktion bezeichnet wird. Wenn sich die Daten auch nur ein wenig ändern, wird der Hash anders sein.
Es gibt primäre Schlüsselmerkmale für Hash:
-
Deterministisch: Eine Hash-Funktion sollte immer das gleiche Ergebnis für eine gegebene Eingabe liefern. Das bedeutet, dass du, wenn du die gleichen Daten zweimal hashst, beide Male denselben Hash-Wert erhalten solltest.
-
Irreversibilität: Es sollte rechnerisch nicht machbar sein, die ursprünglichen Eingabedaten aus ihrem Hash-Wert zu rekonstruieren. Diese Eigenschaft ist wichtig für die Sicherheit, da sie die Originaldaten vor Entdeckung durch Angreifer schützt, die nur Zugang zum Hash-Wert haben.
-
Uniformität: Eine Hash-Funktion sollte eine gleichmäßige Verteilung von Hash-Werten über alle möglichen Eingaben hinweg erzeugen. Das bedeutet, dass jeder Hash-Wert gleich wahrscheinlich auftreten sollte und es keine Muster oder Verzerrungen in der Verteilung der Hash-Werte geben sollte.
-
Unvorhersehbarkeit: Es sollte rechnerisch nicht machbar sein, den Hash-Wert einer Eingabe auf der Grundlage der Hash-Werte anderer Eingaben oder der Eigenschaften der Hash-Funktion selbst vorherzusagen. Diese Eigenschaft ist wichtig für die Sicherheit, da sie es Angreifern erschwert, Kollisionen zu erzeugen (zwei verschiedene Eingaben, die denselben Hash-Wert produzieren).
-
Irreversibilität: Es sollte rechnerisch nicht machbar sein, die ursprünglichen Eingabedaten aus ihrem Hash-Wert zu rekonstruieren. Diese Eigenschaft ist wichtig für die Sicherheit, da sie die Originaldaten vor Entdeckung durch Angreifer schützt, die nur Zugang zum Hash-Wert haben.
-
Widerstandsfähigkeit gegen Kollisionsangriffe: Eine Hash-Funktion sollte widerstandsfähig gegen Kollisionsangriffe sein, die darin bestehen, zwei unterschiedliche Eingaben zu finden, die denselben Hash-Wert erzeugen. Kollisionsangriffe können verwendet werden, um gefälschte digitale Signaturen zu erstellen oder Zugangskontrollen zu umgehen, daher ist es wichtig, dass eine Hash-Funktion so gestaltet wird, dass sie ihnen widersteht.
Andere Merkmale von Hashes finden Sie auf der Wikipedia-Seite:
https://en.wikipedia.org/wiki/Hash_function
Datenüberprüfung. Schwarze Liste und Weiße Liste.
Im Kontext von Antivirensoftware werden Hash-Algorithmen verwendet, um Malware zu erkennen oder Falsch-Positiv-Meldungen auszuschließen. Antivirensoftware verwaltet eine Datenbank mit bekannten Malware-Hashes (blacklist) und vertrauenswürdigen Software-Hashes (whitelist). Wenn eine Datei gescannt wird, wird ihr Hash mit den Hashes in der Datenbank verglichen. Die am häufigsten verwendeten Hash-Algorithmen zur Datenüberprüfung sind MD5, SHA-1, SHA-256 und SHA-512.
Die Verwendung von Hashes in Antivirus-Blacklists und Whitelists hilft, den Scanvorgang zu beschleunigen, da das Antivirus-Programm nicht jede Datei detailliert analysieren muss, um festzustellen, ob sie bösartig ist oder nicht. Stattdessen kann es die Hash-Werte der Dateien mit denen auf der Blacklist/Whitelist vergleichen, um bekannte Bedrohungen oder vertrauenswürdige Apps schnell zu identifizieren.
Blacklist. Im Kontext der Cybersicherheit und Antivirus-Software ist eine schwarze Liste eine Liste von bekannten schädlichen Dateien oder Teilen dieser Dateien. Wenn ein Antivirus-Programm einen Computer oder ein Netzwerk scannt, vergleicht es die gefundenen Dateien und Entitäten mit der schwarzen Liste, um mögliche Bedrohungen zu identifizieren. Stimmt eine Datei oder Entität mit einem Eintrag auf der schwarzen Liste überein, ergreift das Antivirus-Programm Maßnahmen, um sie zu entfernen oder zu isolieren, damit sie keinen Schaden anrichten kann.
Obwohl Blacklists nützlich sein können, um bekannte Bedrohungen zu erkennen und zu verhindern, sind sie nicht immer wirksam beim Schutz gegen neue und unbekannte Bedrohungen. Angreifer können verschiedene Techniken verwenden, wie Verschleierung oder Polymorphismus, um den Code oder das Verhalten einer Datei oder Entität zu ändern, um der Erkennung durch Antivirenprogramme zu entgehen.
Daher verwenden Antivirenprogramme oft eine Kombination von Techniken, wie Whitelisting und verhaltensbasierte Erkennung, um die Verwendung von Blacklists zu ergänzen und einen umfassenderen Schutz gegen eine breitere Palette von Bedrohungen zu bieten.
Whitelist. Im Kontext der Cybersicherheit und Antivirus-Software ist eine Whitelist eine Liste von vertrauenswürdigen Dateien, die als sicher bekannt sind. Wenn eine Datei oder Entität mit einem Eintrag auf der Whitelist übereinstimmt, wird das Antivirus-Programm es öffnen/ausführen lassen, ohne Maßnahmen zu ergreifen, da es als sicher betrachtet wird.
Whitelists sind nützlich, um Falschmeldungen in Antiviren- und Sicherheitsprogrammen zu verhindern. Falschmeldungen treten auf, wenn ein Programm oder eine Datei fälschlicherweise als bösartig oder schädlich markiert wird, obwohl es eigentlich sicher ist. Durch die Verwendung einer Whitelist können Sicherheitsprogramme diese Falschmeldungen umgehen, was Zeit sparen und unnötige Alarme vermeiden kann.
Die Verwendung von Hashes und Blacklists/Whitelists kann eine effektive Methode sein, um sich gegen bekannte Bedrohungen zu schützen und Falschmeldungen in Antivirus- und Sicherheitsprogrammen zu verhindern.
