Almohadilla
En primer lugar, repasemos los conceptos básicos y familiaricémonos con un concepto como el de hash.
Algoritmo de hash - es una función matemática que recibe datos de cualquier tamaño y produce una salida llamada hash o resumen del mensaje. La salida es una representación única de los datos de entrada, que se puede utilizar para verificar que los datos no han sido alterados. Los algoritmos de hash se utilizan para garantizar la integridad y autenticidad de los datos. En términos simples, un hash es una huella digital única de un conjunto de datos. Es como un código que representa los datos. Este código es generado por una función matemática llamada función de hash. Si los datos cambian aunque sea un poco, el hash será diferente.
Existen características clave primarias para el hash:
-
Determinista: Una función hash debe siempre producir la misma salida para una entrada dada. Esto significa que si codificas los mismos datos dos veces, deberías obtener el mismo valor de hash ambas veces.
-
Irreversibilidad: Debe ser computacionalmente inviable reconstruir los datos de entrada originales a partir de su valor de hash. Esta propiedad es importante para la seguridad, ya que protege los datos originales de ser descubiertos por atacantes que solo tienen acceso al valor del hash.
-
Uniformidad: Una función hash debe producir una distribución uniforme de valores de hash en todas las entradas posibles. Esto significa que cada valor de hash debe ser igualmente probable de ocurrir, y no debe haber patrones o sesgos en la distribución de los valores de hash.
-
Imprevisibilidad: Debe ser computacionalmente inviable predecir el valor de hash de una entrada basándose en los valores de hash de otras entradas o en las propiedades de la función hash en sí misma. Esta propiedad es importante para la seguridad, ya que dificulta a los atacantes crear una colisión (dos entradas diferentes que producen el mismo valor de hash).
-
Irreversibilidad: Debe ser computacionalmente inviable reconstruir los datos de entrada originales a partir de su valor de hash. Esta propiedad es importante para la seguridad, ya que protege los datos originales de ser descubiertos por atacantes que solo tienen acceso al valor del hash.
-
Resistencia a ataques de colisión: Una función hash debe ser resistente a ataques de colisión, que involucran encontrar dos entradas diferentes que producen el mismo valor de hash. Los ataques de colisión se pueden utilizar para crear firmas digitales fraudulentas o para eludir controles de acceso, por lo tanto, es importante que una función hash esté diseñada para resistirlos.
Otras características de los hashes que puedes encontrar en la página de Wikipedia:
https://es.wikipedia.org/wiki/Función_hash
Verificación de datos. Lista negra y lista blanca.
En el contexto del software antivirus, los algoritmos hash se utilizan para detectar malware o excluir alertas de falsos positivos. El software antivirus mantiene una base de datos de hashes de malware conocidos (blacklist) y hashes de software confiable (whitelis). Cuando se escanea un archivo, su hash se compara con los hashes en la base de datos. Los algoritmos hash más comúnmente utilizados para la verificación de datos son MD5, SHA-1, SHA-256 y SHA-512.
El uso de hashes en listas negras y blancas de antivirus ayuda a acelerar el proceso de escaneo, ya que el programa antivirus no necesita realizar un análisis detallado de cada archivo para determinar si es malicioso o no. En su lugar, puede comparar los valores hash de los archivos contra los de la blacklist/whitelist para identificar rápidamente amenazas conocidas o aplicaciones confiables.
Blacklist. En el contexto de la ciberseguridad y el software antivirus, una lista negra es una lista de archivos maliciosos conocidos o partes de estos archivos. Cuando un programa antivirus escanea un computador o red, compara los archivos y entidades que encuentra contra la lista negra para identificar cualquier amenaza. Si un archivo o entidad coincide con una entrada en la lista negra, el programa antivirus tomará medidas para eliminarlo o ponerlo en cuarentena para prevenir que cause daño.
Mientras que las listas negras pueden ser útiles para detectar y prevenir amenazas conocidas, no siempre son efectivas para proteger contra amenazas nuevas y desconocidas. Los atacantes pueden utilizar diversas técnicas, como la ofuscación o el polimorfismo, para modificar el código o comportamiento de un archivo o entidad y evadir la detección por programas antivirus.
Por lo tanto, los programas antivirus a menudo utilizan una combinación de técnicas, como whitelisting y detección basada en comportamiento, para complementar el uso de listas negras y proporcionar una protección más completa contra una mayor gama de amenazas.
Whitelist. En el contexto de la ciberseguridad y el software antivirus, una lista blanca es una lista de archivos confiables que se sabe que son seguros. Si un archivo o entidad coincide con una entrada en la lista blanca, el programa antivirus permitirá que se abra/ejecute sin tomar ninguna medida, ya que se considera seguro.
Las listas blancas son útiles para prevenir falsos positivos en programas antivirus y de seguridad. Los falsos positivos ocurren cuando un programa o archivo es marcado como malicioso o dañino cuando en realidad es seguro. Al usar una lista blanca, los programas de seguridad pueden evitar estos falsos positivos, lo que puede ahorrar tiempo y prevenir alertas innecesarias.
Usar hashes y blacklists/whitelists puede ser una manera efectiva de protegerse contra amenazas conocidas y prevenir falsos positivos en programas antivirus y de seguridad.
¿Por qué los antivirus utilizan varios algoritmos de hash?
Los programas antivirus utilizan múltiples algoritmos de hash por varias razones:
-
Aunque las listas negras pueden ser efectivas para detectar y prevenir amenazas conocidas, no son infalibles. Los atacantes pueden utilizar diversas técnicas para evadir la detección, como modificar los datos para evitar coincidir con las firmas en la lista negra. Estas técnicas se denominan "ataques de colisión". Un ataque de colisión es un tipo de ataque criptográfico en el que un atacante intenta encontrar dos entradas diferentes, como archivos o mensajes, que produzcan el mismo valor hash cuando se procesan a través de una función hash (colisión). El objetivo de un ataque de colisión es crear un par de entradas que se puedan usar para subvertir un sistema que dependa de la integridad de los valores hash, como las firmas digitales, la autenticación de contraseñas o las verificaciones de integridad de datos. Si un atacante encuentra una colisión, puede usarla para eludir las medidas de seguridad que dependen de la función hash. Para mitigar el riesgo de ataques de colisión, los antivirus utilizan funciones hash fuertes que son resistentes a ataques, y usan varias funciones hash simultáneamente. Por ejemplo, si un programa antivirus solo usara el algoritmo hash MD5, un atacante podría crear potencialmente un archivo malicioso que tenga el mismo hash MD5 que un archivo legítimo, y engañar al programa antivirus para tratar el archivo malicioso como seguro. Sin embargo, el uso de múltiples algoritmos de hash, como MD5, SHA-1 y SHA-256, hace que sea más difícil para un atacante crear un ataque de colisión que funcione contra todos los algoritmos simultáneamente.
