Das Portable Executable (PE) Format
Das Erste, womit man beginnen sollte, ist das PE-Format. Kenntnisse und Verständnis dieses Formats sind eine Voraussetzung für die Entwicklung von Antiviren-Engines für die Windows-Plattform (historisch gesehen sind die meisten Viren weltweit auf Windows abgezielt).
Das Portable Executable (PE) Format ist ein Dateiformat, das vom Windows-Betriebssystem verwendet wird, um ausführbare Dateien wie .EXE und .DLL Dateien zu speichern. Es wurde mit der Veröffentlichung von Windows NT im Jahr 1993 eingeführt und ist seitdem das Standardformat für ausführbare Dateien auf Windows-Systemen geworden.
Vor der Einführung des PE-Formats verwendete Windows eine Vielzahl verschiedener Formate für ausführbare Dateien, einschließlich des New Executable (NE)-Formats für 16-Bit-Programme und des Compact Executable (CE)-Formats für 32-Bit-Programme. Diese Formate hatten ihre eigenen einzigartigen Regeln und Konventionen, was es dem Betriebssystem erschwerte, Programme zuverlässig zu laden und auszuführen.
Um das Layout und die Struktur ausführbarer Dateien zu standardisieren, führte Microsoft das PE-Format mit der Veröffentlichung von Windows NT ein. Das PE-Format wurde als ein gemeinsames Format für 32-Bit und 64-Bit Programme entwickelt.
Eines der Hauptmerkmale des PE-Formats ist die Verwendung eines standardisierten Headers, der sich am Anfang der Datei befindet und mehrere Felder enthält, die dem Betriebssystem wichtige Informationen über die ausführbare Datei liefern. Dieser Header umfasst die IMAGE_DOS_HEADER und die IMAGE_NT_HEADER Strukturen, die in zwei Hauptabschnitte unterteilt sind: den IMAGE_FILE_HEADER und den IMAGE_OPTIONAL_HEADER.
Die meisten Kopfzeilen des PE-Formats sind in der Header-Datei WinNT.h deklariert
IMAGE_DOS_HEADER
Die IMAGE_DOS_HEADER-Struktur ist ein veralteter Header, der zur Unterstützung der Rückwärtskompatibilität mit MS-DOS verwendet wird. Sie dient dazu, Informationen über die Datei zu speichern, die von MS-DOS benötigt werden, wie den Speicherort des Codes und der Daten des Programms in der Datei und den Einstiegspunkt des Programms. Dies ermöglichte es, Programme, die für MS-DOS geschrieben wurden, unter Windows NT auszuführen, vorausgesetzt, sie wurden als PE-Dateien kompiliert.
typedef struct _IMAGE_DOS_HEADER
{
WORD e_magic;
WORD e_cblp;
WORD e_cp;
WORD e_crlc;
WORD e_cparhdr;
WORD e_minalloc;
WORD e_maxalloc;
WORD e_ss;
WORD e_sp;
WORD e_csum;
WORD e_ip;
WORD e_cs;
WORD e_lfarlc;
WORD e_ovno;
WORD e_res[4];
WORD e_oemid;
WORD e_oeminfo;
WORD e_res2[10];
DWORD e_lfanew; // offset of IMAGE_NT_HEADER
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
Es gibt folgende interessante Bereiche für uns:
-
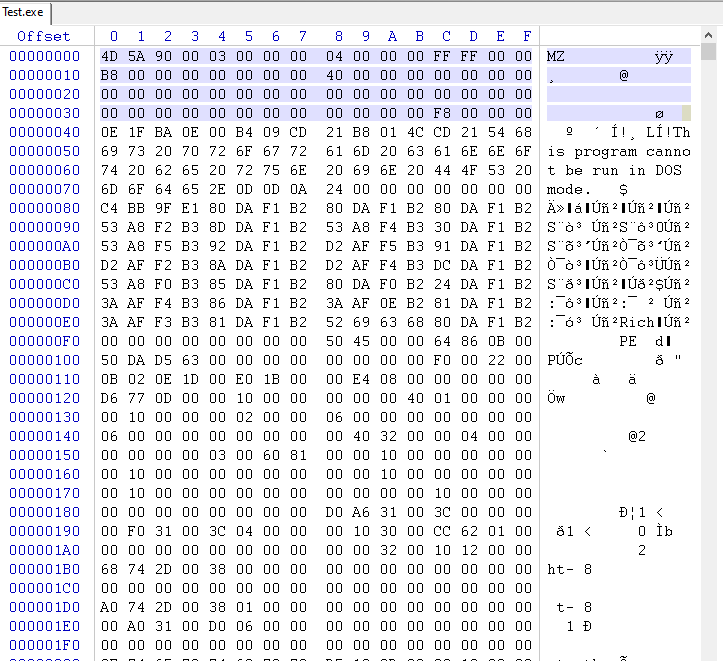
e_magic Feld wird verwendet, um die Datei als gültige PE-Datei zu identifizieren. Wie Sie sehen können, ist das e_magic Feld ein 16-Bit unsigned Integer, das die "Magiezahl" der Datei angibt. Die Magiezahl ist ein spezieller Wert, der die Datei als gültige PE-Datei identifiziert. Sie ist auf den Wert 0x5A4D (hexadezimal) gesetzt, was der ASCII-Darstellung der Zeichen "MZ" (IMAGE_DOS_SIGNATURE) entspricht.
-
e_lfanew Feld wird verwendet, um den Ort der IMAGE_NT_HEADERS Struktur anzugeben, die Informationen über das Layout und die Eigenschaften der PE-Datei enthält. Wie Sie sehen können, ist das e_lfanew Feld ein 32-Bit signed Integer, der den Ort der IMAGE_NT_HEADERS Struktur in der Datei angibt. Es ist üblicherweise auf den Offset der Struktur relativ zum Anfang der Datei gesetzt.
Geschichte
In den frühen 1980er Jahren arbeitete Microsoft an einem neuen Betriebssystem namens MS-DOS, das als einfaches, leichtgewichtiges Betriebssystem für Personalcomputer konzipiert war. Eine der Schlüsselfunktionen von MS-DOS war seine Fähigkeit, ausführbare Dateien zu starten, also Programme, die auf einem Computer ausgeführt werden können.
Um es einfach zu machen, ausführbare Dateien zu identifizieren, entschieden sich die Entwickler von MS-DOS dazu, eine spezielle "magische Zahl" am Anfang jeder ausführbaren Datei zu verwenden. Diese magische Zahl sollte dazu dienen, ausführbare Dateien von anderen Dateitypen, wie Datendateien oder Konfigurationsdateien, zu unterscheiden.
Mark Zbikowski, der ein Entwickler im MS-DOS-Team war, kam auf die Idee, die Zeichen "MZ" als magische Zahl zu verwenden. Im ASCII-Code wird der Buchstabe "M" durch den hexadezimalen Wert 0x4D dargestellt, und der Buchstabe "Z" wird durch den hexadezimalen Wert 0x5A dargestellt. Wenn diese Werte kombiniert werden, bilden sie die magische Zahl 0x5A4D, welche die ASCII-Darstellung der Zeichen "MZ" ist.