Warum verwenden Antivirenprogramme mehrere Hash-Algorithmen?
Antivirenprogramme verwenden aus mehreren Gründen verschiedene Hash-Algorithmen:
-
Obwohl blacklists effektiv darin sein können, bekannte Bedrohungen zu erkennen und zu verhindern, sind sie nicht narrensicher. Angreifer können verschiedene Techniken verwenden, um die Erkennung zu umgehen, wie zum Beispiel die Modifikation der Daten, um eine Übereinstimmung mit den Signaturen in der blacklist zu vermeiden. Diese Techniken werden als „Kollisionsangriffe“ bezeichnet. Ein Kollisionsangriff ist eine Art kryptografischer Angriff, bei dem ein Angreifer versucht, zwei unterschiedliche Eingaben, wie Dateien oder Nachrichten, zu finden, die denselben Hashwert erzeugen, wenn sie durch eine Hashfunktion laufen (Kollision). Das Ziel eines Kollisionsangriffs besteht darin, ein Paar von Eingaben zu erstellen, das dazu verwendet werden kann, ein System zu untergraben, das auf die Integrität von Hashwerten angewiesen ist, wie digitale Signaturen, Passwortauthentifizierung oder Datenintegritätsprüfungen. Wenn ein Angreifer eine Kollision findet, kann er sie nutzen, um die Sicherheitsmaßnahmen zu umgehen, die auf der Hashfunktion beruhen. Um das Risiko von Kollisionsangriffen zu mindern, verwenden Antivirenprogramme starke Hashfunktionen, die widerstandsfähig gegen Angriffe sind, und setzen gleichzeitig mehrere Hashfunktionen ein. Zum Beispiel, wenn ein Antivirenprogramm nur den MD5-Hash-Algorithmus verwenden würde, könnte ein Angreifer potenziell eine bösartige Datei erstellen, die denselben MD5-Hash wie eine legitime Datei hat, und das Antivirenprogramm dazu bringen, die bösartige Datei als sicher zu behandeln. Die Verwendung mehrerer Hash-Algorithmen, wie MD5, SHA-1 und SHA-256, erschwert es jedoch einem Angreifer, einen Kollisionsangriff zu erstellen, der gleichzeitig gegen alle Algorithmen wirkt.
-
Effizienz: Verschiedene Hash-Algorithmen haben unterschiedliche rechnerische Anforderungen, und einige können je nach Dateigröße, Typ oder anderen Faktoren effizienter sein als andere. Die Verwendung mehrerer Hash-Algorithmen ermöglicht es Antivirenprogrammen, den am besten geeigneten Algorithmus für eine gegebene Situation auszuwählen, was Zeit und Rechenleistung sparen kann. Zum Beispiel kann SHA-256 rechnerisch intensiver sein als MD5, daher kann sich ein Antivirenprogramm entscheiden, MD5 für kleinere Dateien und SHA-256 für größere Dateien zu verwenden.
-
Flexibilität: Verschiedene Hash-Algorithmen sind für unterschiedliche Anwendungsfälle und Anwendungen konzipiert. Durch die Verwendung mehrerer Hash-Algorithmen können Antivirenprogramme sich an unterschiedliche Bedürfnisse und Szenarien anpassen, wie zum Beispiel das Erkennen von Malware, die Überprüfung der Dateiintegrität oder das Erkennen von Manipulationen oder Modifikationen. Zum Beispiel kann ein forensischer Ermittler einen anderen Hash-Algorithmus verwenden als ein Antivirenprogramm, um sicherzustellen, dass die Daten während einer Untersuchung nicht modifiziert wurden.
Die Verwendung mehrerer Hash-Algorithmen gilt als Best Practice in der Cybersicherheit und der Entwicklung von Antivirensoftware, da sie Robustheit, Kompatibilität, Effizienz und Flexibilität bei der Erkennung und Verhinderung von Cyberbedrohungen bietet.
Wie erkennen Antiviren ähnliche, aber nicht identische Daten und Dateien?
Ähnliche, aber nicht identische Dateien können in der Cybersicherheit ein Problem darstellen, da sie von Angreifern genutzt werden können, um die Erkennung durch Antivirensoftware zu umgehen.
Beispielsweise kann ein Angreifer eine bekannte Malware-Datei nehmen und leichte Änderungen an ihrem Code oder ihrer Struktur vornehmen, wie das Ändern von Variablennamen oder das Umordnen von Anweisungen. Diese Änderungen können ausreichen, um eine neue Datei zu erstellen, die ähnlich, aber nicht identisch mit der ursprünglichen Malware-Datei ist und die möglicherweise von Antivirensoftware, die auf traditionellen hash-basierten Erkennungsmethoden beruht, nicht erkannt wird.
Zusätzlich können Angreifer ähnliche, aber nicht identische Dateien verwenden, um polymorphe Malware zu erstellen, die ihren Code oder ihre Struktur bei jeder Infektion ändern kann, um einer Entdeckung zu entgehen. Polymorphe Malware kann mit traditionellen Antiviren-Techniken, die darauf angewiesen sind, spezifische Muster oder Signaturen im Malware-Code zu erkennen, sehr schwer zu entdecken sein.
Um dieses Problem zu lösen, verwenden Antivirenprogramme unscharfe Hashes.
Fuzzy-Hashing ist eine Technik, die von einigen Antivirenprogrammen verwendet wird, um ähnliche, aber nicht identische Dateien zu erkennen, einschließlich polymorpher Malware. Indem eine Datei in kleinere Teile zerlegt und die Hashes dieser Teile mit denen anderer Dateien verglichen werden, kann Fuzzy-Hashing Dateien identifizieren, die ähnlichen Code oder eine ähnliche Struktur aufweisen, auch wenn sie nicht identisch sind.
Fuzzy-Hashing funktioniert, indem es Sequenzen von Bytes identifiziert, die häufig in der Datei vorkommen. Diese Sequenzen, auch bekannt als "Chunks", werden dann mit einer kryptografischen Hashfunktion gehasht, um einen Hashwert zu erzeugen. Die Hashwerte der Chunks werden dann mit denen anderer Dateien verglichen, um ähnliche Chunks zu identifizieren.