-
Eficiencia: Los diferentes algoritmos de hash tienen diferentes requisitos computacionales, y algunos pueden ser más eficientes que otros dependiendo del tamaño del archivo, tipo u otros factores. El uso de múltiples algoritmos de hash permite a los programas antivirus seleccionar el algoritmo más apropiado para una situación dada, lo que puede ahorrar tiempo y potencia de procesamiento. Por ejemplo, SHA-256 puede ser más intensivo computacionalmente que MD5, por lo que un programa antivirus puede optar por usar MD5 para archivos más pequeños y SHA-256 para archivos más grandes.
-
Flexibilidad: Los diferentes algoritmos de hash están diseñados para diferentes casos de uso y aplicaciones. Al usar múltiples algoritmos de hash, los programas antivirus pueden adaptarse a diferentes necesidades y escenarios, como la detección de malware, la verificación de la integridad de los archivos o la detección de manipulaciones o modificaciones. Por ejemplo, un investigador forense puede usar un algoritmo de hash diferente al de un programa antivirus para asegurar que los datos no hayan sido modificados durante una investigación.
Utilizar múltiples algoritmos de hash es una mejor práctica en el desarrollo de software de ciberseguridad y antivirus, ya que proporciona robustez, compatibilidad, eficiencia y flexibilidad en la detección y prevención de amenazas cibernéticas.
¿Cómo reconocen los antivirus datos y archivos similares pero no idénticos?
Archivos similares pero no idénticos pueden ser un problema en la ciberseguridad porque pueden ser utilizados por los atacantes para evadir la detección por parte del software antivirus.
Por ejemplo, un atacante puede tomar un archivo de malware conocido y hacer pequeñas modificaciones a su código o estructura, como cambiar los nombres de las variables o reordenar las instrucciones. Estas modificaciones pueden ser suficientes para crear un nuevo archivo que es similar pero no idéntico al archivo de malware original, y que puede no ser detectado por software antivirus que depende de métodos de detección basados en hashes tradicionales.
Además, los atacantes pueden usar archivos similares pero no idénticos para crear malware polimórfico, el cual puede cambiar su código o estructura con cada infección para evitar ser detectado. El malware polimórfico puede ser muy difícil de detectar mediante técnicas antivirus tradicionales, que dependen de reconocer patrones o firmas específicas en el código del malware.
Para resolver este problema, los antivirus utilizan hashes difusos.
El hashing difuso es una técnica utilizada por algunos programas antivirus para detectar archivos similares pero no idénticos, incluyendo malware polimórfico. Al dividir un archivo en piezas más pequeñas y comparar los hashes de esas piezas con los de otros archivos, el hashing difuso puede identificar archivos que tienen un código o estructura similar, incluso si no son idénticos.
El hashing difuso funciona identificando secuencias de bytes que aparecen frecuentemente en todo el archivo. Estas secuencias, también conocidas como "fragmentos", se cifran utilizando una función de hash criptográfico para generar un valor de hash. Los valores de hash de los fragmentos se comparan entonces con los de otros archivos para identificar fragmentos que son similares.
La ventaja del hashing difuso es que puede detectar similitudes incluso cuando los archivos han sido modificados u ofuscados, lo que lo convierte en una herramienta poderosa para identificar variantes de malware conocido. Por ejemplo, si un atacante modifica un archivo de malware conocido cambiando los nombres de las variables o funciones, los métodos de detección basados en hash tradicionales podrían no detectar el archivo modificado. Sin embargo, el hashing difuso aún puede detectar el archivo modificado identificando bloques que son similares a los del archivo de malware original. A diferencia de los algoritmos de hashing criptográfico como MD5, SHA-1 o SHA-512, los algoritmos de hashing difuso producen valores de hash de longitud variable que se basan en la similitud de los datos de entrada.
Ventajas de los hashes difusos:
-
Detección de archivos similares: Los hashes difusos pueden detectar archivos similares incluso si han sido modificados ligeramente, lo cual es útil para identificar variantes de malware conocido.
-
Reducción de falsos positivos: Los hashes difusos pueden reducir el número de falsos positivos generados por los métodos de detección basados en hashes tradicionales. Esto se debe a que los hashes difusos pueden detectar archivos que son similares pero no idénticos al malware conocido.
-
Resiliencia a la ofuscación: Los hashes difusos son más resilientes a las técnicas de ofuscación utilizadas por los atacantes para evadir la detección. Esto se debe a que el algoritmo de hash difuso descompone el archivo en piezas más pequeñas y genera hashes para cada pieza, lo que hace más difícil que un atacante modifique el archivo de manera que evite la detección.
Fuzzy hashing presenta algunas limitaciones que pueden afectar su eficacia en la detección de archivos similares pero no idénticos:
-
Falsos positivos: El hash difuso puede producir falsos positivos, donde archivos legítimos son marcados como maliciosos porque tienen un código o estructura similar al de malware conocido. Esto puede ocurrir si los archivos comparten librerías o frameworks comunes.
-
Rendimiento: El hash difuso puede ser intensivo en términos de computación, especialmente para archivos grandes. Esto puede ralentizar el proceso de escaneo e impactar el rendimiento del sistema.
-
Limitaciones de tamaño: El hash difuso puede no funcionar bien en archivos muy pequeños o archivos con baja entropía, ya que puede que no haya suficientes bloques únicos para generar hashes significativos.
-
Manipulación: El hash difuso puede no ser efectivo si un atacante lo tiene específicamente en la mira y modifica un archivo para evitar su detección. Por ejemplo, un atacante podría cambiar deliberadamente la estructura de un archivo para impedir que sea identificado mediante el hash difuso.
¿Cuál es la diferencia entre los algoritmos de hash criptográficos y los algoritmos de hash difusos?
Los algoritmos de hash criptográficos y los algoritmos de hash difusos se utilizan ambos en ciberseguridad, pero tienen propósitos y características diferentes.