Heute wird die "MZ"-Signatur immer noch verwendet, um PE-Dateien zu identifizieren, die das Hauptausführungsdateiformat im Windows-Betriebssystem sind. Sie wird im e_magic-Feld der IMAGE_DOS_HEADER Struktur gespeichert, welche die erste Struktur in einer PE-Datei ist.
IMAGE_NT_HEADER
Der IMAGE_NT_HEADER ist eine Datenstruktur, die mit dem Betriebssystem Windows NT eingeführt wurde, das 1993 veröffentlicht wurde. Sie wurde entwickelt, um dem Betriebssystem eine standardisierte Möglichkeit zu bieten, den Inhalt ausführbarer Dateien (PE-Dateien) zu lesen und zu interpretieren.
Mit der Veröffentlichung von Windows NT führte Microsoft den IMAGE_NT_HEADER ein, um das Layout und die Struktur ausführbarer Dateien zu standardisieren. Dies erleichterte es dem Betriebssystem, Programme zu laden und auszuführen, da es nur ein einziges Format unterstützen musste.
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_nt_headers32
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_nt_headers64
typedef struct _IMAGE_NT_HEADERS32
{
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
typedef struct _IMAGE_NT_HEADERS64
{
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER64 OptionalHeader;
} IMAGE_NT_HEADERS64, *PIMAGE_NT_HEADERS64;
Der IMAGE_NT_HEADER ist eine Struktur, die am Anfang jeder portablen ausführbaren (PE) Datei im Windows-Betriebssystem erscheint. Er enthält eine Reihe von Feldern, die dem Betriebssystem wichtige Informationen über die ausführbare Datei liefern, wie etwa deren Größe, Layout und beabsichtigten Zweck.
Die IMAGE_NT_HEADER-Struktur ist in zwei Hauptabschnitte unterteilt: den IMAGE_FILE_HEADER und den IMAGE_OPTIONAL_HEADER.

BILDDATEI-KOPFZEILE
Der IMAGE_FILE_HEADER enthält Informationen über die ausführbare Datei als Ganzes, einschließlich ihres Maschinentyps (z. B. x86, x64), der Anzahl der Abschnitte in der Datei und dem Datum und der Uhrzeit der Erstellung der Datei.
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_file_header
typedef struct _IMAGE_FILE_HEADER
{
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
Die Struktur hat die folgenden Felder:
-
Machine: Dieses Feld gibt die Zielarchitektur an, für die die Datei erstellt wurde. Der Wert dieses Feldes wird vom Compiler bestimmt, wenn die Datei erstellt wird. Einige gängige Werte sind:
-
IMAGE_FILE_MACHINE_I386: Die Datei ist für die Ausführung auf der x86-Architektur vorgesehen, auch bekannt als 32-Bit.
-
IMAGE_FILE_MACHINE_AMD64: Die Datei ist für die Ausführung auf der x64-Architektur vorgesehen, auch bekannt als 64-Bit.
-
IMAGE_FILE_MACHINE_ARM: Die Datei ist für die Ausführung auf der ARM-Architektur vorgesehen.
-
-
NumberOfSections: Dieses Feld gibt die Anzahl der Abschnitte in der PE-Datei an. Eine PE-Datei ist in mehrere Abschnitte unterteilt, von denen jeder unterschiedliche Arten von Informationen wie Code, Daten und Ressourcen enthält. Dieses Feld wird vom Betriebssystem verwendet, um die Anzahl der Abschnitte in der Datei zu bestimmen.
-
TimeDateStamp: Dieses Feld enthält den Zeitstempel der Erstellung der Datei. Der Zeitstempel wird als 4-Byte-Wert gespeichert, der die Anzahl der Sekunden seit dem 1. Januar 1970, 00:00:00 UTC, darstellt. Dieses Feld kann verwendet werden, um zu ermitteln, wann die Datei zuletzt erstellt wurde, was für die Fehlersuche oder Versionsverwaltung nützlich sein kann.
-
PointerToSymbolTable: Dieses Feld gibt den Dateioffset der COFF (Common Object File Format) Symboltabelle an, falls vorhanden. Die COFF-Symboltabelle enthält Informationen über in der Datei verwendete Symbole, wie Funktionsnamen, Variablennamen und Zeilennummern. Dieses Feld wird nur zu Debugging-Zwecken verwendet und ist in Release-Builds in der Regel nicht vorhanden.
-
NumberOfSymbols: Dieses Feld gibt die Anzahl der Symbole in der COFF-Symboltabelle an, falls vorhanden. Dieses Feld wird in Verbindung mit PointerToSymbolTable verwendet, um die COFF-Symboltabelle in der Datei zu lokalisieren.
-
SizeOfOptionalHeader: Dieses Feld gibt die Größe des optionalen Headers an, der zusätzliche Informationen über die Datei enthält. Der optionale Header enthält typischerweise Informationen über den Einstiegspunkt der Datei, die importierten Bibliotheken und die Größe des Stacks und des Heaps.
-
Characteristics: Dieses Feld gibt verschiedene Attribute der Datei an. Einige gängige Werte sind:
-
IMAGE_FILE_EXECUTABLE_IMAGE: Die Datei ist eine ausführbare Datei.
-
IMAGE_FILE_DLL: Die Datei ist eine dynamisch gelinkte Bibliothek (DLL).
-
IMAGE_FILE_32BIT_MACHINE: Die Datei ist eine 32-Bit-Datei.
-
IMAGE_FILE_DEBUG_STRIPPED: Der Debug-Informationen wurden aus der Datei entfernt.
-
Diese Felder liefern wichtige Informationen über die Datei, die vom Betriebssystem beim Laden der Datei in den Speicher und deren Ausführung verwendet werden. Durch das Verständnis der Felder in der IMAGE_FILE_HEADER Struktur können Sie ein tieferes Verständnis dafür entwickeln, wie PE-Dateien aufgebaut sind und wie das Betriebssystem sie verwendet.
Die meisten der möglichen Werte für jedes Feld sind in der Header-Datei WinNT.h deklariert
BILDOPTIONALER_HEADER
Die IMAGE_FILE_HEADER-Struktur wird von dem optionalen Header gefolgt, der durch die IMAGE_OPTIONAL_HEADER-Struktur beschrieben wird. Der optionale Header enthält zusätzliche Informationen über das Image, wie die Adresse des Einstiegspunkts, die Größe des Images und die Adresse des Importverzeichnisses.
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_optional_header32
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_optional_header64
typedef struct _IMAGE_OPTIONAL_HEADER32
{
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
typedef struct _IMAGE_OPTIONAL_HEADER64
{
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
ULONGLONG ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
ULONGLONG SizeOfStackReserve;
ULONGLONG SizeOfStackCommit;
ULONGLONG SizeOfHeapReserve;
ULONGLONG SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER64, *PIMAGE_OPTIONAL_HEADER64;
Hier ist eine detaillierte Beschreibung jedes Feldes in der IMAGE_OPTIONAL_HEADER Struktur:
-
Magic: Dieses Feld gibt den Typ des optionalen Headers an, der in der PE-Datei vorhanden ist. Der häufigste Wert ist IMAGE_NT_OPTIONAL_HDR32_MAGIC für eine 32-Bit-Datei oder IMAGE_NT_OPTIONAL_HDR64_MAGIC für eine 64-Bit-Datei.
