Hash
Først og fremmest, lad os gennemgå det grundlæggende og blive bekendt med sådan et begreb som en hash!
Hash-algoritme - er en matematisk funktion, der tager data af enhver størrelse og producerer en output kaldet en hash eller meddelelsesdigest.
Outputtet er en unik repræsentation af indgangsdataene, som kan bruges til at verificere, at dataene ikke er blevet manipuleret med. Hash-algoritmer bruges til at sikre integriteten og ægtheden af data. Simpelt sagt er en hash et unikt digitalt fingeraftryk af et stykke data. Det er som en kode, der repræsenterer dataene. Koden genereres af en matematisk funktion kaldet en hash-funktion. Hvis dataene ændres bare en lille smule, vil hashen være anderledes.
Der er primære nøglekarakteristika for hash:
-
Deterministisk: En hash-funktion bør altid producere det samme output for en given indgang. Dette betyder, at hvis du hasher de samme data to gange, bør du få den samme hash-værdi begge gange.
-
Uomvendelighed: Det bør være beregningsmæssigt umuligt at rekonstruere de oprindelige indgangsdata fra dens hash-værdi. Denne egenskab er vigtig for sikkerhed, da den beskytter de oprindelige data fra at blive opdaget af angribere, der kun har adgang til hash-værdien.
-
Ensartethed: En hash-funktion bør producere en ensartet fordeling af hash-værdier på tværs af alle mulige indgange. Dette betyder, at hver hash-værdi bør være lige sandsynlig at forekomme, og der bør ikke være mønstre eller skævheder i fordelingen af hash-værdier.
-
Uforudsigelighed: Det bør være beregningsmæssigt umuligt at forudsige hash-værdien af en indgang baseret på hash-værdierne af andre indgange eller egenskaberne ved hash-funktionen selv. Denne egenskab er vigtig for sikkerhed, da den gør det svært for angribere at skabe en kollision (to forskellige indgange, der producerer den samme hash-værdi).
-
Modstandsdygtighed mod kollisionsangreb: En hash-funktion bør være modstandsdygtig over for kollisionsangreb, som involverer at finde to forskellige indgange, der producerer den samme hash-værdi. Kollisionsangreb kan bruges til at skabe falske digitale signaturer eller til at omgå adgangskontrol, så det er vigtigt, at en hash-funktion er designet til at modstå dem.
Andre karakteristika for hashes kan du finde på Wikipedia-siden:
https://en.wikipedia.org/wiki/Hash_function
Datakontrol. Sortliste og Hvidliste.Datakontrol. Sortliste og Hvidliste.
I sammenhæng med antivirussoftware anvendes hash-algoritmer til at detektere malware eller udelukke falsk-positive alarmer. Antivirussoftware opretholder en database med kendte malware hashes (sortliste) og betroede software hashes (hvidliste). Når en fil skannes, sammenlignes dens hash med hashene i databasen. De mest almindeligt anvendte hash-algoritmer til datakontrol er MD5, SHA-1, SHA-256 og SHA-512.
Brugen af hashes i antivirus' sortlister og hvidlister hjælper med at fremskynde scanningprocessen, da antivirusprogrammet ikke behøver at udføre en detaljeret analyse af hver fil for at afgøre, om den er ondsindet eller ej. I stedet kan det sammenligne filernes hash-værdier med dem på sortlisten/hvidlisten for hurtigt at identificere kendte trusler eller betroede apps.
Sortliste. I sammenhængen af cybersikkerhed og antivirussoftware er en sortliste en liste over kendte ondsindede filer eller dele af disse filer. Når et antivirusprogram scanner en computer eller et netværk, sammenligner det de filer og enheder, det støder på, med sortlisten for at identificere eventuelle trusler. Hvis en fil eller enhed matcher en post på sortlisten, vil antivirusprogrammet træffe foranstaltninger for at fjerne eller karantæne det for at forhindre, at det forårsager skade.
Selvom sortlister kan være nyttige til at opdage og forhindre kendte trusler, er de ikke altid effektive til at beskytte mod nye og ukendte trusler. Angribere kan bruge forskellige teknikker, såsom forklædning eller polymorfisme, til at ændre koden eller adfærden for en fil eller enhed for at undgå detektion af antivirusprogrammer.
Derfor anvender antivirusprogrammer ofte en kombination af teknikker, såsom hvidlistning og adfærdsbaseret detektion, for at supplere brugen af sortlister og tilbyde mere omfattende beskyttelse mod et bredere spektrum af trusler.
Hvidliste. I sammenhængen af cybersikkerhed og antivirussoftware er en hvidliste en liste over betroede filer, der er kendt for at være sikre. Hvis en fil eller enhed matcher en post på hvidlisten, vil antivirusprogrammet tillade den at åbne/køre uden at træffe nogen foranstaltninger, da den betragtes som sikker.
Hvidlister er nyttige til at forhindre falske positiver i antivirus- og sikkerhedsprogrammer. Falske positiver opstår, når et program eller en fil markeres som ondsindet eller skadelig, når det faktisk er sikkert. Ved at bruge en hvidliste kan sikkerhedsprogrammer omgå disse falske positiver, hvilket kan spare tid og forhindre unødvendige alarmer.
Brugen af hashes og sort-/hvidlister kan være en effektiv måde at beskytte mod kendte trusler og forhindre falske positiver i antivirus- og sikkerhedsprogrammer.
I sammenhæng med antivirussoftware anvendes hash-algoritmer til at detektere malware eller udelukke falsk-positive alarmer. Antivirussoftware opretholder en database med kendte malware hashes (sortliste) og betroede software hashes (hvidliste). Når en fil skannes, sammenlignes dens hash med hashene i databasen. De mest almindeligt anvendte hash-algoritmer til datakontrol er MD5, SHA-1, SHA-256 og SHA-512.
Brugen af hashes i antivirus' sortlister og hvidlister hjælper med at fremskynde scanningprocessen, da antivirusprogrammet ikke behøver at udføre en detaljeret analyse af hver fil for at afgøre, om den er ondsindet eller ej. I stedet kan det sammenligne filernes hash-værdier med dem på sortlisten/hvidlisten for hurtigt at identificere kendte trusler eller betroede apps.