Los algoritmos de hash criptográficos, como SHA-256 y MD5, están diseñados para proporcionar integridad y autenticidad de datos mediante la generación de valores de hash únicos de longitud fija que son casi imposibles de revertir. Los algoritmos de hash criptográficos se utilizan para verificar la integridad de los datos.
Los algoritmos de hash difuso, como SSDEEP, están diseñados para identificar datos similares pero no idénticos, como archivos que han sido modificados o reempaquetados por autores de malware. El hashing difuso utiliza una técnica de ventana deslizante para dividir los datos en pequeños fragmentos y generar hashes probabilísticos de longitud variable, que se comparan contra una base de datos de hashes de malware conocidos para identificar archivos potencialmente maliciosos.
Los algoritmos de hash criptográficos están diseñados para ser resistentes a colisiones, lo que significa que es extremadamente difícil encontrar dos entradas que produzcan el mismo resultado de hash. Los algoritmos de hash difusos no necesitan ser resistentes a colisiones ya que están diseñados para detectar similitudes entre archivos en lugar de producir resultados de hash únicos
La principal diferencia entre los algoritmos de hash criptográficos y los algoritmos de hash difusos es su nivel de determinismo. Los algoritmos de hash criptográficos producen hashes deterministas de longitud fija que son únicos para cada entrada, mientras que los algoritmos de hash difusos producen hashes probabilísticos de longitud variable que son similares para entradas similares.
¿Qué algoritmos de hashing difuso utilizaremos en nuestra solución?
En nuestra solución vamos a utilizar SSDEEP y TLSH.
ssdeep es un algoritmo de hash difuso que se utiliza para identificar datos similares pero no idénticos, como variantes de malware. Funciona generando un valor de hash que representa la similitud de los datos de entrada, en lugar de un identificador único como las funciones de hash criptográfico. La salida de ssdeep es de longitud variable y probabilística, lo que le permite detectar incluso diferencias menores entre dos archivos. ssdeep se utiliza comúnmente en análisis y detección de malware, y también está integrado en diversas herramientas de seguridad y software antivirus.
TLSH (Hash Sensible a la Localidad de Trend Micro) es un algoritmo de hash difuso que se utiliza para identificar datos similares pero no idénticos, como variantes de malware. Funciona creando un valor de hash que captura las características únicas de los datos de entrada, como la frecuencia y el orden de los bytes. La salida de TLSH es de longitud variable y probabilística, lo que le permite detectar similitudes incluso si los datos de entrada han sido modificados u ofuscados. TLSH se usa comúnmente en el análisis y detección de malware, y también está integrado en diversas herramientas de seguridad y software antivirus.
ssdeep y TLSH utilizan métricas de distancia para determinar la similitud entre dos valores de hash. Sin embargo, las métricas de distancia que utilizan ssdeep y TLSH son diferentes.
ssdeep utiliza la métrica de "distancia de hash difusa" para calcular la distancia entre dos valores de hash. Esta métrica de distancia se basa en el número de bloques coincidentes y no coincidentes entre los dos hashes, así como en el tamaño de los hashes. La métrica de distancia es un valor porcentual que varía de 0 a 100, donde 0 significa que los dos hashes son idénticos, y 100 significa que los dos hashes son completamente disímiles.
TLSH, por otro lado, utiliza la métrica de "diferencia total" para calcular la distancia entre dos valores de hash. Esta métrica de distancia se basa en la diferencia entre las características sensibles a la localidad de los dos conjuntos de datos de entrada. El resultado de la métrica de "diferencia total" es un valor entre 0 y 1000, donde 0 significa que los dos valores de hash son idénticos, y 1000 significa que los dos valores de hash son completamente diferentes.
Construyendo el módulo de hash
Para nuestra solución, utilizaremos bibliotecas de código abierto:
1. PolarSSL: https://polarssl.org/
PolarSSL es una biblioteca de software libre y de código abierto para implementar protocolos criptográficos como Transport Layer Security (TLS), Secure Sockets Layer (SSL), Datagram Transport Layer Security (DTLS). Proporciona varios algoritmos y protocolos criptográficos, incluyendo funciones de hash, cifrado simétrico y asimétrico, firmas digitales y algoritmos de intercambio de claves. PolarSSL está diseñado para ser ligero y eficiente, lo que lo hace adecuado para su uso en entornos con recursos limitados.
2. ssdeep: http://ssdeep.sf.net/
3. TLSH: https://github.com/trendmicro/tlsh/
Después de implementar las bibliotecas en el proyecto, agregamos un código simple:
struct HashData
{
BYTE md5[16];
BYTE sha1[20];
BYTE sha512[64];
std::string ssdeep;
std::string tlsh;
};
HashData hash(const void* buff, uint64_t size)
{
HashData snap = {};
hashes::md5(buff, size, snap.md5);
hashes::sha1(buff, size, snap.sha1);
hashes::sha4(buff, size, snap.sha512);
snap.ssdeep = hashes::ssdeepHash(buff, size);
snap.tlsh = hashes::tlshHash(buff, size);
return snap;
}

Verificando el módulo de hash
¡Es hora de probar el módulo de hashing! Para hacer esto, crearemos un archivo de texto con el siguiente contenido:
All the World`s a Stage by William Shakespeare
All the world`s a stage,
And all the men and women merely players;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first, the infant,
Mewling and puking in the nurse`s arms.
Then the whining schoolboy, with his satchel
And shining morning face, creeping like snail
Unwillingly to school. And then the lover,
Sighing like furnace, with a woeful ballad
Made to his mistress` eyebrow. Then a soldier,
Full of strange oaths and bearded like the pard,
Jealous in honor, sudden and quick in quarrel,
Seeking the bubble reputation
Even in the cannon`s mouth. And then the justice,
In fair round belly with good capon lined,
With eyes severe and beard of formal cut,
Full of wise saws and modern instances;
And so he plays his part. The sixth age shifts
Into the lean and slippered pantaloon,
With spectacles on nose and pouch on side;
His youthful hose, well saved, a world too wide
For his shrunk shank, and his big manly voice,
Turning again toward childish treble, pipes
And whistles in his sound. Last scene of all,
That ends this strange eventful history,
Is second childishness and mere oblivion,
Sans teeth, sans eyes, sans taste, sans everything.
PRUEBA 1: crea dos archivos idénticos con el mismo contenido (texto arriba) y calcula los hashes.