-
MajorLinkerVersion und MinorLinkerVersion: Diese Felder geben die Version des Linkers an, der zum Erstellen der Datei verwendet wurde. Der Linker ist ein Werkzeug, das verwendet wird, um Objektdateien und Bibliotheken zu einer einzigen ausführbaren Datei zu kombinieren.
-
SizeOfCode: Dieses Feld gibt die Größe des Codesegments in der Datei an. Das Codesegment enthält den Maschinencode für die ausführbare Datei.
-
SizeOfInitializedData: Dieses Feld gibt die Größe des initialisierten Datensegments in der Datei an. Das initialisierte Datensegment enthält Daten, die zur Laufzeit initialisiert werden, wie globale Variablen.
-
SizeOfUninitializedData: Dieses Feld gibt die Größe des nicht initialisierten Datensegments in der Datei an. Das nicht initialisierte Datensegment enthält Daten, die zur Laufzeit nicht initialisiert werden, wie der BSS-Abschnitt.
-
AddressOfEntryPoint: Dieses Feld gibt die virtuelle Adresse des Einstiegspunkts der Datei an. Der Einstiegspunkt ist die Startadresse des Programms und ist die erste Instruktion, die ausgeführt wird, wenn die Datei in den Speicher geladen wird.
-
BaseOfCode: Dieses Feld gibt die virtuelle Adresse des Beginns des Codesegments an.
-
ImageBase: Dieses Feld gibt die bevorzugte virtuelle Adresse an, unter der die Datei in den Speicher geladen werden soll. Diese Adresse wird als Basisadresse für alle virtuellen Adressen innerhalb der Datei verwendet.
-
SectionAlignment: Dieses Feld gibt die Ausrichtung der Abschnitte innerhalb der Datei an. Die Abschnitte in der Datei sind typischerweise auf Vielfache dieses Wertes ausgerichtet, um die Leistung zu verbessern.
-
FileAlignment: Dieses Feld gibt die Ausrichtung der Abschnitte innerhalb der Datei auf der Festplatte an. Die Abschnitte in der Datei sind typischerweise auf Vielfache dieses Wertes ausgerichtet, um die Festplattenleistung zu verbessern.
-
MajorOperatingSystemVersion und MinorOperatingSystemVersion: Diese Felder geben die minimal erforderliche Version des Betriebssystems an, die erforderlich ist, um die Datei auszuführen.
-
MajorImageVersion und MinorImageVersion: Diese Felder geben die Version des Images an. Die Bildversion wird verwendet, um die Version der Datei für Versionsverwaltungszwecke zu identifizieren.
-
MajorSubsystemVersion und MinorSubsystemVersion: Diese Felder geben die Version des Subsystems an, das erforderlich ist, um die Datei auszuführen. Das Subsystem ist die Umgebung, in der die Datei ausgeführt wird, wie die Windows-Konsole oder die Windows-GUI.
-
Win32VersionValue: Dieses Feld ist reserviert und normalerweise auf 0 gesetzt.
-
SizeOfImage: Dieses Feld gibt die Größe des Images in Bytes an, wenn es in den Speicher geladen wird.
-
SizeOfHeaders: Dieses Feld gibt die Größe der Header in Bytes an. Die Header umfassen den IMAGE_FILE_HEADER und IMAGE_OPTIONAL_HEADER.
-
CheckSum: Dieses Feld wird verwendet, um die Integrität der Datei zu überprüfen. Die Prüfsumme wird berechnet, indem die Inhalte der Datei summiert und das Ergebnis in diesem Feld gespeichert wird. Die Prüfsumme wird verwendet, um Änderungen an der Datei zu erkennen, die durch Manipulation oder Beschädigung auftreten können.
-
Subsystem: Dieses Feld gibt das Subsystem an, das erforderlich ist, um die Datei auszuführen. Mögliche Werte umfassen IMAGE_SUBSYSTEM_NATIVE, IMAGE_SUBSYSTEM_WINDOWS_GUI, IMAGE_SUBSYSTEM_WINDOWS_CUI, IMAGE_SUBSYSTEM_OS2_CUI usw.
-
DllCharacteristics: Dieses Feld gibt Eigenschaften der Datei an, wie zum Beispiel, ob es sich um eine dynamische Linkbibliothek (DLL) handelt oder ob sie beim Laden verschoben werden kann. Mögliche Werte umfassen IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASE, IMAGE_DLLCHARACTERISTICS_NX_COMPAT usw.
-
SizeOfStackReserve: Dieses Feld gibt die Größe des für das Programm reservierten Stacks in Bytes an. Der Stack wird verwendet, um temporäre Daten, wie Funktionsaufrufinformationen, zu speichern.
-
SizeOfStackCommit: Dieses Feld gibt die Größe des für das Programm festgelegten Stacks in Bytes an. Der festgelegte Stack ist der Teil des Stacks, der tatsächlich im Speicher reserviert ist.
-
SizeOfHeapReserve: Dieses Feld gibt die Größe des für das Programm reservierten Heaps in Bytes an. Der Heap wird verwendet, um Speicher dynamisch zur Laufzeit zuzuweisen.
-
SizeOfHeapCommit: Dieses Feld gibt die Größe des für das Programm festgelegten Heaps in Bytes an. Der festgelegte Heap ist der Teil des Heaps, der tatsächlich im Speicher reserviert ist.
-
LoaderFlags: Dieses Feld ist reserviert und normalerweise auf 0 gesetzt.
-
NumberOfRvaAndSizes: Dieses Feld gibt die Anzahl der Datendirectory-Einträge im IMAGE_OPTIONAL_HEADER an. Die Datendirectories enthalten Informationen über die Importe, Exporte, Ressourcen usw. in der Datei.
-
DataDirectory: Dieses Feld ist ein Array von IMAGE_DATA_DIRECTORY-Strukturen, die die Lage und Größe der Datendirectories in der Datei angeben.
BILDBEREICHSÜBERSCHRIFT
Ein Abschnitt, im Kontext einer PE (Portable Executable)-Datei, ist ein zusammenhängender Speicherblock in der Datei, der eine spezifische Art von Daten oder Code enthält. In einer PE-Datei werden Abschnitte verwendet, um verschiedene Teile der Datei zu organisieren und zu speichern, wie den Code, Daten, Ressourcen usw.