Sortliste. I sammenhængen af cybersikkerhed og antivirussoftware er en sortliste en liste over kendte ondsindede filer eller dele af disse filer. Når et antivirusprogram scanner en computer eller et netværk, sammenligner det de filer og enheder, det støder på, med sortlisten for at identificere eventuelle trusler. Hvis en fil eller enhed matcher en post på sortlisten, vil antivirusprogrammet træffe foranstaltninger for at fjerne eller karantæne det for at forhindre, at det forårsager skade.
Selvom sortlister kan være nyttige til at opdage og forhindre kendte trusler, er de ikke altid effektive til at beskytte mod nye og ukendte trusler. Angribere kan bruge forskellige teknikker, såsom forklædning eller polymorfisme, til at ændre koden eller adfærden for en fil eller enhed for at undgå detektion af antivirusprogrammer.
Derfor anvender antivirusprogrammer ofte en kombination af teknikker, såsom hvidlistning og adfærdsbaseret detektion, for at supplere brugen af sortlister og tilbyde mere omfattende beskyttelse mod et bredere spektrum af trusler.
Hvidliste. I sammenhængen af cybersikkerhed og antivirussoftware er en hvidliste en liste over betroede filer, der er kendt for at være sikre. Hvis en fil eller enhed matcher en post på hvidlisten, vil antivirusprogrammet tillade den at åbne/køre uden at træffe nogen foranstaltninger, da den betragtes som sikker.
Hvidlister er nyttige til at forhindre falske positiver i antivirus- og sikkerhedsprogrammer. Falske positiver opstår, når et program eller en fil markeres som ondsindet eller skadelig, når det faktisk er sikkert. Ved at bruge en hvidliste kan sikkerhedsprogrammer omgå disse falske positiver, hvilket kan spare tid og forhindre unødvendige alarmer.
Brugen af hashes og sort-/hvidlister kan være en effektiv måde at beskytte mod kendte trusler og forhindre falske positiver i antivirus- og sikkerhedsprogrammer.
Hvorfor bruger antivirusprogrammer flere hash-algoritmer?Hvorfor bruger antivirusprogrammer flere hash-algoritmer?
Antivirusprogrammer bruger flere hash-algoritmer af flere årsager:
-
Sikkerhed mod kollisionsangreb: Mens sortlister kan være effektive til at opdage og forhindre kendte trusler, er de ikke fejlfri. Angribere kan bruge forskellige teknikker til at undgå detektion, såsom at ændre data for at undgå at matche signaturerne på sortlisten. Disse teknikker kaldes "kollisionsangreb". Et kollisionsangreb er en type kryptografisk angreb, hvor en angriber forsøger at finde to forskellige inputs, såsom filer eller beskeder, der producerer den samme hash-værdi, når de kører gennem en hash-funktion (kollision). Målet med et kollisionsangreb er at skabe et par inputs, der kan bruges til at underminere et system, der er afhængigt af hash-værdiernes integritet, såsom digitale signaturer, adgangskodegodkendelse eller dataintegritetskontroller. Hvis en angriber kan finde en kollision, kan han bruge den til at omgå de sikkerhedsforanstaltninger, der er afhængige af hash-funktionen. For at mindske risikoen for kollisionsangreb bruger antivirusprogrammer stærke hash-funktioner, der er resistente over for angreb, og anvender flere hash-funktioner samtidigt. For eksempel, hvis et antivirusprogram kun brugte MD5-hash-algoritmen, kunne en angriber potentielt skabe en ondsindet fil, der har den samme MD5-hash som en legitim fil og narre antivirusprogrammet til at behandle den ondsindede fil som sikker. Ved at bruge flere hash-algoritmer, såsom MD5, SHA-1 og SHA-256, gøres det mere vanskeligt for en angriber at skabe et kollisionsangreb, der ville virke mod alle algoritmerne på samme tid.
-
Effektivitet: Forskellige hash-algoritmer har forskellige beregningskrav, og nogle kan være mere effektive end andre afhængigt af filstørrelse, type eller andre faktorer. Ved at bruge flere hash-algoritmer tillader antivirusprogrammer at vælge den mest passende algoritme for en given situation, hvilket kan spare tid og behandlingskraft. For eksempel kan SHA-256 være mere beregningskrævende end MD5, så et antivirusprogram kan vælge at bruge MD5 for mindre filer og SHA-256 for større filer.
-
Fleksibilitet: Forskellige hash-algoritmer er designet til forskellige brugsområder og applikationer. Ved at bruge flere hash-algoritmer kan antivirusprogrammer tilpasse sig forskellige behov og scenarier, såsom at detektere malware, verificere filintegritet eller detektere manipulering eller ændring. For eksempel kan en retsmedicinsk undersøger bruge en anden hash-algoritme end et antivirusprogram for at sikre, at data ikke er blevet modificeret under en undersøgelse.
Brugen af flere hash-algoritmer er en bedste praksis i cybersikkerhed og udvikling af antivirussoftware, da det giver robusthed, kompatibilitet, effektivitet og fleksibilitet i detektion og forebyggelse af cybertrusler.
Hvordan genkender antivirusprogrammer lignende, men ikke identiske data og filer?Hvordan genkender antivirusprogrammer lignende, men ikke identiske data og filer?
Lignende, men ikke identiske filer kan være et problem i cybersikkerhed, fordi de kan bruges af angribere til at undgå detektion af antivirussoftware.
For eksempel kan en angriber tage en kendt malwarefil og foretage små ændringer i dens kode eller struktur, såsom at ændre variabelnavne eller omarrangere instruktioner. Disse ændringer kan være nok til at skabe en ny fil, der er lignende, men ikke identisk med den oprindelige malwarefil, og som muligvis ikke opdages af antivirussoftware, der er afhængig af traditionelle hash-baserede detektionsmetoder.
Desuden kan angribere bruge lignende, men ikke identiske filer til at skabe polymorfisk malware, der kan ændre sin kode eller struktur ved hver infektion for at undgå detektion. Polymorfisk malware kan være meget svær at opdage ved hjælp af traditionelle antivirus-teknikker, der er afhængige af at genkende specifikke mønstre eller signaturer i malwarekoden.
For at løse dette problem anvender antivirusprogrammer fuzzy hashes.
Fuzzy hashing er en teknik, der bruges af noget antivirussoftware til at opdage lignende, men ikke identiske filer, herunder polymorfisk malware. Ved at opdele en fil i mindre stykker og sammenligne hashes af disse stykker med dem fra andre filer, kan fuzzy hashing identificere filer, der har lignende kode eller struktur, selvom de ikke er identiske.