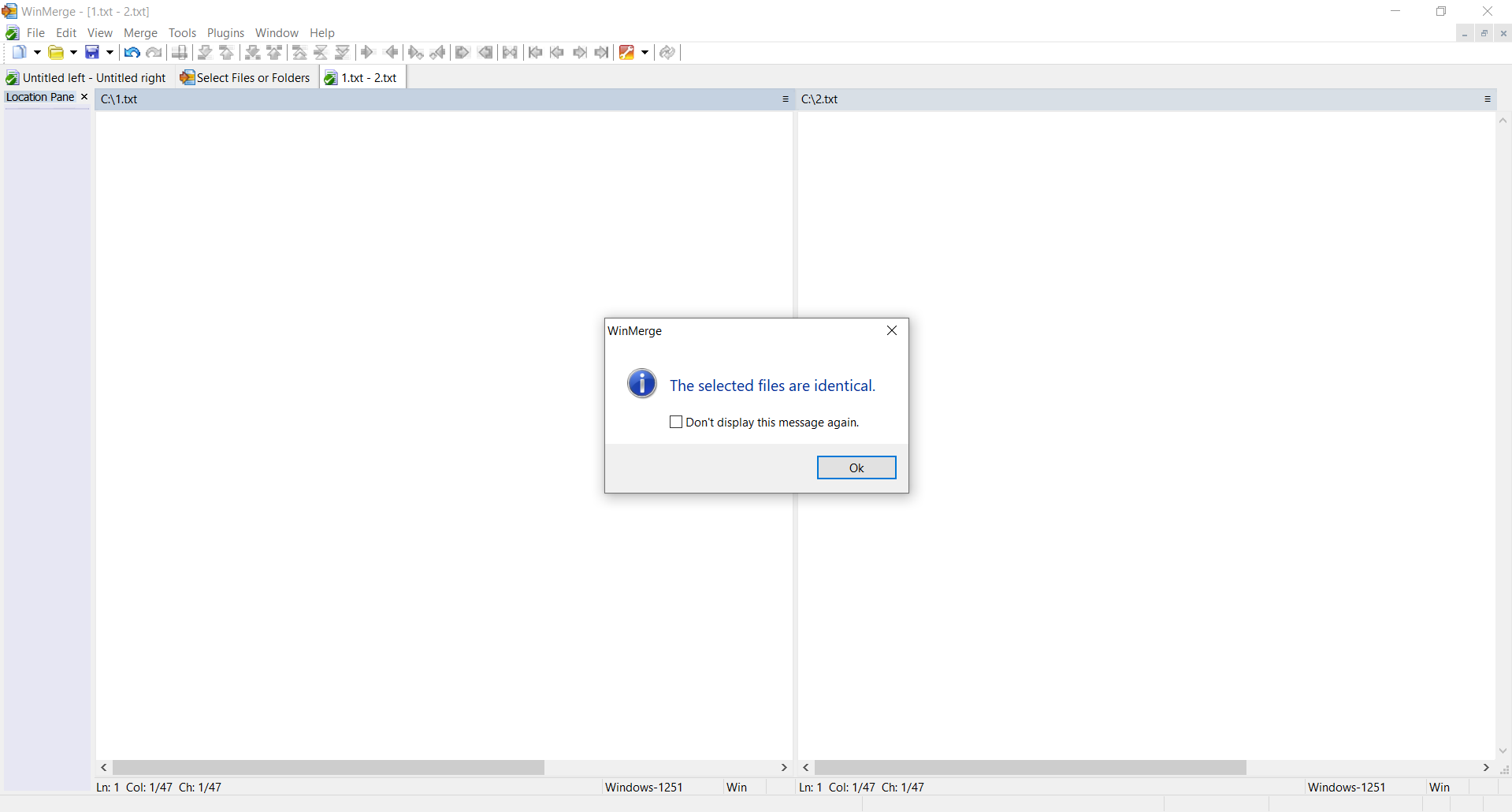
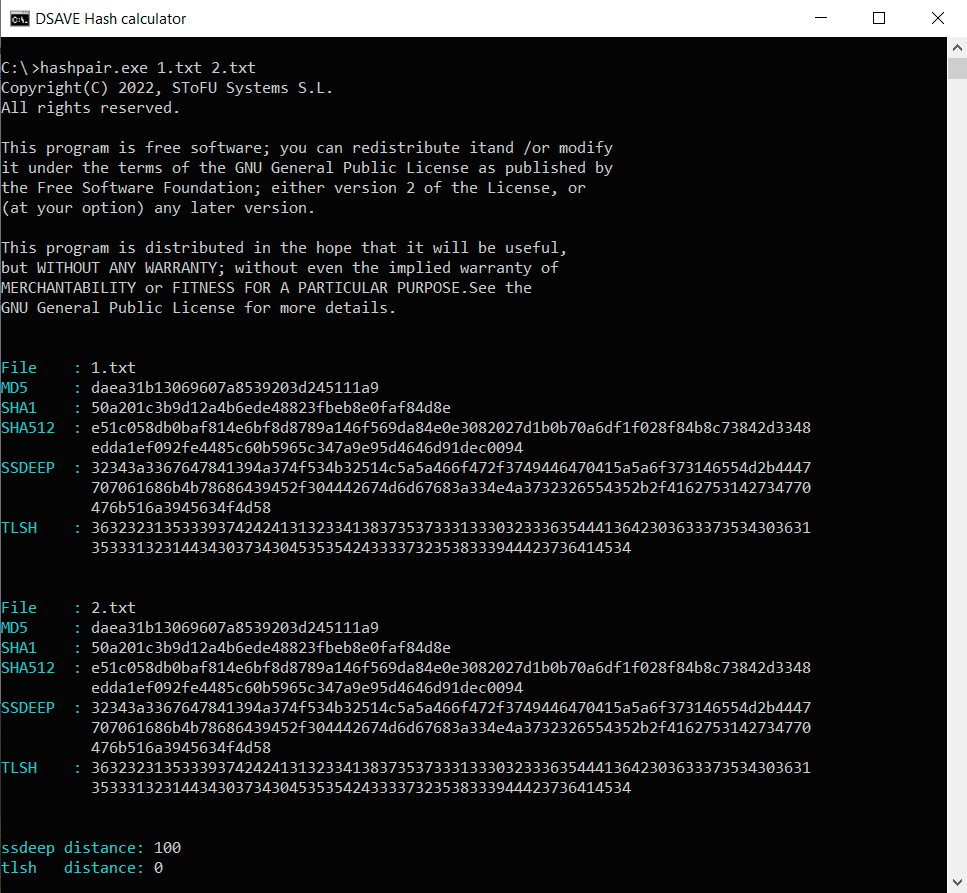
SSDEEP indica que los archivos son 100% idénticos. TLSH indica que hay un 0% de diferencias entre los archivos.