Jeder Abschnitt in einer PE-Datei hat einen einzigartigen Namen und wird durch eine IMAGE_SECTION_HEADER Struktur beschrieben, die Informationen über den Abschnitt wie seine Größe, Lage, Eigenschaften usw. enthält. Die folgenden sind die Felder des IMAGE_SECTION_HEADER:
Ein IMAGE_SECTION_HEADER ist eine Datenstruktur, die im Portable Executable (PE) Dateiformat verwendet wird, welches auf dem Windows-Betriebssystem eingesetzt wird, um das Layout einer Datei im Speicher zu definieren. Das PE-Dateiformat wird für ausführbare Dateien, DLLs und andere Arten von Dateien verwendet, die vom Windows-Betriebssystem in den Speicher geladen werden. Jeder Sektionsheader beschreibt einen zusammenhängenden Datenblock innerhalb der Datei und enthält Informationen wie den Namen der Sektion, die virtuelle Speicheradresse, an der die Sektion geladen werden soll, und die Größe der Sektion. Die Sektionsheader können dazu verwendet werden, spezifische Teile der Datei, wie den Code oder Datensektionen, zu lokalisieren und darauf zuzugreifen.
Die IMAGE_SECTION_HEADER-Struktur ist im Windows Platform SDK definiert und kann in der winnt.h-Headerdatei gefunden werden. Hier ist ein Beispiel, wie die Struktur in C++ definiert wird:
#pragma pack(push, 1)
typedef struct _IMAGE_SECTION_HEADER
{
BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; // 8
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
#pragma pack(pop)
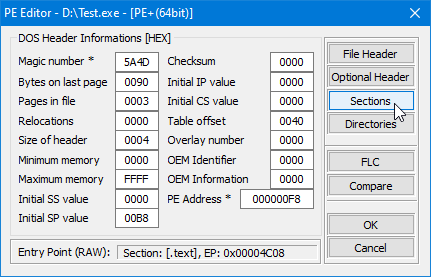
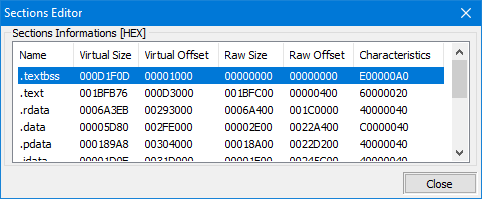
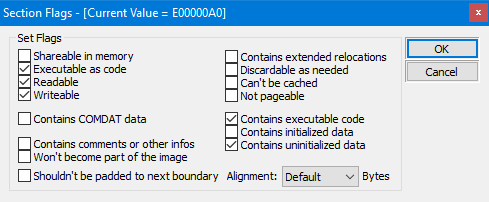
Wie Sie sehen können, ist die Struktur als C++-Struktur definiert und sie enthält Felder für den Namen des Abschnitts, die virtuelle Größe, die virtuelle Adresse, die Größe der Rohdaten und den Zeiger auf die Rohdaten, Relokationen, Zeilennummern und die Anzahl der Relokationen und Zeilennummern. Zusätzlich enthält das Feld "Characteristics" Flags, die die Eigenschaften des Abschnitts beschreiben, wie z.B. ob er ausführbar, lesbar oder beschreibbar ist.
-
Name: Dieses 8-Byte-Array wird verwendet, um den Namen des Abschnitts anzugeben. Der Name kann jede null-terminierte Zeichenkette sein, wird jedoch typischerweise verwendet, um verschiedenen Teilen der Datei aussagekräftige Namen zu geben, wie z. B. ".text" für ausführbaren Code, ".data" für initialisierte Daten, ".rdata" für schreibgeschützte Daten und ".bss" für uninitialisierte Daten. Der Name des Abschnitts wird vom Betriebssystem verwendet, um den Abschnitt innerhalb der Datei zu lokalisieren, und auch von Debuggern und anderen Werkzeugen, um den Abschnitt und seinen Inhalt zu identifizieren.
-
VirtualSize: Dieses Feld gibt die Größe des Abschnitts im Speicher in Bytes an. Dieser Wert stellt die Menge des Speichers dar, die der Abschnitt im Speicher belegen wird, wenn die Datei in den Speicher geladen wird. Die virtuelle Größe des Abschnitts wird vom Betriebssystem verwendet, um die Menge des Speichers zu bestimmen, die für den Abschnitt zugewiesen werden muss, wenn die Datei in den Speicher geladen wird.
-
VirtualAddress: Dieses Feld gibt die Startadresse des Abschnitts im Speicher in Bytes an. Dieser Wert ist die Startadresse, an der der Abschnitt in den Speicher geladen wird, und wird vom Betriebssystem verwendet, um den Ort im Speicher zu bestimmen, an dem der Abschnitt geladen wird. Die virtuelle Adresse des Abschnitts wird auch vom Betriebssystem verwendet, um Adressen innerhalb des Abschnitts aufzulösen, sodass sie bei Laden der Datei in den Speicher korrekt in Speicheradressen übersetzt werden können.
-
SizeOfRawData: Dieses Feld gibt die Größe des Abschnitts in der Datei in Bytes an. Dieser Wert stellt den Platz in der Datei dar, den der Abschnitt belegen wird, und wird vom Betriebssystem verwendet, um die Größe des Abschnitts in der Datei zu bestimmen. Die Größe der Rohdaten eines Abschnitts wird vom Betriebssystem verwendet, um den Abschnitt innerhalb der Datei zu lokalisieren und die Größe des Abschnitts zu bestimmen, wenn er in den Speicher geladen wird.
-
PointerToRawData: Dieses Feld gibt den Offset des Abschnitts in der Datei in Bytes an. Dieser Wert stellt den Ort des Abschnitts innerhalb der Datei dar und wird verwendet, um zu bestimmen, wo die Daten für den Abschnitt zu finden sind. Der Zeiger auf die Rohdaten eines Abschnitts wird vom Betriebssystem verwendet, um den Abschnitt innerhalb der Datei zu lokalisieren und den Ort des Abschnitts zu bestimmen, wenn er in den Speicher geladen wird.
-
PointerToRelocations: Dieses Feld gibt den Offset der Umzugsinformationen für den Abschnitt in Bytes an. Die Umzugsinformationen werden verwendet, um Adressen innerhalb des Abschnitts zu korrigieren, damit sie beim Laden der Datei in den Speicher ordnungsgemäß aufgelöst werden können. Der Zeiger auf die Umzüge eines Abschnitts wird vom Betriebssystem verwendet, um die Umzugsinformationen für den Abschnitt zu lokalisieren und zu bestimmen, wie die Adressen innerhalb des Abschnitts beim Laden der Datei in den Speicher korrigiert werden.
-
PointerToLinenumbers: Dieses Feld gibt den Offset der Zeilennummerninformationen für den Abschnitt in Bytes an. Die Zeilennummerninformationen werden zu Debugging-Zwecken verwendet und liefern Informationen über den Quellcode, der den Abschnitt generiert hat. Der Zeiger auf die Zeilennummern eines Abschnitts wird von Debuggern und anderen Werkzeugen verwendet, um den Quellcode zu identifizieren, der den Abschnitt generiert hat, und um detailliertere Informationen über den Inhalt des Abschnitts bereitzustellen.