Fuzzy hashing fungerer ved at identificere sekvenser af bytes, der optræder ofte i hele filen. Disse sekvenser, også kendt som "chunks", hashes derefter ved hjælp af en kryptografisk hashfunktion for at generere en hash-værdi. Hash-værdierne for chunks'ene sammenlignes derefter med dem fra andre filer for at identificere lignende chunks.
Fordelen ved fuzzy hashing er, at den kan opdage ligheder, selv når filer er blevet modificeret eller skjult, hvilket gør det til et kraftfuldt værktøj til at identificere varianter af kendt malware. For eksempel, hvis en angriber ændrer en kendt malwarefil ved at ændre navnene på variabler eller funktioner, kan traditionelle hash-baserede detektionsmetoder måske ikke opdage den modificerede fil. Fuzzy hashing kan dog stadig opdage den modificerede fil ved at identificere chunks, der ligner dem i den oprindelige malwarefil. I modsætning til kryptografiske hashalgoritmer som MD5, SHA-1 eller SHA-512 producerer fuzzy hash-algoritmer variable længder af hash-værdier, der er baseret på ligheden af indgangsdataene.
Fordele ved fuzzy hashes:
-
Detektion af lignende filer: Fuzzy hashes kan opdage lignende filer, selv hvis de er blevet let modificeret, hvilket er nyttigt til at identificere varianter af kendt malware.
-
Reduceret antal falske positiver: Fuzzy hashes kan reducere antallet af falske positiver genereret af traditionelle hash-baserede detektionsmetoder. Dette skyldes, at fuzzy hashes kan opdage filer, der er lignende, men ikke identiske med kendt malware.
-
Modstandsdygtighed over for forklædning: Fuzzy hashes er mere modstandsdygtige over for forklædningsteknikker, som angribere bruger til at undgå detektion. Dette skyldes, at fuzzy hashing-algoritmen opdeler filen i mindre stykker og genererer hashes for hvert stykke, hvilket gør det sværere for en angriber at modificere filen på en måde, der undgår detektion.
Fuzzy hashing har nogle begrænsninger, der kan påvirke effektiviteten i at opdage lignende, men ikke identiske filer:
-
Falske positiver: Fuzzy hashing kan producere falske positiver, hvor legitime filer mærkes som ondsindede, fordi de har lignende kode eller struktur til kendt malware. Dette kan ske, hvis filerne deler almindelige biblioteker eller rammer.
-
Ydelse: Fuzzy hashing kan være beregningsmæssigt intensiv, især for store filer. Dette kan sænke scanningprocessen og påvirke systemets ydeevne.
-
Størrelsesbegrænsninger: Fuzzy hashing fungerer muligvis ikke godt på meget små filer eller filer med lav entropi, da der muligvis ikke er nok unikke chunks til at generere meningsfulde hashes.
-
Manipulation: Fuzzy hashing er muligvis ikke effektiv, hvis en angriber specifikt målretter den og modificerer en fil for at undgå detektion. For eksempel kunne en angriber bevidst ændre strukturen på en fil for at forhindre, at den bliver identificeret af fuzzy hashing.
Hvad er forskellen mellem kryptografiske hash-algoritmer og fuzzy hash-algoritmer?Hvad er forskellen mellem kryptografiske hash-algoritmer og fuzzy hash-algoritmer?
Kryptografiske hash-algoritmer og fuzzy hash-algoritmer bruges begge i cybersikkerhed, men de har forskellige formål og karakteristika.
Kryptografiske hash-algoritmer, såsom SHA-256 og MD5, er designet til at sikre dataintegritet og autenticitet ved at generere fastlængde, unikke hash-værdier, der er næsten umulige at rekonstruere. Kryptografiske hash-algoritmer anvendes til at verificere dataintegriteten.
Fuzzy hash-algoritmer, såsom SSDEEP, er designet til at identificere lignende, men ikke identiske data, såsom filer, der er blevet modificeret eller ompakket af malware-forfattere. Fuzzy hashing bruger en glidende vinduesteknik til at opdele data i små stykker og generere variabel-længde, sandsynlighedsbaserede hashes, der sammenlignes med en database af kendte malware-hashes for at identificere potentielt ondsindede filer.
Kryptografiske hash-algoritmer er designet til at være kollisionsresistente, hvilket betyder, at det er ekstremt svært at finde to inputs, der producerer det samme hash-output. Fuzzy hash-algoritmer behøver ikke at være kollisionsresistente, da de er designet til at detektere ligheder mellem filer snarere end at producere unikke hash-outputs.
Den primære forskel mellem kryptografiske hash-algoritmer og fuzzy hash-algoritmer er deres grad af determinisme. Kryptografiske hash-algoritmer producerer fastlængde, deterministiske hashes, der er unikke for hvert input, mens fuzzy hash-algoritmer producerer variabel-længde, sandsynlighedsbaserede hashes, der er lignende for lignende inputs.
Hvilke fuzzy hashing-algoritmer vil vi bruge i vores løsning?
I vores løsning vil vi bruge SSDEEP og TLSH.
ssdeep er en fuzzy hashing-algoritme, der bruges til at identificere lignende, men ikke identiske data, såsom malwarevarianter. Den fungerer ved at generere en hash-værdi, der repræsenterer ligheden af indgangsdataene, snarere end en unik identifikator som kryptografiske hashfunktioner. Outputtet fra ssdeep er variabel-længde og sandsynlighedsbaseret, hvilket gør det muligt at opdage selv mindre forskelle mellem to filer. ssdeep anvendes almindeligt i malwareanalyse og detektion og er også integreret i forskellige sikkerhedsværktøjer og antivirussoftware.
TLSH (Trend Micro Locality Sensitive Hash) er en fuzzy hashing-algoritme, der bruges til at identificere lignende, men ikke identiske data, såsom malwarevarianter. Den fungerer ved at skabe en hash-værdi, der fanger de unikke egenskaber ved indgangsdataene, såsom bytefrekvens og orden. Outputtet fra TLSH er variabel-længde og sandsynlighedsbaseret, hvilket gør det muligt at opdage ligheder, selvom indgangsdataene er blevet modificeret eller skjult. TLSH anvendes almindeligt i malwareanalyse og detektion og er også integreret i forskellige sikkerhedsværktøjer og antivirussoftware.
ssdeep og TLSH bruger begge afstandsmetrikker til at bestemme ligheden mellem to hash-værdier. Dog er de afstandsmetrikker, der bruges af ssdeep og TLSH, forskellige.
ssdeep bruger "fuzzy hash distance"-metrikken til at beregne afstanden mellem to hash-værdier. Denne afstandsmetrik er baseret på antallet af matchende og ikke-matchende blokke mellem de to hashes, samt størrelsen på hashes. Afstandsmetrikken er en procentværdi, der varierer fra 0 til 100, hvor 0 betyder, at de to hashes er identiske, og 100 betyder, at de to hashes er helt forskellige.