PRUEBA 2: Crea dos archivos idénticos con el mismo contenido, realiza cambios en el segundo archivo y calcula los hashes
Contenido del segundo archivo:
All the World`s a Stage by William Shakespeare
O lovely maidens, fall in love,
But not with Muscovites,
For Muscovites are foreign folk,
They do not treat you right.
A Muscovite will love for sport,
And laughing go away;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first, the infant,
Mewling and puking in the nurse`s arms.
Then the whining schoolboy, with his satchel
And shining morning face, creeping like snail
Unwillingly to school. And then the lover,
Sighing like furnace, with a woeful ballad
Made to his mistress` eyebrow. Then a soldier,
Full of strange oaths and bearded like the pard,
Jealous in honor, sudden and quick in quarrel,
Seeking the bubble reputation
Even in the cannon`s mouth. And then the justice,
In fair round belly with good capon lined,
With eyes severe and beard of formal cut,
Full of wise saws and modern instances;
And so he plays his part. The sixth age shifts
Into the lean and slippered pantaloon,
With spectacles on nose and pouch on side;
His youthful hose, well saved, a world too wide
For his shrunk shank, and his big manly voice,
Turning again toward childish treble, pipes
And whistles in his sound. Last scene of all,
That ends this strange eventful history,
Is second childishness and mere oblivion,
Sans teeth, sans eyes, sans taste, sans everything.
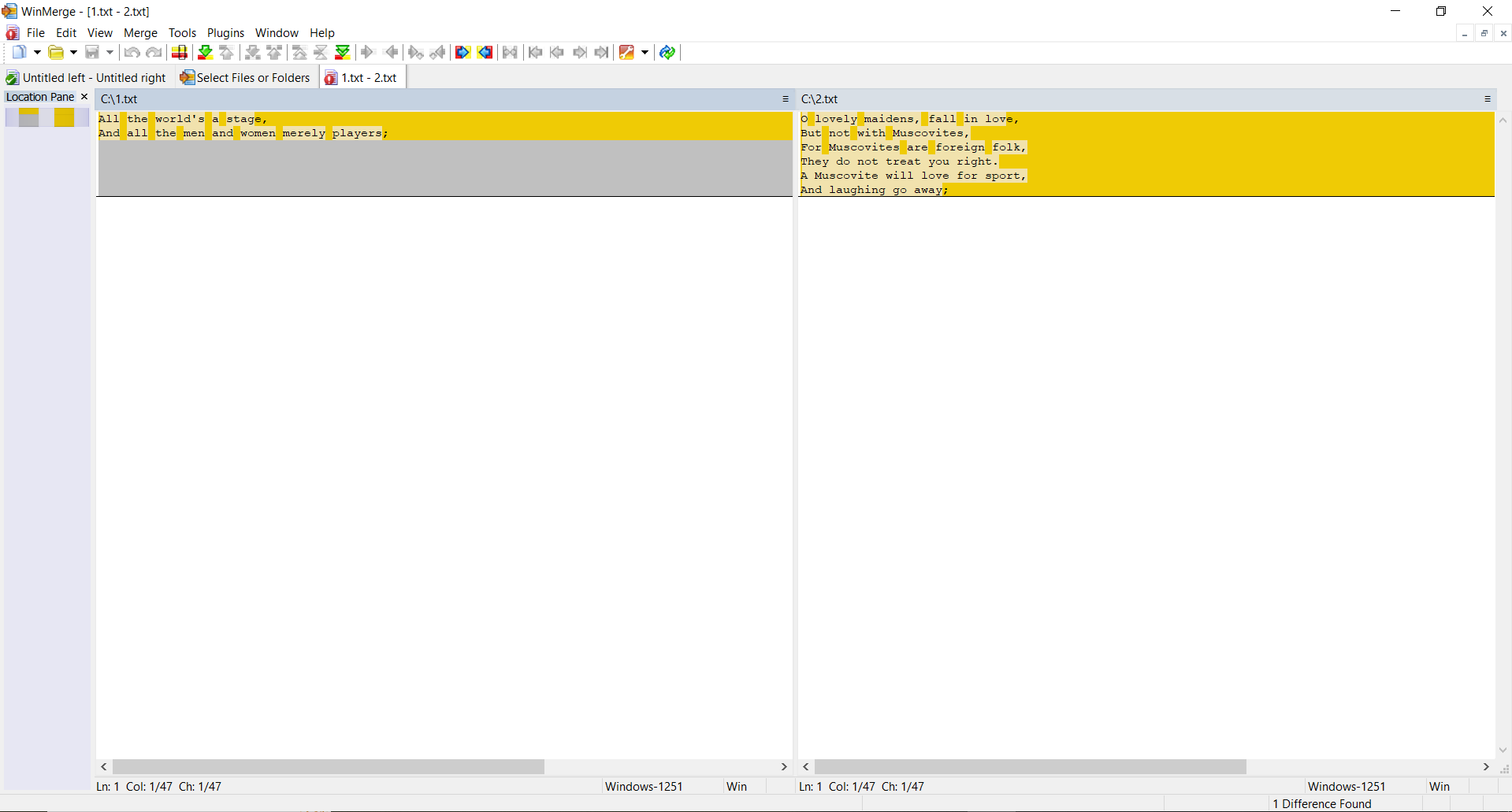
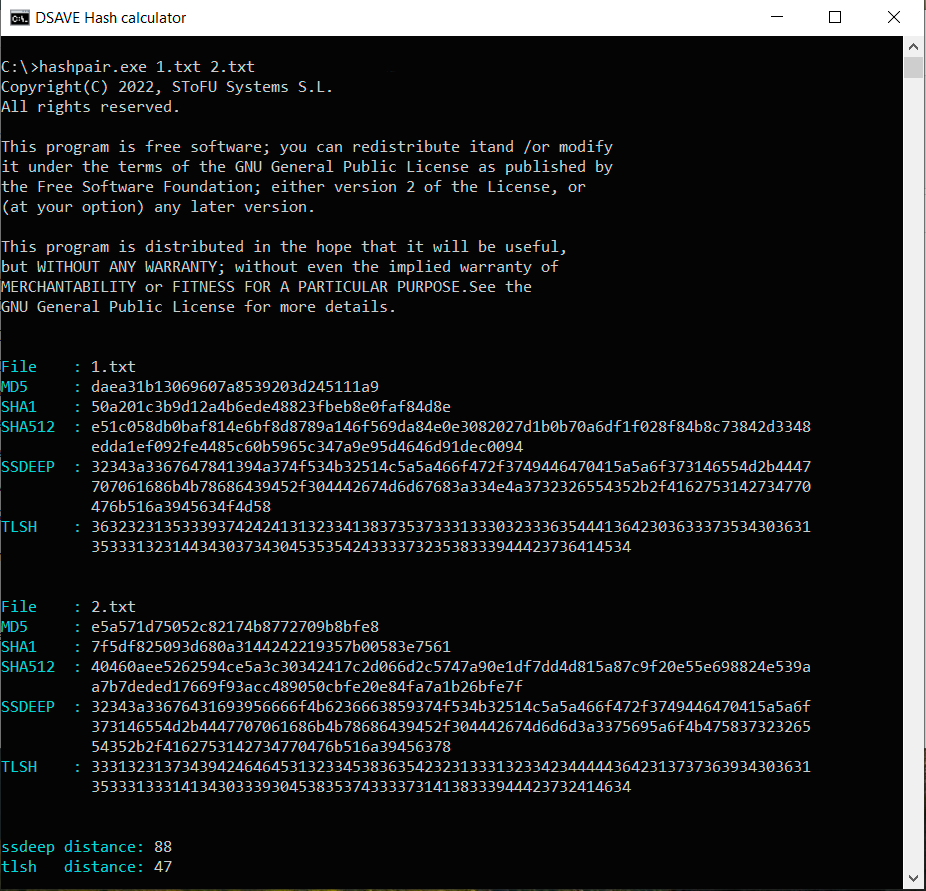
SSDEEP indica que los archivos son 88% idénticos. TLSH señala que hay un 4.7% de diferencias entre los archivos.