-
NumberOfRelocations: Dieses Feld gibt die Anzahl der Umzugseinträge für den Abschnitt an. Ein Umzugseintrag ist ein Eintrag, der beschreibt, wie eine Adresse innerhalb des Abschnitts korrigiert werden soll, damit sie beim Laden der Datei in den Speicher ordnungsgemäß aufgelöst werden kann. Die Anzahl der Umzüge eines Abschnitts wird vom Betriebssystem verwendet, um die Größe der Umzugsinformationen für den Abschnitt zu bestimmen und zu erfahren, wie viele Umzugseinträge verarbeitet werden müssen, wenn die Datei in den Speicher geladen wird.
-
NumberOfLinenumbers: Dieses Feld gibt die Anzahl der Zeilennummerninträge für den Abschnitt an. Ein ZeilennummernEintrag ist ein Eintrag, der Informationen über den Quellcode liefert, der den Abschnitt generiert hat, und wird zu Debugging-Zwecken verwendet. Die Anzahl der Zeilennummern eines Abschnitts wird von Debuggern und anderen Werkzeugen verwendet, um die Größe der Zeilennummerninformationen für den Abschnitt zu bestimmen und zu erfahren, wie viele ZeilennummernEinträge verarbeitet werden müssen, um Informationen über den Quellcode zu erhalten, der den Abschnitt generiert hat.
-
Characteristics: Dieses Feld ist eine Menge von Flags, die die Attribute des Abschnitts angeben. Einige der häufig verwendeten Flags für Abschnitte sind: IMAGE_SCN_CNT_CODE um anzudeuten, dass der Abschnitt ausführbaren Code enthält, IMAGE_SCN_CNT_INITIALIZED_DATA um anzugeben, dass der Abschnitt initialisierte Daten enthält, IMAGE_SCN_CNT_UNINITIALIZED_DATA um anzudeuten, dass der Abschnitt uninitialisierte Daten enthält, IMAGE_SCN_MEM_EXECUTE um anzudeuten, dass der Abschnitt ausgeführt werden kann, IMAGE_SCN_MEM_READ um anzudeuten, dass der Abschnitt gelesen werden kann, und IMAGE_SCN_MEM_WRITE um anzudeuten, dass in den Abschnitt geschrieben werden kann. Diese Flags werden vom Betriebssystem verwendet, um die Eigenschaften des Abschnitts zu bestimmen und zu wissen, wie mit dem Abschnitt umgegangen werden soll, wenn die Datei in den Speicher geladen wird.
Diese Felder werden vom Betriebssystem und anderen Programmen verwendet, um das Speicherlayout der Datei zu verwalten und spezifische Teile der Datei, wie die Code- oder Datensektionen, zu lokalisieren und darauf zuzugreifen.
WICHTIG: Im Kontext der IMAGE_NT_HEADER Struktur, die im Portable Executable (PE) Dateiformat verwendet wird, beziehen sich die Felder VirtualAddress und PhysicalAddress auf unterschiedliche Dinge.
Das Feld VirtualAddress wird verwendet, um die virtuelle Adresse anzugeben, an der der Abschnitt mit der IMAGE_NT_HEADER Struktur zur Laufzeit in den Speicher geladen wird. Diese Adresse ist relativ zur Basisadresse des Prozesses und wird vom Programm genutzt, um auf die Daten des Abschnitts zuzugreifen.
Das Feld PhysicalAddress wird verwendet, um den Dateioffset des Abschnitts anzugeben, der die IMAGE_NT_HEADER Struktur in der PE-Datei enthält. Es wird vom Betriebssystem verwendet, um die Daten des Abschnitts in der Datei zu lokalisieren, wenn sie in den Speicher geladen wird.
Alle Header-Felder und Verschiebungen für IMAGE_NT_HEADER sind für den Speicher definiert und arbeiten mit virtuellen Adressen. Wenn Sie ein Feld auf der Festplatte verschieben müssen, müssen Sie die virtuelle Adresse mit der Funktion rva2offset im untenstehenden Code in eine physische Adresse umwandeln.
Zusammenfassend wird VirtualAddress vom Programm verwendet, um auf den Abschnitt im Speicher zuzugreifen, und PhysicalAddress wird vom Betriebssystem verwendet, um den Abschnitt in der Datei zu lokalisieren.

IMPORT
Wenn ein Programm kompiliert wird, erzeugt der Compiler Objektdateien, die den Maschinencode für die Funktionen des Programms enthalten. Die Objektdateien enthalten jedoch möglicherweise nicht alle Informationen, die für die Ausführung des Programms erforderlich sind. Beispielsweise können die Objektdateien Aufrufe von Funktionen enthalten, die nicht im Programm definiert sind, sondern von externen Bibliotheken bereitgestellt werden.
Dies ist der Punkt, an dem die Importtabelle ins Spiel kommt. Die Importtabelle listet die externen Abhängigkeiten des Programms und die Funktionen auf, die das Programm aus diesen Abhängigkeiten importieren muss. Der dynamische Linker verwendet diese Informationen zur Laufzeit, um die Adressen der importierten Funktionen zu ermitteln und sie in das Programm einzubinden.
Zum Beispiel betrachten Sie ein Programm, das die Funktionen aus dem Windows-Betriebssystem verwendet. Das Programm kann Aufrufe zur MessageBox-Funktion aus der user32.dll-Bibliothek enthalten, welche eine Nachrichtenbox auf dem Bildschirm anzeigt. Um die Adresse der MessageBox-Funktion aufzulösen, muss das Programm einen Import für user32.dll in seiner Importtabelle einschließen.
Ebenso, wenn ein Programm Funktionen aus einer Drittanbieter-Bibliothek verwenden muss, muss es einen Import für diese Bibliothek in seiner Importtabelle einschließen. Zum Beispiel würde ein Programm, das die Funktionen aus der OpenSSL-Bibliothek verwendet, einen Import für die libssl.dll-Bibliothek in seiner Importtabelle einschließen.
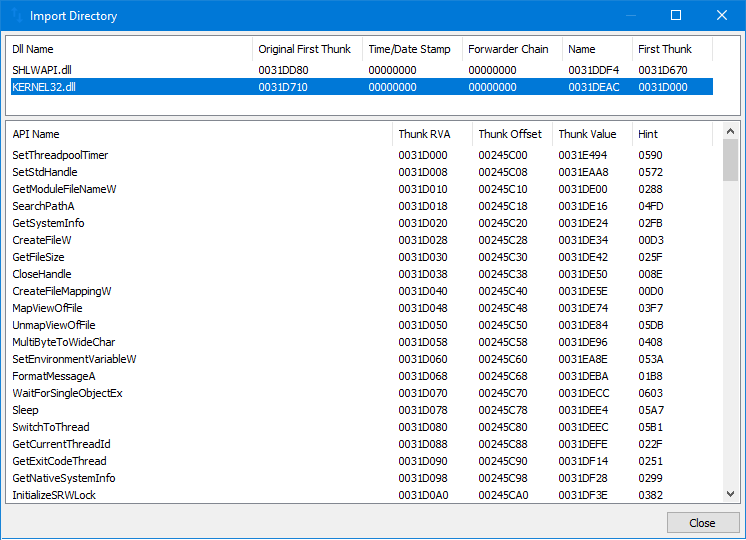
BILDER_IMPORTVERZEICHNIS
Das IMAGE_IMPORT_DIRECTORY ist eine Datenstruktur, die vom Windows-Betriebssystem verwendet wird, um Funktionen und Daten aus dynamischen Link-Bibliotheken (DLLs) in eine portierbare ausführbare (PE) Datei zu importieren. Es ist Teil des IMAGE_DATA_DIRECTORY, das eine Tabelle von Datenstrukturen ist, die im IMAGE_OPTIONAL_HEADER einer PE-Datei gespeichert ist.