Der Vorteil von Fuzzy-Hashing liegt darin, dass es Ähnlichkeiten erkennen kann, selbst wenn Dateien modifiziert oder verschleiert wurden, was es zu einem leistungsstarken Werkzeug macht, um Varianten bekannter Malware zu identifizieren. Zum Beispiel, wenn ein Angreifer eine bekannte Malware-Datei modifiziert, indem er die Namen von Variablen oder Funktionen ändert, können traditionelle hash-basierte Erkennungsmethoden die modifizierte Datei möglicherweise nicht erkennen. Fuzzy-Hashing kann jedoch die modifizierte Datei erkennen, indem es Abschnitte identifiziert, die denen der ursprünglichen Malware-Datei ähneln. Im Gegensatz zu kryptografischen Hash-Algorithmen wie MD5, SHA-1 oder SHA-512 erzeugen Fuzzy-Hash-Algorithmen variable Hash-Werte, die auf der Ähnlichkeit der Eingabedaten basieren.
Vorteile von unscharfen Hashes:
-
Erkennung ähnlicher Dateien: Mit Fuzzy-Hashes können ähnliche Dateien erkannt werden, selbst wenn sie leicht modifiziert wurden, was nützlich ist, um Varianten bekannter Malware zu identifizieren.
-
Reduzierung von Falschmeldungen: Fuzzy-Hashes können die Anzahl der Falschmeldungen, die durch traditionelle hash-basierte Erkennungsmethoden erzeugt werden, verringern. Dies liegt daran, dass Fuzzy-Hashes Dateien erkennen können, die ähnlich, aber nicht identisch mit bekannter Malware sind.
-
Resistenz gegen Verschleierung: Fuzzy-Hashes sind widerstandsfähiger gegenüber Verschleierungstechniken, die von Angreifern verwendet werden, um der Erkennung zu entgehen. Dies liegt daran, dass der Fuzzy-Hashing-Algorithmus die Datei in kleinere Teile bricht und für jeden Teil Hashes generiert, was es für einen Angreifer schwieriger macht, die Datei so zu modifizieren, dass sie der Erkennung entgeht.
Fuzzy-Hashing hat einige Einschränkungen, die seine Wirksamkeit bei der Erkennung von ähnlichen, aber nicht identischen Dateien beeinträchtigen können:
-
Falsch Positive: Fuzzy-Hashing kann falsch positive Ergebnisse liefern, bei denen legitime Dateien als bösartig gekennzeichnet werden, weil sie ähnlichen Code oder eine ähnliche Struktur wie bekannte Malware aufweisen. Dies kann vorkommen, wenn die Dateien gemeinsame Bibliotheken oder Frameworks nutzen.
-
Leistung: Fuzzy-Hashing kann rechenintensiv sein, insbesondere bei großen Dateien. Dies kann den Scanvorgang verlangsamen und die Systemleistung beeinträchtigen.
-
Größenbeschränkungen: Fuzzy-Hashing funktioniert möglicherweise nicht gut bei sehr kleinen Dateien oder Dateien mit niedriger Entropie, da es möglicherweise nicht genügend einzigartige Blöcke gibt, um aussagekräftige Hashes zu erzeugen.
-
Manipulation: Fuzzy-Hashing kann wirkungslos sein, wenn ein Angreifer es gezielt angreift und eine Datei so modifiziert, dass sie nicht erkannt wird. Ein Angreifer könnte beispielsweise die Struktur einer Datei absichtlich ändern, um ihre Identifizierung durch Fuzzy-Hashing zu verhindern.
Was ist der Unterschied zwischen kryptografischen Hash-Algorithmen und unscharfen Hash-Algorithmen?
Kryptografische Hash-Algorithmen und unscharfe Hash-Algorithmen werden beide in der Cybersicherheit verwendet, haben jedoch unterschiedliche Zwecke und Eigenschaften.
Kryptografische Hash-Algorithmen, wie SHA-256 und MD5, sind darauf ausgelegt, Datenintegrität und Authentizität zu gewährleisten, indem sie feste, einzigartige Hash-Werte erzeugen, die fast unmöglich zu rekonstruieren sind. Kryptografische Hash-Algorithmen werden verwendet, um die Integrität von Daten zu überprüfen.
Fuzzy-Hash-Algorithmen, wie SSDEEP, sind darauf ausgelegt, ähnliche, aber nicht identische Daten zu identifizieren, wie zum Beispiel Dateien, die von Malware-Autoren modifiziert oder neu verpackt wurden. Fuzzy-Hashing verwendet eine Schiebefenstertechnik, um Daten in kleine Blöcke zu unterteilen und variable, probabilistische Hashes zu erzeugen, die mit einer Datenbank bekannter Malware-Hashes verglichen werden, um potenziell bösartige Dateien zu identifizieren.
Kryptographische Hash-Algorithmen sind so konzipiert, dass sie kollisionsresistent sind, was bedeutet, dass es äußerst schwierig ist, zwei Eingaben zu finden, die denselben Hash-Wert erzeugen. Unscharfe Hash-Algorithmen müssen nicht kollisionsresistent sein, da sie darauf ausgelegt sind, Ähnlichkeiten zwischen Dateien zu erkennen, anstatt einzigartige Hash-Werte zu erzeugen
Der Hauptunterschied zwischen kryptografischen Hash-Algorithmen und unscharfen Hash-Algorithmen liegt in ihrem Determinismusgrad. Kryptografische Hash-Algorithmen erzeugen festlängige, deterministische Hashes, die für jede Eingabe einzigartig sind, während unscharfe Hash-Algorithmen variable Längen, probabilistische Hashes produzieren, die für ähnliche Eingaben ähnlich sind.
Welche Fuzzy-Hashing-Algorithmen werden wir in unserer Lösung verwenden?