TLSH, på den anden side, bruger "total diff"-metrikken til at beregne afstanden mellem to hash-værdier. Denne afstandsmetrik er baseret på forskellen mellem de lokalitetssensitive egenskaber ved de to indgangsdatasæt. Outputtet af "total diff"-metrikken er en værdi mellem 0 og 1000, hvor 0 betyder, at de to hash-værdier er identiske, og 1000 betyder, at de to hash-værdier er helt forskellige.
Opbygning af hash-modulen
For vores løsning vil vi bruge open source-biblioteker:
1. PolarSSL: https://polarssl.org/
PolarSSL er et gratis og open source-softwarebibliotek til implementering af kryptografiske protokoller såsom Transport Layer Security (TLS), Secure Sockets Layer (SSL), Datagram Transport Layer Security (DTLS). Det tilbyder forskellige kryptografiske algoritmer og protokoller, herunder hashfunktioner, symmetrisk og asymmetrisk kryptering, digitale signaturer og nøgleudvekslingsalgoritmer. PolarSSL er designet til at være letvægt og effektivt, hvilket gør det velegnet til brug i ressourcebegrænsede miljøer.
2. ssdeep: http://ssdeep.sf.net/
3. TLSH: https://github.com/trendmicro/tlsh/
Efter implementering af bibliotekerne i projektet tilføjer vi en simpel kode:
struct HashData
{
BYTE md5[16];
BYTE sha1[20];
BYTE sha512[64];
std::string ssdeep;
std::string tlsh;
};
HashData hash(const void* buff, uint64_t size)
{
HashData snap = {};
hashes::md5(buff, size, snap.md5);
hashes::sha1(buff, size, snap.sha1);
hashes::sha4(buff, size, snap.sha512);
snap.ssdeep = hashes::ssdeepHash(buff, size);
snap.tlsh = hashes::tlshHash(buff, size);
return snap;
}

Kontrol af hash-modulen
Det er tid til at teste hash-modulen! For at gøre dette vil vi oprette en tekstfil med følgende indhold:
All the World`s a Stage by William Shakespeare
All the world`s a stage,
And all the men and women merely players;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first, the infant,
Mewling and puking in the nurse`s arms.
Then the whining schoolboy, with his satchel
And shining morning face, creeping like snail
Unwillingly to school. And then the lover,
Sighing like furnace, with a woeful ballad
Made to his mistress` eyebrow. Then a soldier,
Full of strange oaths and bearded like the pard,
Jealous in honor, sudden and quick in quarrel,
Seeking the bubble reputation
Even in the cannon`s mouth. And then the justice,
In fair round belly with good capon lined,
With eyes severe and beard of formal cut,
Full of wise saws and modern instances;
And so he plays his part. The sixth age shifts
Into the lean and slippered pantaloon,
With spectacles on nose and pouch on side;
His youthful hose, well saved, a world too wide
For his shrunk shank, and his big manly voice,
Turning again toward childish treble, pipes
And whistles in his sound. Last scene of all,
That ends this strange eventful history,
Is second childishness and mere oblivion,
Sans teeth, sans eyes, sans taste, sans everything.
TEST 1: Opret to identiske filer med det samme indhold (teksten ovenfor) og beregn hashes.
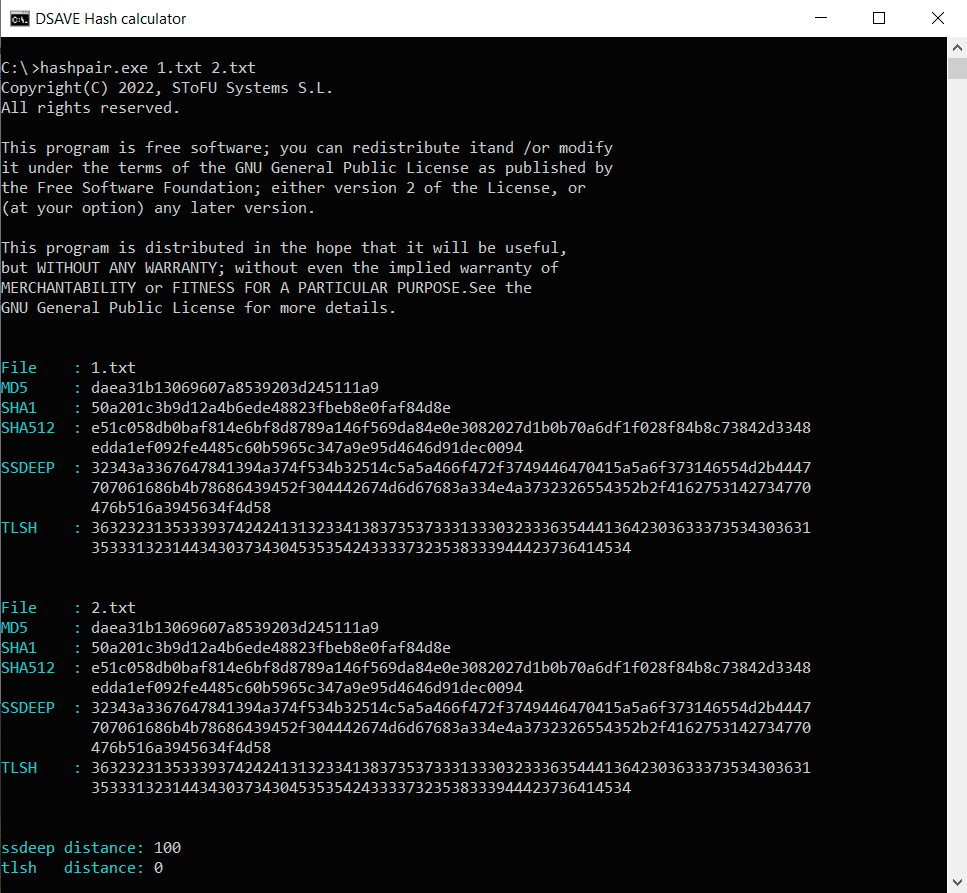
SSDEEP siger, at filerne er 100% identiske. TLSH siger, at der er 0% forskelle mellem filerne.