Das IMAGE_IMPORT_DIRECTORY wird vom Windows-Lader verwendet, um die importierten Funktionen und Daten aufzulösen, die von der PE-Datei verwendet werden. Dies geschieht durch Zuordnung der Adressen der importierten Funktionen und Daten zu den Adressen der entsprechenden Funktionen und Daten in den DLLs. Dies ermöglicht es der PE-Datei, die Funktionen und Daten aus den DLLs zu verwenden, als wären sie Teil der PE-Datei selbst.
Das IMAGE_IMPORT_DIRECTORY besteht aus einer Reihe von IMAGE_IMPORT_DESCRIPTOR Strukturen, von denen jede eine einzelne DLL beschreibt, die von der PE-Datei importiert wird. Jede IMAGE_IMPORT_DESCRIPTOR Struktur enthält die folgenden Felder:
-
OriginalFirstThunk: ein Zeiger auf eine Tabelle importierter Funktionen.
-
TimeDateStamp: das Datum und die Uhrzeit der letzten Aktualisierung der DLL.
-
ForwarderChain: eine Kette von weitergeleiteten importierten Funktionen.
-
Name: der Name der DLL als null-terminierte Zeichenkette.
-
FirstThunk: ein Zeiger auf eine Tabelle importierter Funktionen, die an die DLL gebunden sind.
typedef struct _IMAGE_IMPORT_DESCRIPTOR
{
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date ime stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name;
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;
OriginalFirstThunk Tabelle (oder FirstThunk , wenn OriginalFirstThunk 0 ist)
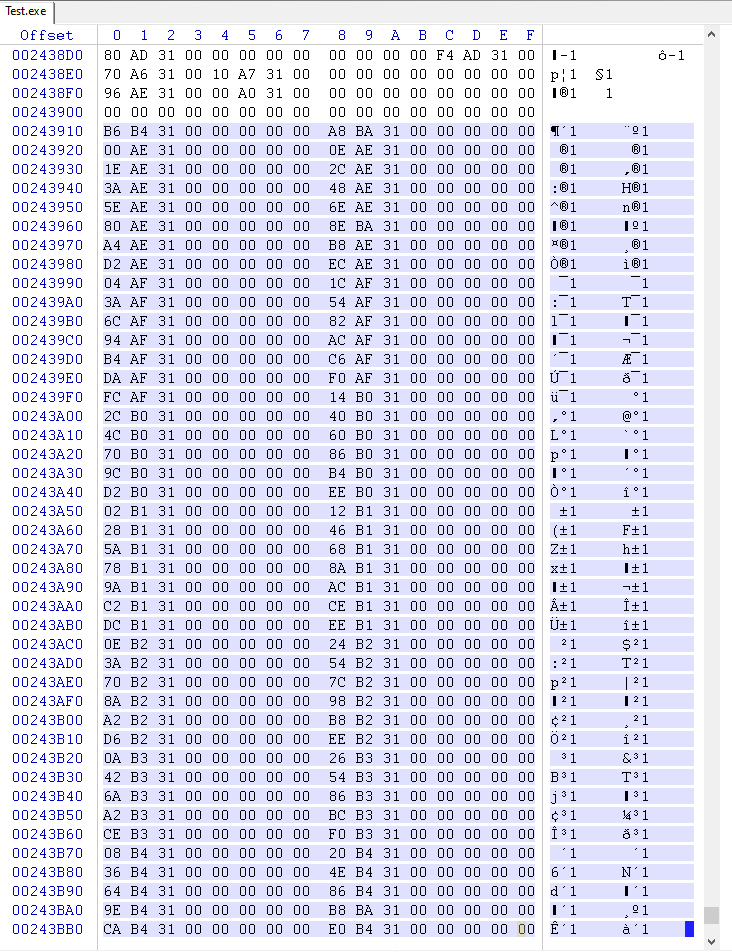
Zeichenfolgen, die durch eine Offsets-Tabelle gezeigt werden (OriginalFirstThunk-Tabelle oder FirstThunk, wenn OriginalFirstThunk 0 ist)

WIE FUNKTIONIERT ES?
Der von Microsoft implementierte Importmechanismus ist kompakt und wunderschön!
Die Adressen aller Funktionen aus Bibliotheken Dritter (einschließlich solcher des Windows-Systems), die die Anwendung verwendet, werden in einer speziellen Tabelle gespeichert - die Importtabelle. Diese Tabelle wird beim Laden des Moduls gefüllt (über andere Mechanismen zum Füllen von Importen werden wir später sprechen).
Weiterhin erzeugt der Compiler normalerweise den folgenden Code, jedes Mal wenn eine Funktion aus einer Drittanbieter-Bibliothek aufgerufen wird:
call dword ptr [__cell_with_address_of_function] // for x86 architecture
call qword ptr [__cell_with_address_of_function] // for x64 architecture
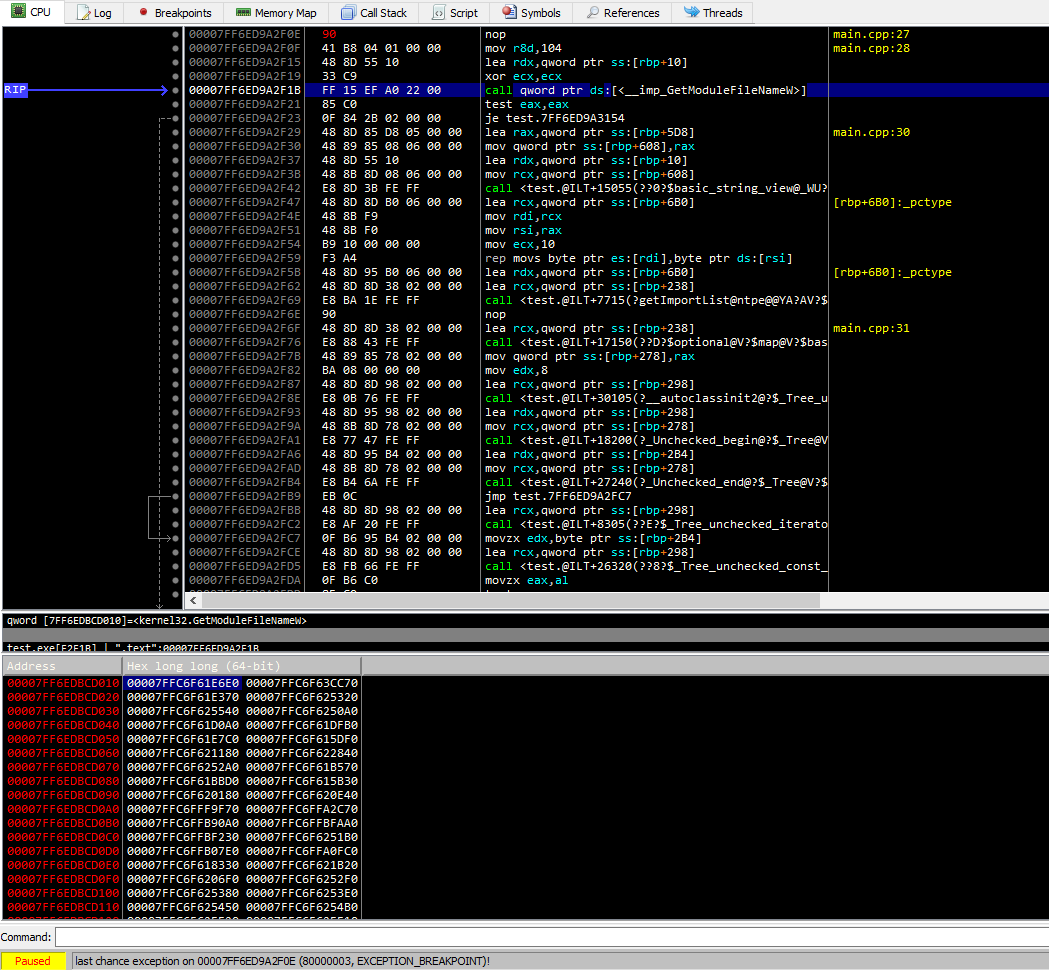
Somit muss der Systemlader, um eine Funktion aus einer Bibliothek aufrufen zu können, nur einmal die Adresse dieser Funktion an einer Stelle im Abbild schreiben.