In unserer Lösung werden wir SSDEEP und TLSH verwenden.
ssdeep ist ein Fuzzy-Hashing-Algorithmus, der zur Identifizierung ähnlicher, aber nicht identischer Daten verwendet wird, wie z.B. Malware-Varianten. Er funktioniert, indem er einen Hash-Wert erzeugt, der die Ähnlichkeit der Eingabedaten darstellt, anstatt eines einzigartigen Kennzeichners wie kryptografische Hash-Funktionen. Die Ausgabe von ssdeep ist variabel in der Länge und probabilistisch, was es ermöglicht, selbst geringfügige Unterschiede zwischen zwei Dateien zu erkennen. ssdeep wird häufig in der Malware-Analyse und -Erkennung verwendet und ist auch in verschiedene Sicherheitstools und Antivirensoftware integriert.
TLSH (Trend Micro Locality Sensitive Hash) ist ein Fuzzy-Hashing-Algorithmus, der verwendet wird, um ähnliche, aber nicht identische Daten zu identifizieren, wie zum Beispiel Malware-Varianten. Er funktioniert, indem er einen Hash-Wert erzeugt, der die einzigartigen Merkmale der Eingabedaten erfasst, wie Bytefrequenz und -reihenfolge. Die Ausgabe von TLSH ist variabel in der Länge und probabilistisch, was es ihm ermöglicht, Ähnlichkeiten zu erkennen, auch wenn die Eingabedaten modifiziert oder verschleiert wurden. TLSH wird häufig in der Malware-Analyse und -Erkennung verwendet und ist auch in verschiedene Sicherheitstools und Antivirus-Software integriert.
ssdeep und TLSH verwenden beide Distanzmetriken, um die Ähnlichkeit zwischen zwei Hash-Werten zu bestimmen. Die von ssdeep und TLSH verwendeten Distanzmetriken sind jedoch unterschiedlich.
ssdeep nutzt die "fuzzy hash distance" Metrik, um die Distanz zwischen zwei Hashwerten zu berechnen. Diese Distanzmetrik basiert auf der Anzahl der übereinstimmenden und nicht übereinstimmenden Blöcke zwischen den beiden Hashes sowie der Größe der Hashes. Die Distanzmetrik ist ein prozentualer Wert, der von 0 bis 100 reicht, wobei 0 bedeutet, dass die beiden Hashes identisch sind, und 100 bedeutet, dass die beiden Hashes vollkommen verschieden sind.
TLSH verwendet andererseits die Metrik "total diff", um den Abstand zwischen zwei Hash-Werten zu berechnen. Diese Distanzmetrik basiert auf dem Unterschied zwischen den ortsabhängigen Merkmalen der beiden Eingabedatensätze. Das Ergebnis der "total diff" Metrik ist ein Wert zwischen 0 und 1000, wobei 0 bedeutet, dass die beiden Hash-Werte identisch sind, und 1000 bedeutet, dass die beiden Hash-Werte völlig unterschiedlich sind.
Aufbau des Hashing-Moduls
Für unsere Lösung werden wir Open-Source-Bibliotheken verwenden:
1. PolarSSL: https://polarssl.org/
PolarSSL ist eine kostenlose und quelloffene Softwarebibliothek zur Implementierung kryptographischer Protokolle wie Transport Layer Security (TLS), Secure Sockets Layer (SSL) und Datagram Transport Layer Security (DTLS). Sie bietet verschiedene kryptographische Algorithmen und Protokolle, einschließlich Hashfunktionen, symmetrischer und asymmetrischer Verschlüsselung, digitaler Signaturen und Schlüsselaustauschalgorithmen. PolarSSL ist so konzipiert, dass es leichtgewichtig und effizient ist, was es für den Einsatz in ressourcenbeschränkten Umgebungen geeignet macht.
2. ssdeep: http://ssdeep.sf.net/
3. TLSH: https://github.com/trendmicro/tlsh/
Nach der Implementierung der Bibliotheken in das Projekt fügen wir einen einfachen Code hinzu:
struct HashData
{
BYTE md5[16];
BYTE sha1[20];
BYTE sha512[64];
std::string ssdeep;
std::string tlsh;
};
HashData hash(const void* buff, uint64_t size)
{
HashData snap = {};
hashes::md5(buff, size, snap.md5);
hashes::sha1(buff, size, snap.sha1);
hashes::sha4(buff, size, snap.sha512);
snap.ssdeep = hashes::ssdeepHash(buff, size);
snap.tlsh = hashes::tlshHash(buff, size);
return snap;
}
Überprüfung des Hashing-Moduls
Es ist Zeit, das Hashing-Modul zu testen! Dazu erstellen wir eine Textdatei mit folgendem Inhalt:
All the World`s a Stage by William Shakespeare
All the world`s a stage,
And all the men and women merely players;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first, the infant,
Mewling and puking in the nurse`s arms.
Then the whining schoolboy, with his satchel
And shining morning face, creeping like snail
Unwillingly to school. And then the lover,
Sighing like furnace, with a woeful ballad
Made to his mistress` eyebrow. Then a soldier,
Full of strange oaths and bearded like the pard,
Jealous in honor, sudden and quick in quarrel,
Seeking the bubble reputation
Even in the cannon`s mouth. And then the justice,
In fair round belly with good capon lined,
With eyes severe and beard of formal cut,
Full of wise saws and modern instances;
And so he plays his part. The sixth age shifts
Into the lean and slippered pantaloon,
With spectacles on nose and pouch on side;
His youthful hose, well saved, a world too wide
For his shrunk shank, and his big manly voice,
Turning again toward childish treble, pipes
And whistles in his sound. Last scene of all,
That ends this strange eventful history,
Is second childishness and mere oblivion,
Sans teeth, sans eyes, sans taste, sans everything.
TEST 1: Erstellen Sie zwei identische Dateien mit demselben Inhalt (Text oben) und berechnen Sie die Hashwerte.