TEST 2: Opret to identiske filer med det samme indhold, foretag ændringer i den anden fil og beregn hashes
Indhold af den anden fil:
All the World`s a Stage by William Shakespeare
O lovely maidens, fall in love,
But not with Muscovites,
For Muscovites are foreign folk,
They do not treat you right.
A Muscovite will love for sport,
And laughing go away;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first, the infant,
Mewling and puking in the nurse`s arms.
Then the whining schoolboy, with his satchel
And shining morning face, creeping like snail
Unwillingly to school. And then the lover,
Sighing like furnace, with a woeful ballad
Made to his mistress` eyebrow. Then a soldier,
Full of strange oaths and bearded like the pard,
Jealous in honor, sudden and quick in quarrel,
Seeking the bubble reputation
Even in the cannon`s mouth. And then the justice,
In fair round belly with good capon lined,
With eyes severe and beard of formal cut,
Full of wise saws and modern instances;
And so he plays his part. The sixth age shifts
Into the lean and slippered pantaloon,
With spectacles on nose and pouch on side;
His youthful hose, well saved, a world too wide
For his shrunk shank, and his big manly voice,
Turning again toward childish treble, pipes
And whistles in his sound. Last scene of all,
That ends this strange eventful history,
Is second childishness and mere oblivion,
Sans teeth, sans eyes, sans taste, sans everything.
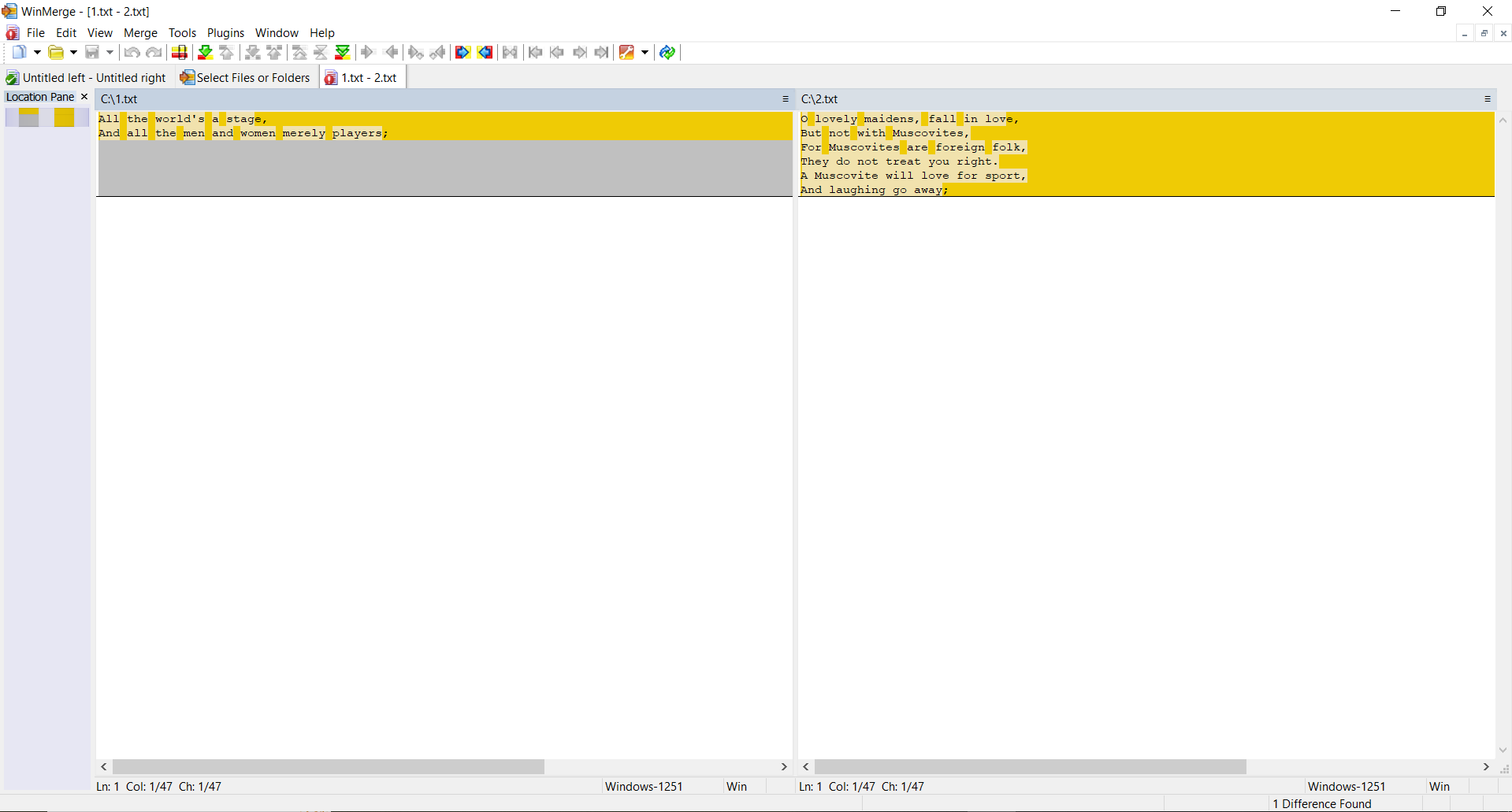
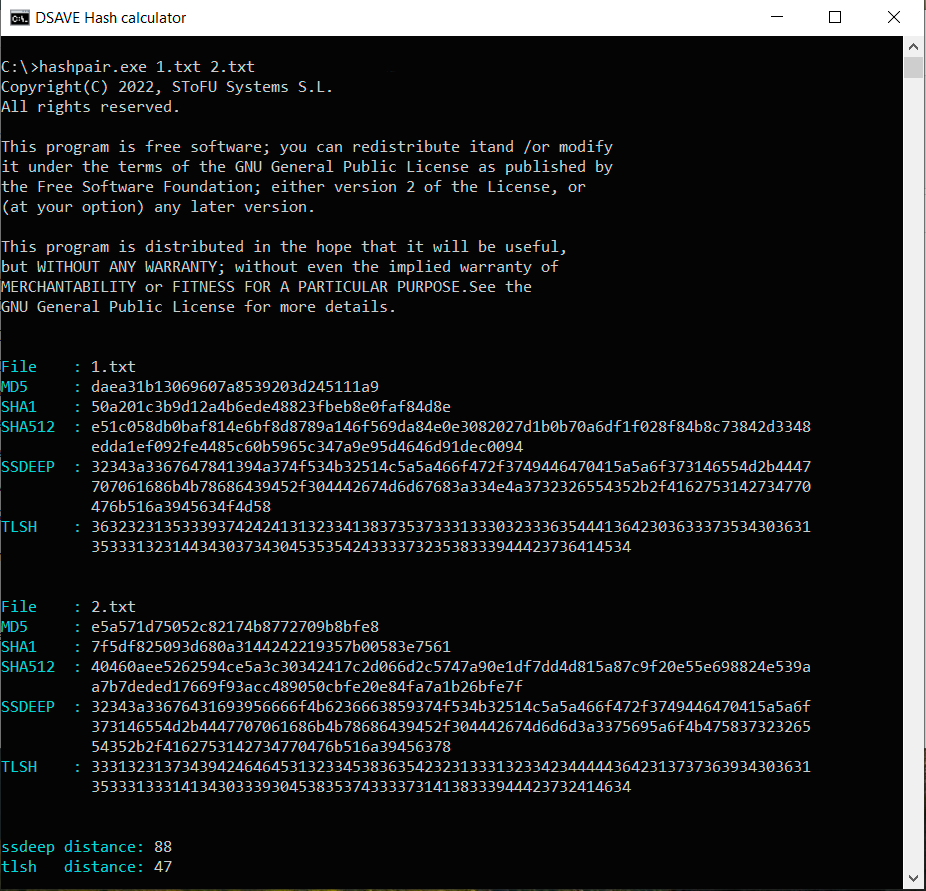
SSDEEP siger, at filerne er 88% identiske. TLSH siger, at der er 4,7% forskelle mellem filerne.
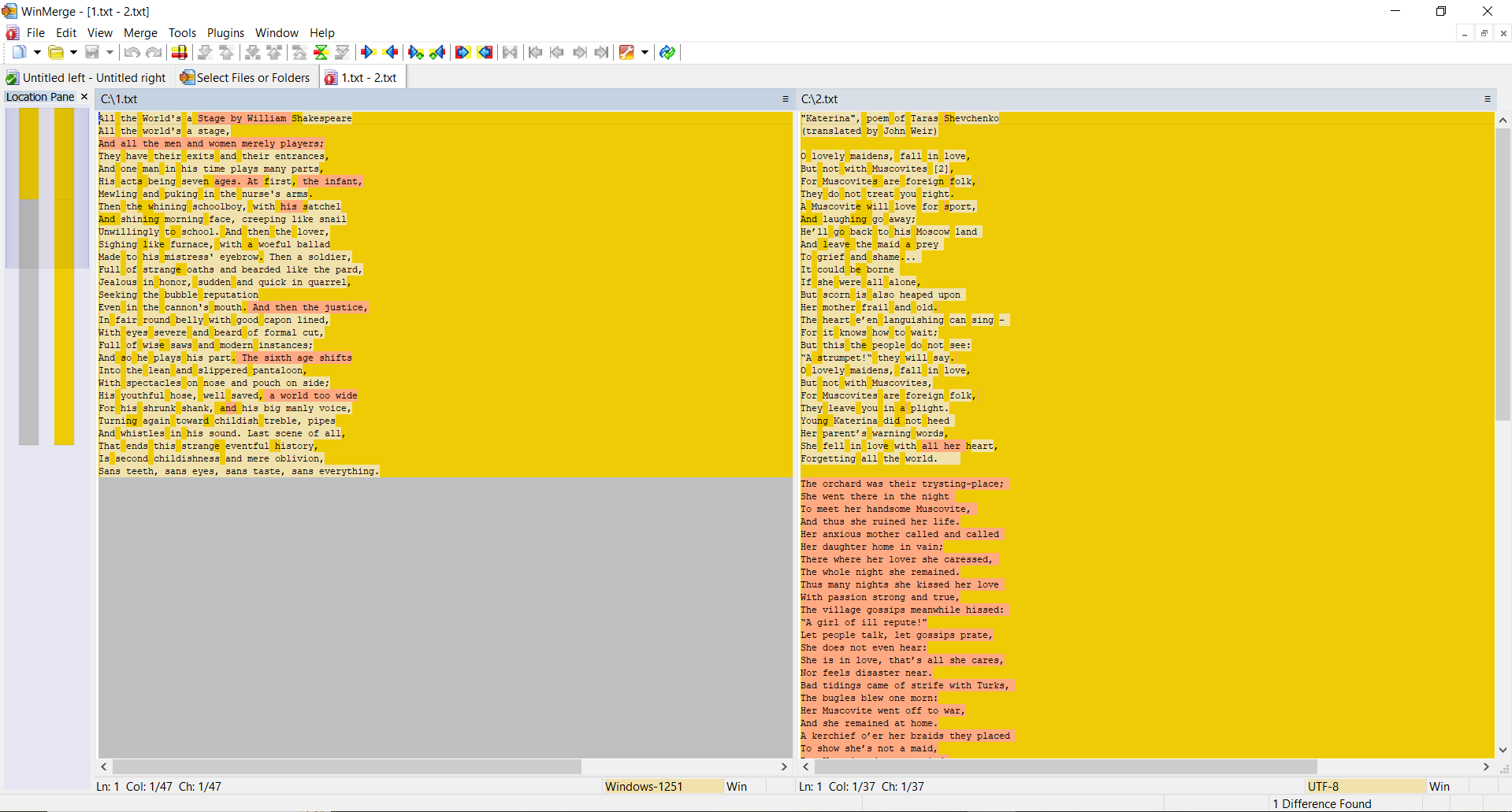
TEST 3: beregn hashes for to helt forskellige tekstfiler
Indhold af den anden fil:
"Katerina", poem of Taras Shevchenko
(translated by John Weir)
O lovely maidens, fall in love,
But not with Muscovites [2],
For Muscovites are foreign folk,
They do not treat you right.
A Muscovite will love for sport,
And laughing go away;
He`ll go back to his Moscow land
And leave the maid a prey
To grief and shame...
It could be borne
If she were all alone,
But scorn is also heaped upon
Her mother frail and old.