C++ PARSER
Und jetzt werden wir den einfachsten Parser (kompatibel mit x86 und x64) der Importtabelle der ausführbaren Datei schreiben!
#include "stdafx.h"
/*
*
* Copyright (C) 2022, SToFU Systems S.L.
* All rights reserved.
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation; either version 2 of the License, or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License along
* with this program; if not, write to the Free Software Foundation, Inc.,
* 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
*
*/
namespace ntpe
{
static constexpr uint64_t g_kRvaError = -1;
// These types is defined in NTPEParser.h
// typedef std::map< std::string, std::set< std::string >> IMPORT_LIST;
// typedef std::vector< IMAGE_SECTION_HEADER > SECTIONS_LIST;
//**********************************************************************************
// FUNCTION: alignUp(DWORD value, DWORD align)
//
// ARGS:
// DWORD value - value to align.
// DWORD align - alignment.
//
// DESCRIPTION:
// Aligns argument value with the given alignment.
//
// Documentation links:
// Alignment: https://learn.microsoft.com/en-us/cpp/cpp/alignment-cpp-declarations?view=msvc-170
//
// RETURN VALUE:
// DWORD aligned value.
//
//**********************************************************************************
DWORD alignUp(DWORD value, DWORD align)
{
DWORD mod = value % align;
return value + (mod ? (align - mod) : 0);
};
//**********************************************************************************
// FUNCTION: rva2offset(IMAGE_NTPE_DATA& ntpe, DWORD rva)
//
// ARGS:
// IMAGE_NTPE_DATA& ntpe - data from PE file.
// DWORD rva - relative virtual address.
//
// DESCRIPTION:
// Parse RVA (relative virtual address) to offset.
//
// RETURN VALUE:
// int64_t offset.
// g_kRvaError (-1) in case of error.
//
//**********************************************************************************
int64_t rva2offset(IMAGE_NTPE_DATA& ntpe, DWORD rva)
{
/* retrieve first section */
try
{
/* if rva is inside MZ header */
PIMAGE_SECTION_HEADER sec = ntpe.sectionDirectories;
if (!ntpe.fileHeader->NumberOfSections || rva < sec->VirtualAddress)
return rva;
/* walk on sections */
for (uint32_t sectionIndex = 0; sectionIndex < ntpe.fileHeader->NumberOfSections; sectionIndex++, sec++)
{
/* count section end and allign it after each iteration */
DWORD secEnd = ntpe::alignUp(sec->Misc.VirtualSize, ntpe.SecAlign) + sec->VirtualAddress;
if (sec->VirtualAddress <= rva && secEnd > rva)
return rva - sec->VirtualAddress + sec->PointerToRawData;
};
}
catch (std::exception&)
{
}
return g_kRvaError;
};
//**********************************************************************************
// FUNCTION: getNTPEData(char* fileMapBase)
//
// ARGS:
// char* fileMapBase - the starting address of the mapped file.
//
// DESCRIPTION:
// Parses following data from mapped PE file.
//
// Documentation links:
// PE format structure: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format
//
// RETURN VALUE:
// std::optional< IMAGE_NTPE_DATA >.
// std::nullopt in case of error.
//
//**********************************************************************************
#define initNTPE(HeaderType, cellSize) \
{ \
char* ntstdHeader = (char*)fileHeader + sizeof(IMAGE_FILE_HEADER); \
HeaderType* optHeader = (HeaderType*)ntstdHeader; \
data.sectionDirectories = (PIMAGE_SECTION_HEADER)(ntstdHeader + sizeof(HeaderType)); \
data.SecAlign = optHeader->SectionAlignment; \
data.dataDirectories = optHeader->DataDirectory; \
data.CellSize = cellSize; \
}
std::optional< IMAGE_NTPE_DATA > getNTPEData(char* fileMapBase, uint64_t fileSize)
{
try
{
/* PIMAGE_DOS_HEADER from starting address of the mapped view*/
PIMAGE_DOS_HEADER dosHeader = (IMAGE_DOS_HEADER*)fileMapBase;
/* return std::nullopt in case of no IMAGE_DOS_SIGNATUR signature */
if (dosHeader->e_magic != IMAGE_DOS_SIGNATURE)
return std::nullopt;
/* PE signature adress from base address + offset of the PE header relative to the beginning of the file */
PDWORD peSignature = (PDWORD)(fileMapBase + dosHeader->e_lfanew);
if ((char*)peSignature <= fileMapBase || (char*)peSignature - fileMapBase >= fileSize)
return std::nullopt;
/* return std::nullopt in case of no PE signature */
if (*peSignature != IMAGE_NT_SIGNATURE)
return std::nullopt;
/* file header address from PE signature address */
PIMAGE_FILE_HEADER fileHeader = (PIMAGE_FILE_HEADER)(peSignature + 1);
if (fileHeader->Machine != IMAGE_FILE_MACHINE_I386 &&
fileHeader->Machine != IMAGE_FILE_MACHINE_AMD64)
return std::nullopt;
/* result IMAGE_NTPE_DATA structure with info from PE file */
IMAGE_NTPE_DATA data = {};
/* base address and File header address assignment */
data.fileBase = fileMapBase;
data.fileHeader = fileHeader;
/* addresses of PIMAGE_SECTION_HEADER, PIMAGE_DATA_DIRECTORIES, SectionAlignment, CellSize depending on processor architecture */
switch (fileHeader->Machine)
{
case IMAGE_FILE_MACHINE_I386:
initNTPE(IMAGE_OPTIONAL_HEADER32, 4);
return data;
case IMAGE_FILE_MACHINE_AMD64:
initNTPE(IMAGE_OPTIONAL_HEADER64, 8);
return data;
}
}
catch (std::exception&)
{
}
return std::nullopt;
}
//**********************************************************************************
// FUNCTION: getImportList(IMAGE_NTPE_DATA& ntpe)
//
// ARGS:
// IMAGE_NTPE_DATA& ntpe - data from PE file.