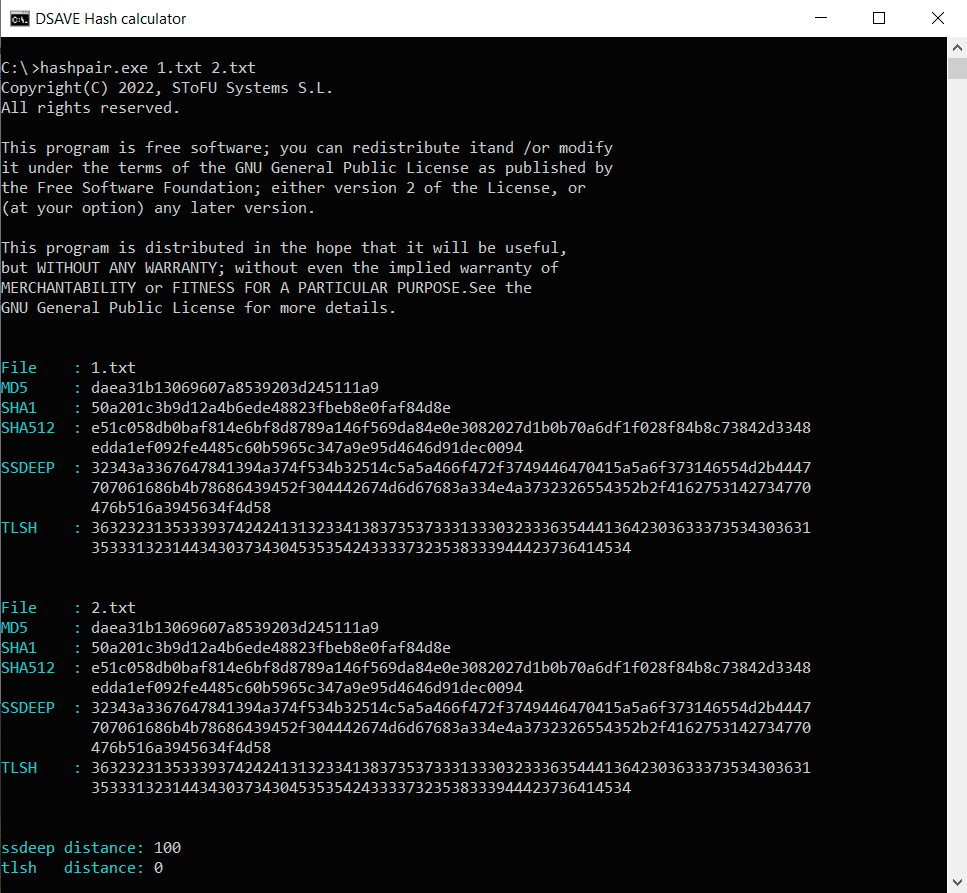
SSDEEP sagt, dass die Dateien 100% identisch sind. TLSH sagt, es gibt 0% Unterschiede zwischen den Dateien.
TEST 2: Erstellen Sie zwei identische Dateien mit demselben Inhalt, nehmen Sie Änderungen in der zweiten Datei vor und berechnen Sie Hashes
Zweiter Dateiinhalt:
All the World`s a Stage by William Shakespeare
O lovely maidens, fall in love,
But not with Muscovites,
For Muscovites are foreign folk,
They do not treat you right.
A Muscovite will love for sport,
And laughing go away;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first, the infant,
Mewling and puking in the nurse`s arms.
Then the whining schoolboy, with his satchel
And shining morning face, creeping like snail
Unwillingly to school. And then the lover,
Sighing like furnace, with a woeful ballad
Made to his mistress` eyebrow. Then a soldier,
Full of strange oaths and bearded like the pard,
Jealous in honor, sudden and quick in quarrel,
Seeking the bubble reputation
Even in the cannon`s mouth. And then the justice,
In fair round belly with good capon lined,
With eyes severe and beard of formal cut,
Full of wise saws and modern instances;
And so he plays his part. The sixth age shifts
Into the lean and slippered pantaloon,
With spectacles on nose and pouch on side;
His youthful hose, well saved, a world too wide
For his shrunk shank, and his big manly voice,
Turning again toward childish treble, pipes
And whistles in his sound. Last scene of all,
That ends this strange eventful history,
Is second childishness and mere oblivion,
Sans teeth, sans eyes, sans taste, sans everything.
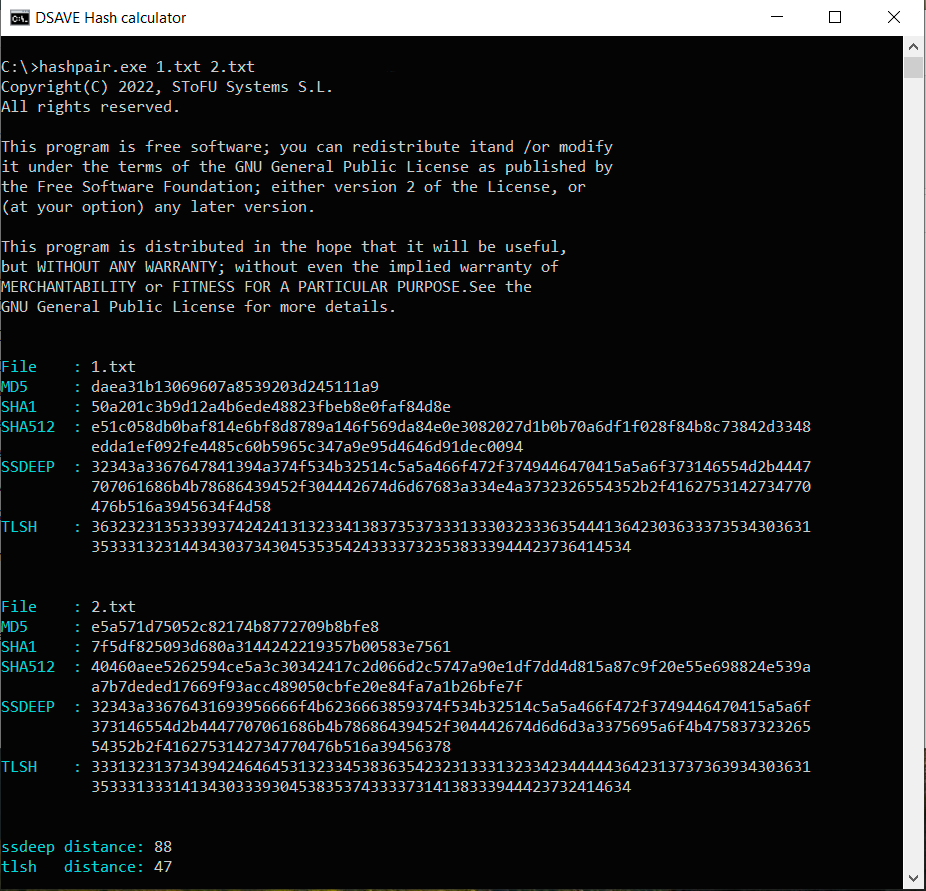
SSDEEP sagt, dass die Dateien zu 88% identisch sind. TLSH sagt, es gibt 4,7% Unterschiede zwischen den Dateien.