PRUEBA 3: calcular hashes para dos archivos de texto completamente diferentes
Contenido del segundo archivo:
"Katerina", poem of Taras Shevchenko
(translated by John Weir)
O lovely maidens, fall in love,
But not with Muscovites [2],
For Muscovites are foreign folk,
They do not treat you right.
A Muscovite will love for sport,
And laughing go away;
He`ll go back to his Moscow land
And leave the maid a prey
To grief and shame...
It could be borne
If she were all alone,
But scorn is also heaped upon
Her mother frail and old.
The heart e`en languishing can sing –
For it knows how to wait;
But this the people do not see:
“A strumpet!“ they will say.
O lovely maidens, fall in love,
But not with Muscovites,
For Muscovites are foreign folk,
They leave you in a plight.
Young Katerina did not heed
Her parent`s warning words,
She fell in love with all her heart,
Forgetting all the world.
The orchard was their trysting-place;
She went there in the night
To meet her handsome Muscovite,
And thus she ruined her life.
Her anxious mother called and called
Her daughter home in vain;
There where her lover she caressed,
The whole night she remained.
Thus many nights she kissed her love
With passion strong and true,
The village gossips meanwhile hissed:
“A girl of ill repute!”
Let people talk, let gossips prate,
She does not even hear:
She is in love, that`s all she cares,
Nor feels disaster near.
Bad tidings came of strife with Turks,
The bugles blew one morn:
Her Muscovite went off to war,
And she remained at home.
A kerchief o`er her braids they placed
To show she`s not a maid,
But Katerina does not mind,
Her lover she awaits.
He promised her that he’d return
If he was left alive,
That he`d come back after the war –
And then she`d be his wife,
An army bride, a Muscovite
Herself, her ills forgot,
And if in meantime people prate,
Well, let the people talk!
She does not worry, not a bit –
The reason that she weeps
Is that the girls at sundown sing
Without her on the streets.
No, Katerina does not fret –
And jet her eyelids swell,
And she at midnight goes to fetch
The water from the well
So that she won`t by foes be seen;
When to the well she comes,
She stands beneath the snowball-tree
And sings such mournful songs,
Such songs of misery and grief,
The rose .itself must weep.
Then she comes home - content that she
By neighbours was not seen.
No, Katerina does not fret.
She`s carefree as can be -
With her new kerchief on her head
She looks out on the street.
So at the window day by day
Six months she sat in vain....
With sickness then was overcome,
Her body racked with pain.
Her illness very grievous proved.
She barely breathed for days ...
When it was over - by the stove
She rocked her tiny babe.
The gossips` tongues now got free rein.
The other mothers jibed
That soldiers marching home again
At her house spent the night.
“Oh, you have reared a daughter fair.
And not alone beside
The stove she sits - she`s drilling there
A little Muscovite.
She found herself a brown-eyed son...
You must have taught her how!...
Oh fie on ye, ye prattle tongues,
I hope yourselves you`ll feel
Someday such pains as she who bore
A son that you should jeer!
Oh, Katerina, my poor dear!
How cruel a fate is thine!