//
// DESCRIPTION:
// Retrieves IMPORT_LIST(std::map< std::string, std::set< std::string >>) with all loaded into PE libraries names and imported functions.
// Map key: loaded dll's names.
// Map value: set of imported functions names.
//
// Documentation links:
// Import Directory Table: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#import-directory-table
//
// RETURN VALUE:
// std::optional< IMPORT_LIST >.
// std::nullopt in case of error.
//
//**********************************************************************************
std::optional< IMPORT_LIST > getImportList(IMAGE_NTPE_DATA& ntpe)
{
try
{
/* if no imaage import directory in file returns std::nullopt */
if (ntpe.dataDirectories[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress == 0)
return std::nullopt;
IMPORT_LIST result;
/* import table offset */
DWORD impOffset = rva2offset(ntpe, ntpe.dataDirectories[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress);
/* imoprt table descriptor from import table offset + file base adress */
PIMAGE_IMPORT_DESCRIPTOR impTable = (PIMAGE_IMPORT_DESCRIPTOR)(impOffset + ntpe.fileBase);
/* while names in import table */
while (impTable->Name != 0)
{
/* pointer to DLL name from offset of current section name + file base adress */
std::string modname = rva2offset(ntpe, impTable->Name) + ntpe.fileBase;
std::transform(modname.begin(), modname.end(), modname.begin(), ::toupper);
/* start adress of names in look up table from import table name RVA */
char* cell = ntpe.fileBase + ((impTable->OriginalFirstThunk) ? rva2offset(ntpe, impTable->OriginalFirstThunk) : rva2offset(ntpe, impTable->FirstThunk));
/* while names in look up table */
for (;; cell += ntpe.CellSize)
{
int64_t rva = 0;
/* break if rva = 0 */
memcpy(&rva, cell, ntpe.CellSize);
if (!rva)
break;
/* if rva > 0 function was imported by name. if rva < 0 function was imported by ordinall */
if (rva > 0)
result[modname].emplace(ntpe.fileBase + rva2offset(ntpe, rva) + 2);
else
result[modname].emplace(std::string("#ord: ") + std::to_string(rva & 0xFFFF));
};
impTable++;
};
return result;
}
catch (std::exception&)
{
return std::nullopt;
}
};
//**********************************************************************************
// FUNCTION: getImportList(IMAGE_NTPE_DATA& ntpe)
//
// ARGS:
// std::wstring_view filePath - path to file.
//
// DESCRIPTION:
// Retrieves IMPORT_LIST(std::map< std::string, std::set< std::string >>) with all loaded into PE libraries names and imported functions bu path.
// Map key: loaded dll's names.
// Map value: set of imported functions names.
//
// Documentation links:
// Import Directory Table: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#import-directory-table
//
// RETURN VALUE:
// std::optional< IMPORT_LIST >.
// std::nullopt in case of error.
//
//**********************************************************************************
std::optional< IMPORT_LIST > getImportList(std::wstring_view filePath)
{
std::vector< char > buffer;
/* obtain base address of mapped file from tools::readFile function */
bool result = tools::readFile(filePath, buffer);
/* return nullopt if readFile failes or obtained buffer is empty */
if (!result || buffer.empty())
return std::nullopt;
/* get IMAGE_NTPE_DATA from base address of mapped file */
std::optional< IMAGE_NTPE_DATA > ntpe = getNTPEData(buffer.data(), buffer.size());
if (!ntpe)
return std::nullopt;
/* return result of overloaded getImportList function with IMAGE_NTPE_DATA as argument */
return getImportList(*ntpe);
}
//**********************************************************************************
// FUNCTION: getSectionsList(IMAGE_NTPE_DATA& ntpe)
//
// ARGS:
// IMAGE_NTPE_DATA& ntpe - data from PE file.
//
// DESCRIPTION:
// Retrieves SECTIONS_LIST from IMAGE_NTPE_DATA.
// SECTIONS_LIST - vector of sections headers from portable executable file.
// Sections names exmaple: .data, .code, .src
//
// Documentation links:
// IMAGE_SECTION_HEADER: https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_section_header
// Section Table (Section Headers): https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#section-table-section-headers
//
// RETURN VALUE:
// std::optional< SECTIONS_LIST >.
// std::nullopt in case of error.
//
//**********************************************************************************
std::optional< SECTIONS_LIST > getSectionsList(IMAGE_NTPE_DATA& ntpe)
{
try
{
/* result vector of section directories */
SECTIONS_LIST result;
/* iterations through all image section headers poiners in IMAGE_NTPE_DATA structure */
for (uint64_t sectionIndex = 0; sectionIndex < ntpe.fileHeader->NumberOfSections; sectionIndex++)
{
/* pushing IMAGE_SECTION_HEADER from iamge section headers */
result.push_back(ntpe.sectionDirectories[sectionIndex]);
}
return result;
}
catch (std::exception&)
{
}
/* returns nullopt in case of error */
return std::nullopt;
}
}
Sie finden den Code des gesamten Projekts auf unserem Github:
https://github.com/SToFU-Systems/DSAVE
Liste der verwendeten Werkzeuge
- PE Tools: https://github.com/petoolse/petools Dies ist ein Open-Source-Tool zur Manipulation von PE-Headerfeldern. Unterstützt x86- und x64-Dateien.
- WinDbg: https://learn.microsoft.com/en-us/windows-hardware/drivers/debugger/debugger-download-tools Microsofts System-Debugger. Unverzichtbar für die Arbeit eines Systemprogrammierers für Windows OS.
- x64Dbg: https://x64dbg.com Einfacher, leichtgewichtiger Open-Source-x64/x86-Debugger für Windows.
- WinHex: http://www.winhex.com/winhex/hex-editor.html WinHex ist ein universeller Hex-Editor, besonders hilfreich im Bereich der Computerforensik, Datenwiederherstellung und Bearbeitung von Niederstufendaten.
WAS KOMMT ALS NÄCHSTES?
Wir schätzen Ihre Unterstützung und freuen uns auf Ihre weiterhin aktive Beteiligung in unserer Gemeinschaft
Im nächsten Artikel werden wir zusammen mit Ihnen das Fuzzy-Hashing-Modul schreiben und die Frage der Schwarz- und Weißlisten einfachsten Importtabellenanalysator behandeln.
Alle Fragen an die Autoren des Artikels können per E-Mail gesendet werden an: articles@stofu.io
Danke für Ihre Aufmerksamkeit und haben Sie einen schönen Tag!