The heart e`en languishing can sing –
For it knows how to wait;
But this the people do not see:
“A strumpet!“ they will say.
O lovely maidens, fall in love,
But not with Muscovites,
For Muscovites are foreign folk,
They leave you in a plight.
Young Katerina did not heed
Her parent`s warning words,
She fell in love with all her heart,
Forgetting all the world.
The orchard was their trysting-place;
She went there in the night
To meet her handsome Muscovite,
And thus she ruined her life.
Her anxious mother called and called
Her daughter home in vain;
There where her lover she caressed,
The whole night she remained.
Thus many nights she kissed her love
With passion strong and true,
The village gossips meanwhile hissed:
“A girl of ill repute!”
Let people talk, let gossips prate,
She does not even hear:
She is in love, that`s all she cares,
Nor feels disaster near.
Bad tidings came of strife with Turks,
The bugles blew one morn:
Her Muscovite went off to war,
And she remained at home.
A kerchief o`er her braids they placed
To show she`s not a maid,
But Katerina does not mind,
Her lover she awaits.
He promised her that he’d return
If he was left alive,
That he`d come back after the war –
And then she`d be his wife,
An army bride, a Muscovite
Herself, her ills forgot,
And if in meantime people prate,
Well, let the people talk!
She does not worry, not a bit –
The reason that she weeps
Is that the girls at sundown sing
Without her on the streets.
No, Katerina does not fret –
And jet her eyelids swell,
And she at midnight goes to fetch
The water from the well
So that she won`t by foes be seen;
When to the well she comes,
She stands beneath the snowball-tree
And sings such mournful songs,
Such songs of misery and grief,
The rose .itself must weep.
Then she comes home - content that she
By neighbours was not seen.
No, Katerina does not fret.
She`s carefree as can be -
With her new kerchief on her head
She looks out on the street.
So at the window day by day
Six months she sat in vain....
With sickness then was overcome,
Her body racked with pain.
Her illness very grievous proved.
She barely breathed for days ...
When it was over - by the stove
She rocked her tiny babe.
The gossips` tongues now got free rein.
The other mothers jibed
That soldiers marching home again
At her house spent the night.
“Oh, you have reared a daughter fair.
And not alone beside
The stove she sits - she`s drilling there
A little Muscovite.
She found herself a brown-eyed son...
You must have taught her how!...
Oh fie on ye, ye prattle tongues,
I hope yourselves you`ll feel
Someday such pains as she who bore
A son that you should jeer!
Oh, Katerina, my poor dear!
How cruel a fate is thine!
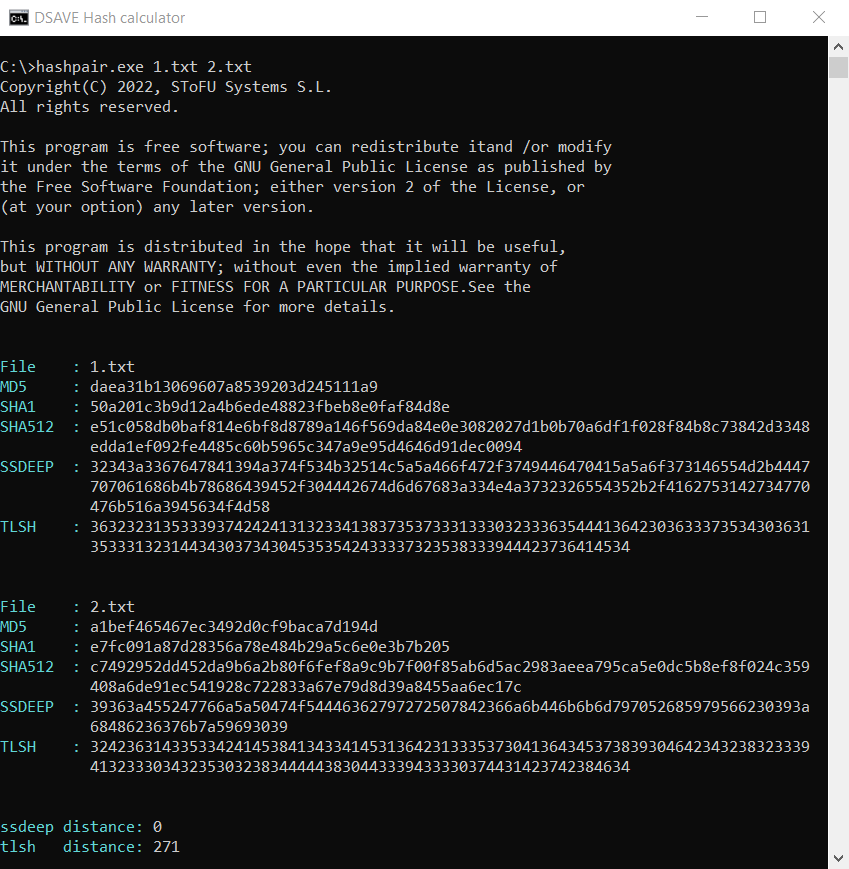
SSDEEP siger, at filerne er helt forskellige, med 0% match. TLSH siger dog, at filerne kun er 27,1% forskellige.
Hvorfor er det sådan? Vi overvejer jo afstanden mellem to helt forskellige tekstfiler, ikke?
Sagen er, at som vi nævnte ovenfor, tager TLSH-algoritmen højde for frekvenser.
På trods af, at tekstene er forskellige, er de alligevel skrevet på samme sprog, bruger det samme alfabet og har et antal af de samme ord. Denne egenskab ved denne hash-algoritme hjælper med at detektere ændringer af ondsindede filer.