TEST 3: Berechne Hashes für zwei völlig verschiedene Textdateien
Zweiter Dateiinhalt:
"Katerina", poem of Taras Shevchenko
(translated by John Weir)
O lovely maidens, fall in love,
But not with Muscovites [2],
For Muscovites are foreign folk,
They do not treat you right.
A Muscovite will love for sport,
And laughing go away;
He`ll go back to his Moscow land
And leave the maid a prey
To grief and shame...
It could be borne
If she were all alone,
But scorn is also heaped upon
Her mother frail and old.
The heart e`en languishing can sing –
For it knows how to wait;
But this the people do not see:
“A strumpet!“ they will say.
O lovely maidens, fall in love,
But not with Muscovites,
For Muscovites are foreign folk,
They leave you in a plight.
Young Katerina did not heed
Her parent`s warning words,
She fell in love with all her heart,
Forgetting all the world.
The orchard was their trysting-place;
She went there in the night
To meet her handsome Muscovite,
And thus she ruined her life.
Her anxious mother called and called
Her daughter home in vain;
There where her lover she caressed,
The whole night she remained.
Thus many nights she kissed her love
With passion strong and true,
The village gossips meanwhile hissed:
“A girl of ill repute!”
Let people talk, let gossips prate,
She does not even hear:
She is in love, that`s all she cares,
Nor feels disaster near.
Bad tidings came of strife with Turks,
The bugles blew one morn:
Her Muscovite went off to war,
And she remained at home.
A kerchief o`er her braids they placed
To show she`s not a maid,
But Katerina does not mind,
Her lover she awaits.
He promised her that he’d return
If he was left alive,
That he`d come back after the war –
And then she`d be his wife,
An army bride, a Muscovite
Herself, her ills forgot,
And if in meantime people prate,
Well, let the people talk!
She does not worry, not a bit –
The reason that she weeps
Is that the girls at sundown sing
Without her on the streets.
No, Katerina does not fret –
And jet her eyelids swell,
And she at midnight goes to fetch