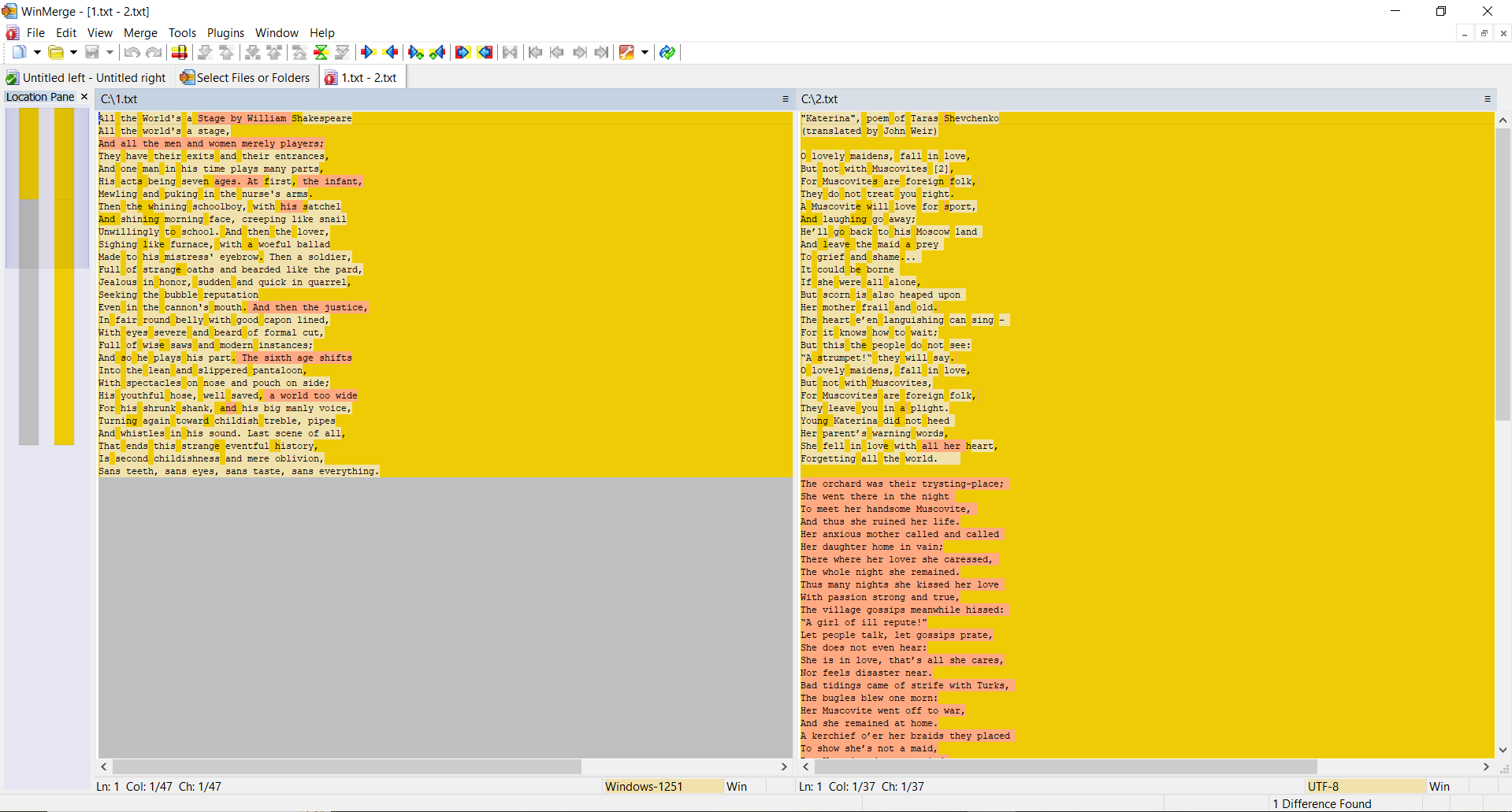
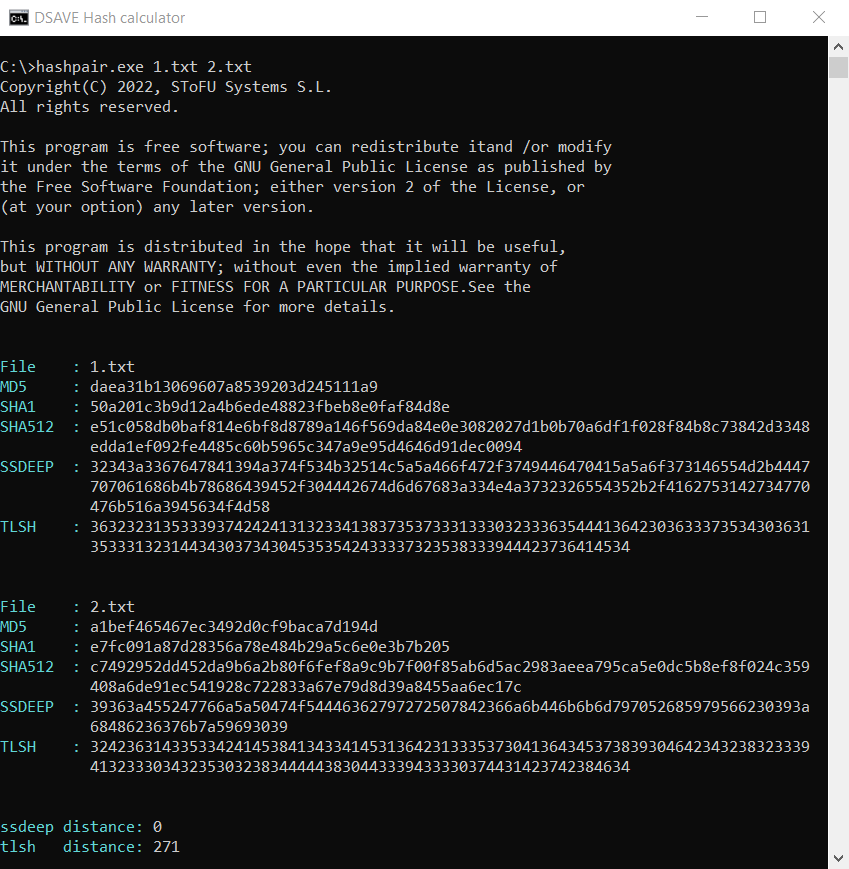
SSDEEP indica que los archivos son completamente diferentes, con un 0% de coincidencias. Sin embargo, TLSH dice que los archivos son solo un 27.1% diferentes.
¿Por qué es eso? Después de todo, consideramos la distancia entre dos archivos de texto completamente diferentes, ¿verdad?
La cuestión es que, como mencionamos anteriormente, el algoritmo TLSH toma en cuenta las frecuencias.
A pesar de que los textos son diferentes, no obstante están escritos en el mismo idioma, utilizan el mismo alfabeto y tienen una cantidad de palabras iguales. Esta característica de este algoritmo de hashing ayuda a detectar modificaciones en archivos maliciosos.