TEST 4: sammenlign 2 Windows systemfiler
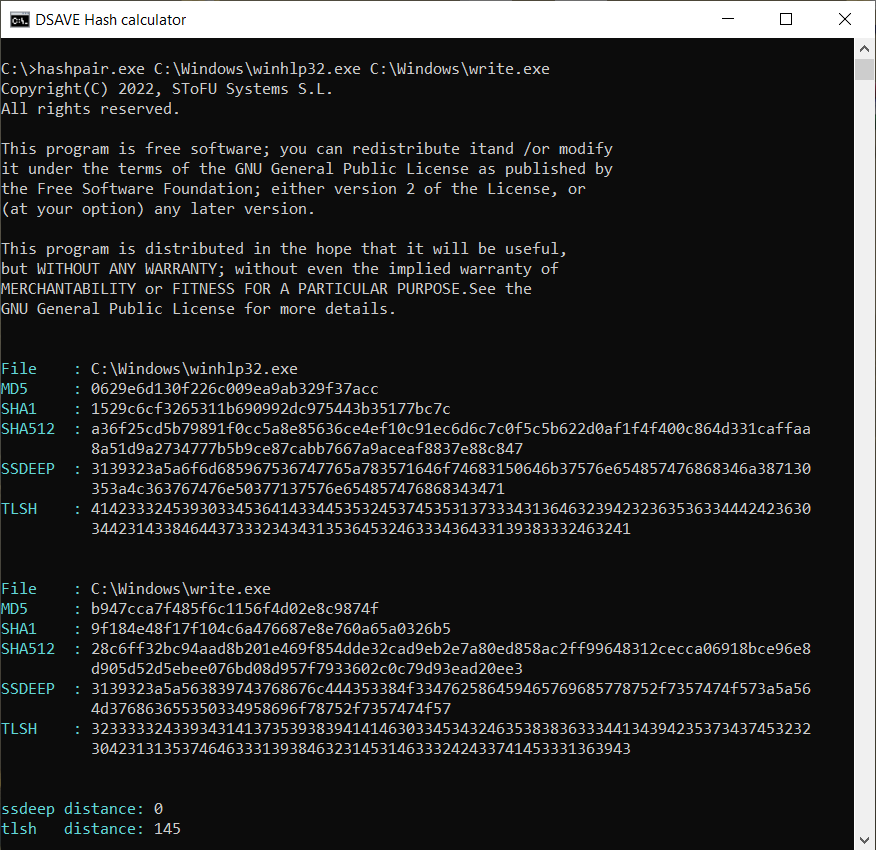
SSDEEP siger, at filerne er helt forskellige, med 0% matches.
TLSH-algoritmen siger dog, at filerne kun afviger med 14,5%. Dette skyldes delvist, at filerne sandsynligvis er bygget af den samme compiler, af det samme firma, muligvis ved brug af de samme kode mønstre. Filerne har lignende VERSION_INFO og MZ headers.
TEST 5: Sammenlign 2 systemfiler og vores hashpair.exe-fil
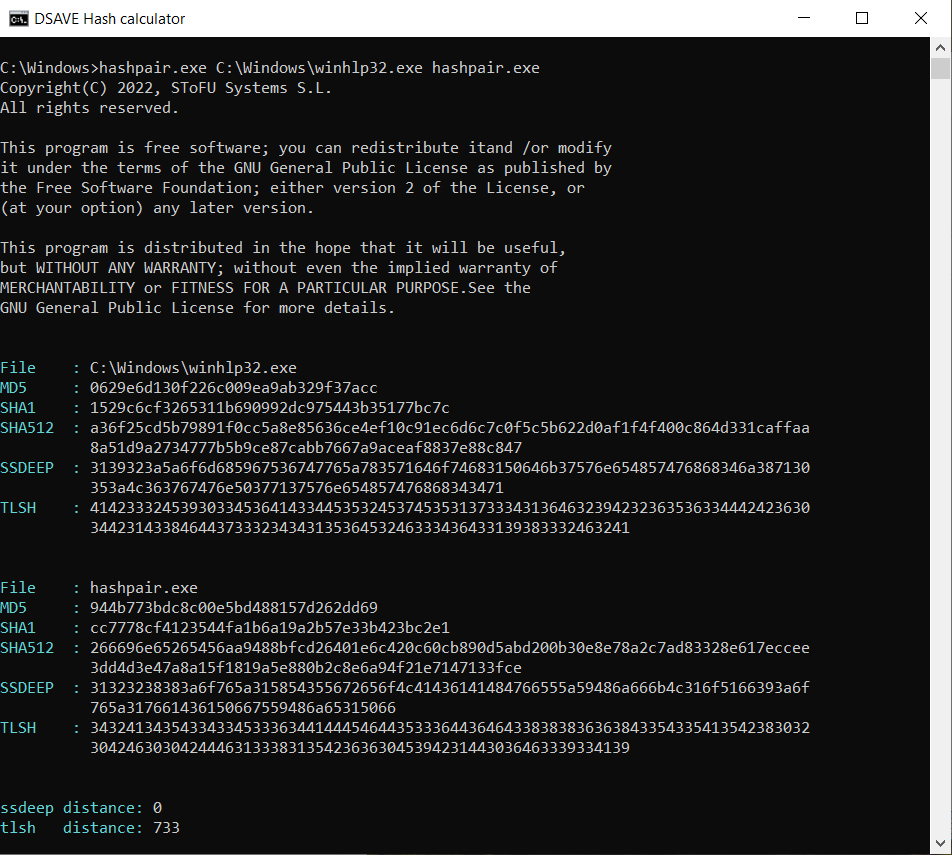
SSDEEP siger, at filerne er helt forskellige, med 0% matches.
TLSH-algoritmen siger, at filerne afviger betydeligt, med 73,3%. Disse filer er blevet kompileret af forskellige firmaer, ved brug af forskellige biblioteker og forskellige compilere. Disse filer har forskellige VERSION_INFO og forskellige MZ headers. Dermed tillader TLSH-algoritmen dig at kategorisere eksekverbare filer, hvilket hjælper med at identificere lignende ondsindede filer eller ondsindede filer fra samme familie.
Liste over anvendte værktøjer
1. WinMerge: https://winmerge.org
WinMerge er et Open Source differencerings- og fletningsværktøj til Windows. WinMerge kan sammenligne både mapper og filer og præsenterer forskelle i et visuelt tekstformat, der er let at forstå og håndtere.
2. Notepad++: https://notepad-plus-plus.org/downloads
Notepad++ er en gratis (både som i "fri tale" og også som i "gratis øl") kildekode-editor og erstatning for Notesblok, der understøtter flere sprog. Kørende i MS Windows-miljøet styres dets brug af GNU General Public License.
GITHUB
Du kan finde koden til hele projektet på vores github:
https://github.com/SToFU-Systems/DSAVE
HVAD ER NÆSTE?
Vi sætter pris på din støtte og ser frem til din fortsatte engagement i vores fællesskab.
I den næste artikel vil vi sammen med dig skrive den simpleste PE ressource parser.
Eventuelle spørgsmål fra artiklens forfattere kan sendes til e-mail: articles@stofu.io
Tak for din opmærksomhed og hav en god dag!