The water from the well
So that she won`t by foes be seen;
When to the well she comes,
She stands beneath the snowball-tree
And sings such mournful songs,
Such songs of misery and grief,
The rose .itself must weep.
Then she comes home - content that she
By neighbours was not seen.
No, Katerina does not fret.
She`s carefree as can be -
With her new kerchief on her head
She looks out on the street.
So at the window day by day
Six months she sat in vain....
With sickness then was overcome,
Her body racked with pain.
Her illness very grievous proved.
She barely breathed for days ...
When it was over - by the stove
She rocked her tiny babe.
The gossips` tongues now got free rein.
The other mothers jibed
That soldiers marching home again
At her house spent the night.
“Oh, you have reared a daughter fair.
And not alone beside
The stove she sits - she`s drilling there
A little Muscovite.
She found herself a brown-eyed son...
You must have taught her how!...
Oh fie on ye, ye prattle tongues,
I hope yourselves you`ll feel
Someday such pains as she who bore
A son that you should jeer!
Oh, Katerina, my poor dear!
How cruel a fate is thine!
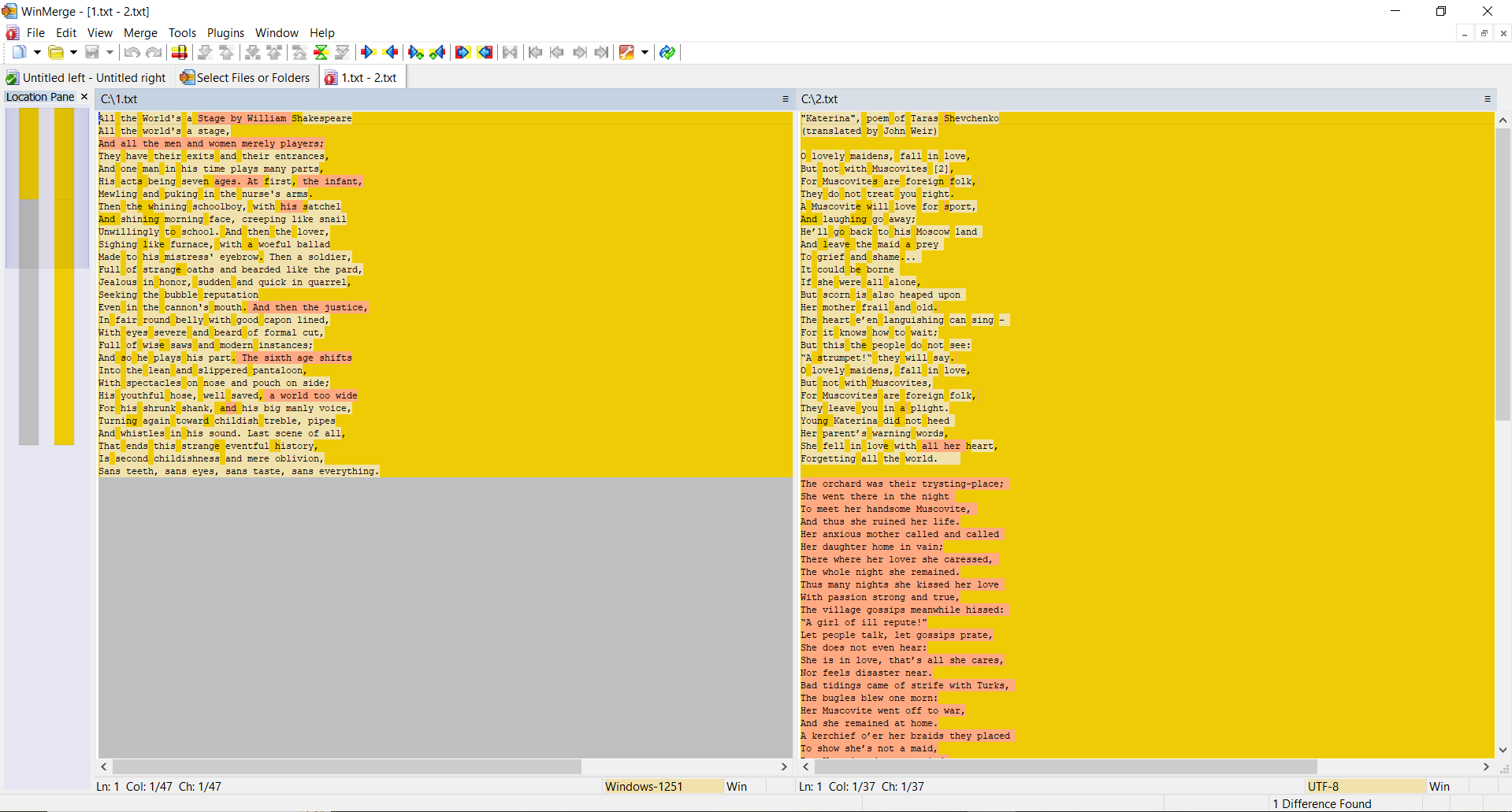
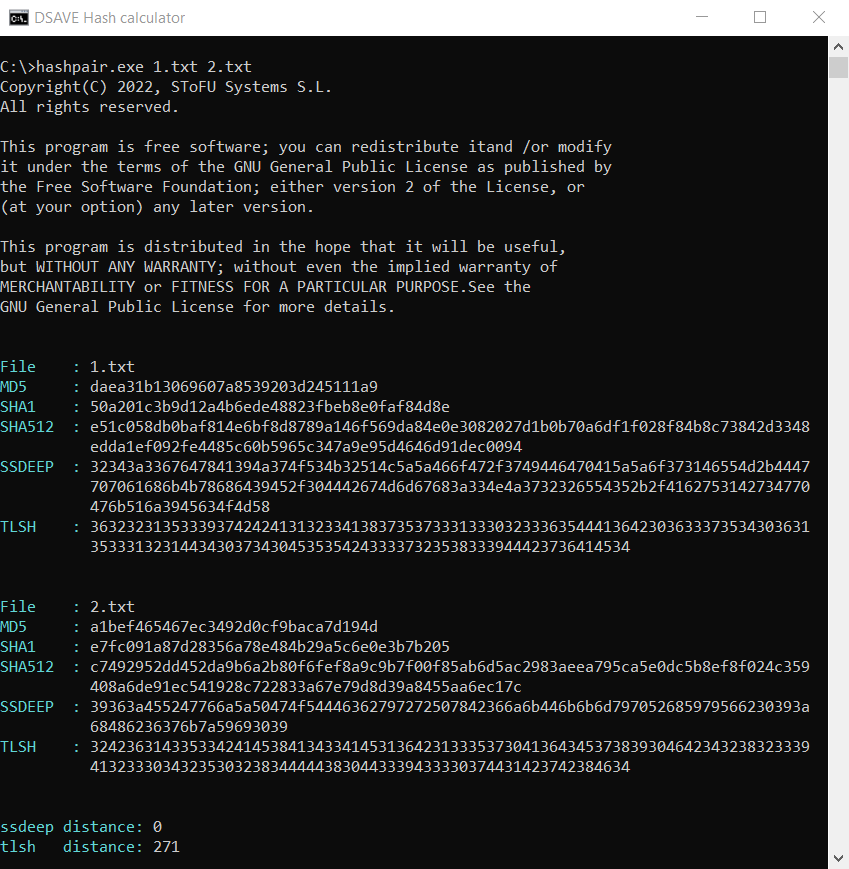
SSDEEP sagt, dass die Dateien völlig unterschiedlich sind, mit 0% Übereinstimmungen. TLSH jedoch sagt, dass die Dateien nur 27,1% unterschiedlich sind.
Warum ist das so? Schließlich betrachten wir die Distanz zwischen zwei völlig verschiedenen Textdateien, oder?
Die Sache ist die, dass, wie wir oben gesagt haben, der TLSH-Algorithmus Häufigkeiten berücksichtigt.
Trotz der Tatsache, dass die Texte unterschiedlich sind, sind sie dennoch in derselben Sprache geschrieben, verwenden dasselbe Alphabet und haben eine Anzahl derselben Wörter. Diese Eigenschaft dieses Hashing-Algorithmus hilft, Modifikationen bösartiger Dateien zu erkennen.
TEST 4: Vergleiche 2 Windows-Systemdateien
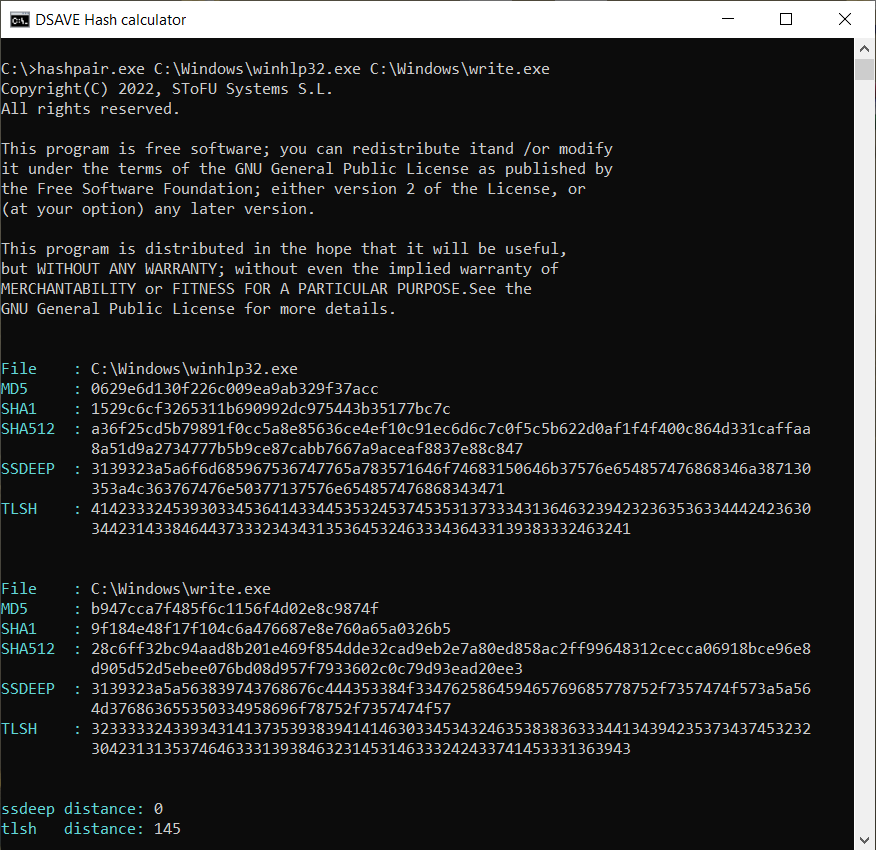
SSDEEP sagt, dass die Dateien völlig unterschiedlich sind, mit 0% Übereinstimmungen.