PRUEBA 4: comparar 2 archivos del sistema Windows
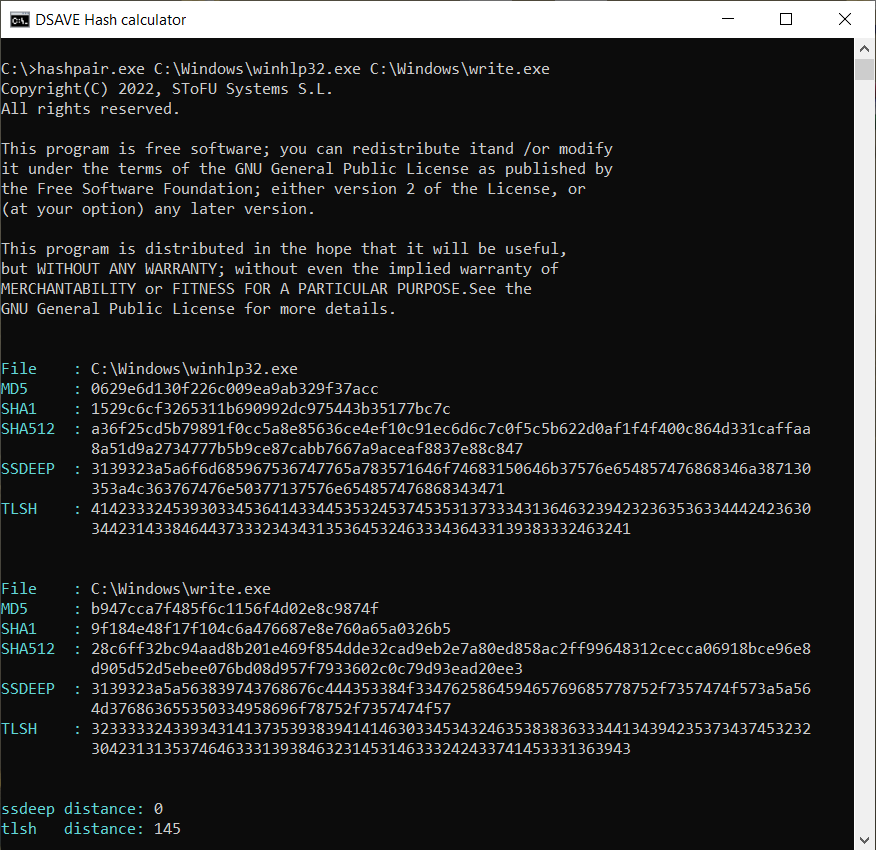
SSDEEP indica que los archivos son completamente diferentes, con un 0% de coincidencias.
Sin embargo, el algoritmo TLSH indica que los archivos difieren solo en un 14.5%. Esto se debe en parte a que lo más probable es que los archivos fueron compilados por el mismo compilador, de la misma empresa, posiblemente utilizando los mismos patrones de código. Los archivos tienen información de versión (VERSION_INFO) y encabezados MZ similares.
PRUEBA 5: comparar 2 archivos del sistema y nuestro archivo hashpair.exe
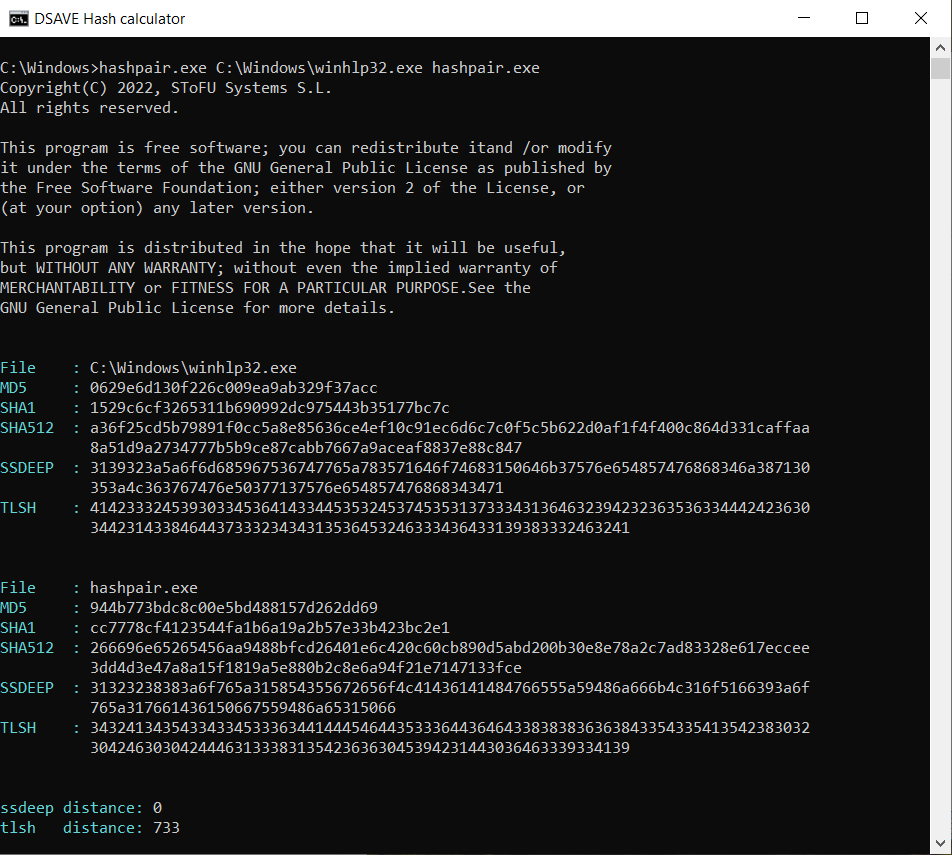
SSDEEP indica que los archivos son completamente diferentes, con un 0% de coincidencias.
El algoritmo TLSH indica que los archivos difieren significativamente, en un 73.3%. Estos archivos fueron compilados por diferentes compañías, utilizando diferentes bibliotecas y diferentes compiladores. Estos archivos tienen diferente VERSION_INFO y diferentes cabeceras MZ. Así, el algoritmo TLSH permite categorizar archivos ejecutables, ayudando a identificar archivos maliciosos similares o archivos maliciosos de la misma familia.
Lista de herramientas utilizadas
1. WinMerge: https://winmerge.org
WinMerge es una herramienta de diferenciación y fusión de código abierto para Windows. WinMerge puede comparar tanto carpetas como archivos, presentando las diferencias en un formato de texto visual que es fácil de entender y manejar.
2. Notepad++: https://notepad-plus-plus.org/downloads
Notepad++ es un editor de código fuente gratuito (en el sentido de "libertad de expresión" y también como "cerveza gratis") y reemplazo de Notepad que soporta varios idiomas. Funcionando en el entorno de Windows MS, su uso está regulado por la Licencia Pública General de GNU.
GITHUB
Puedes encontrar el código de todo el proyecto en nuestro github:
https://github.com/SToFU-Systems/DSAVE
¿QUÉ SIGUE?
Agradecemos su apoyo y esperamos su continua participación en nuestra comunidad
En el próximo artículo escribiremos juntos el analizador de recursos PE más simple.
Cualquier pregunta a los autores del artículo puede enviarse al correo electrónico: articles@stofu.io
¡Gracias por su atención y que tenga un buen día!