Jedoch gibt der TLSH-Algorithmus an, dass die Dateien nur um 14,5 % unterschiedlich sind. Dies liegt teilweise daran, dass die Dateien wahrscheinlich vom selben Compiler, von derselben Firma, möglicherweise unter Verwendung derselben Code-Muster erstellt wurden. Die Dateien haben ähnliche VERSION_INFO und MZ-Header.
TEST 5: Vergleiche 2 Systemdateien und unsere hashpair.exe-Datei
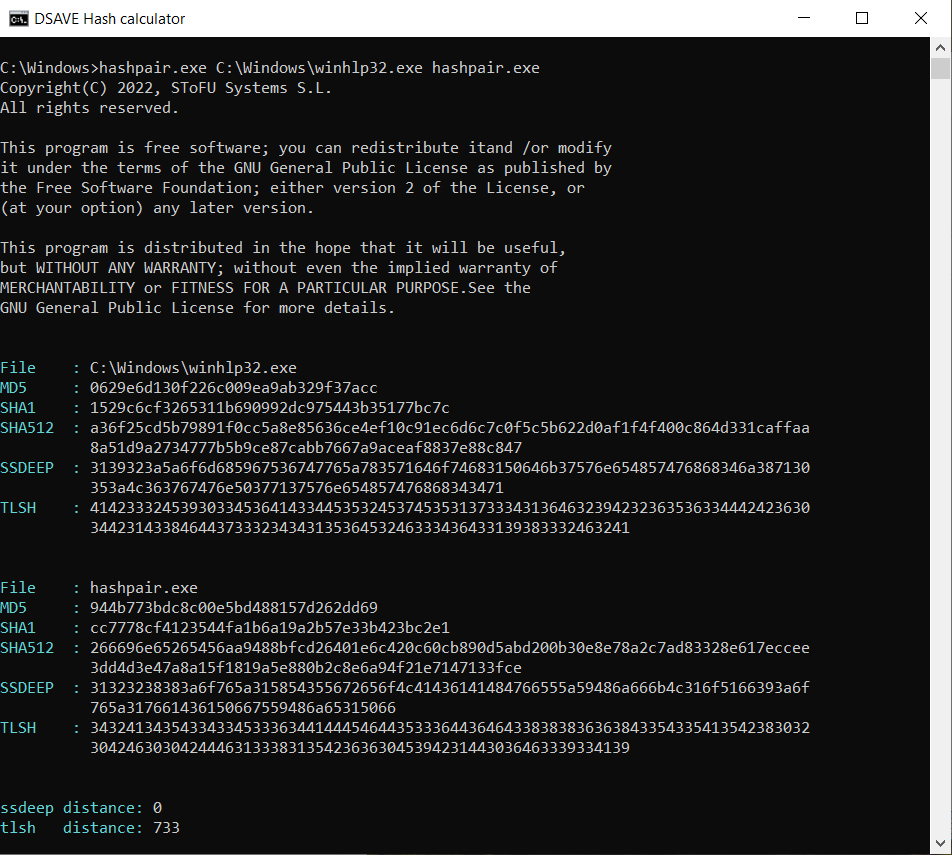
SSDEEP besagt, dass die Dateien völlig unterschiedlich sind, mit 0% Übereinstimmungen.
Der TLSH-Algorithmus besagt, dass sich die Dateien erheblich unterscheiden, und zwar um 73,3%. Diese Dateien wurden von verschiedenen Unternehmen erstellt, unter Verwendung unterschiedlicher Bibliotheken und verschiedener Compiler. Diese Dateien haben unterschiedliche VERSION_INFO und unterschiedliche MZ-Header. Somit ermöglicht der TLSH-Algorithmus die Kategorisierung ausführbarer Dateien, was hilft, ähnliche bösartige Dateien oder bösartige Dateien derselben Familie zu identifizieren.
Liste der verwendeten Werkzeuge
1. WinMerge: https://winmerge.org
WinMerge ist ein Open-Source-Differenzierungs- und Zusammenführungswerkzeug für Windows. WinMerge kann sowohl Ordner als auch Dateien vergleichen und präsentiert die Unterschiede in einem visuellen Textformat, das leicht zu verstehen und zu handhaben ist.
2. Notepad++: https://notepad-plus-plus.org/downloads
Notepad++ ist ein kostenloser (sowohl im Sinne von „freier Rede“ als auch im Sinne von „gratis Bier“) Quelltexteditor und Notepad-Ersatz, der mehrere Sprachen unterstützt. Er läuft in der MS Windows Umgebung und seine Nutzung unterliegt der GNU General Public License.
GITHUB
Sie können den Code des gesamten Projekts auf unserem Github finden:
https://github.com/SToFU-Systems/DSAVE
WAS KOMMT ALS NÄCHSTES?
Wir schätzen Ihre Unterstützung und freuen uns auf Ihre weitergehende Beteiligung in unserer Gemeinschaft
Im nächsten Artikel werden wir gemeinsam mit Ihnen den einfachsten PE-Ressourcenparser schreiben.
Alle Fragen an die Autoren des Artikels können per E-Mail gesendet werden an: articles@stofu.io
Danke für Ihre Aufmerksamkeit und haben Sie einen schönen Tag!




