El formato ejecutable portable (PE)
Lo primero con lo que se debe empezar es el formato PE. El conocimiento y comprensión de este formato es un requisito previo para desarrollar motores antivirus para la plataforma Windows (históricamente, la gran mayoría de los virus en el mundo están dirigidos a Windows).
El formato Portable Executable (PE) es un formato de archivo utilizado por el sistema operativo Windows para almacenar archivos ejecutables, como archivos .EXE y .DLL. Fue introducido con el lanzamiento de Windows NT en 1993, y desde entonces se ha convertido en el formato estándar para ejecutables en sistemas Windows.
Antes de la introducción del formato PE, Windows utilizaba una variedad de formatos diferentes para archivos ejecutables, incluyendo el formato New Executable (NE) para programas de 16 bits y el formato Compact Executable (CE) para programas de 32 bits. Estos formatos tenían su propio conjunto único de reglas y convenciones, lo que hacía difícil para el sistema operativo cargar y ejecutar programas de manera confiable.
Para estandarizar la disposición y estructura de los archivos ejecutables, Microsoft introdujo el formato PE con el lanzamiento de Windows NT. El formato PE fue diseñado para ser un formato común para programas de 32 bits y 64 bits.
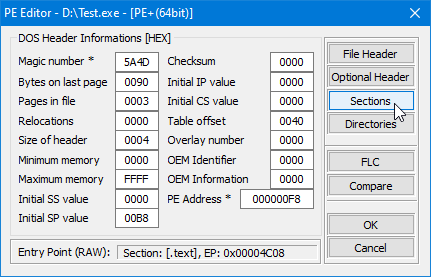
Una de las características clave del formato PE es su uso de un encabezado estandarizado, que se encuentra al inicio del archivo y contiene una serie de campos que proporcionan al sistema operativo información importante sobre el archivo ejecutable. Este encabezado incluye las estructuras IMAGE_DOS_HEADER y IMAGE_NT_HEADER , que se dividen en dos secciones principales: el IMAGE_FILE_HEADER y el IMAGE_OPTIONAL_HEADER.
La mayoría de los encabezados del formato PE están declarados en el archivo de cabecera WinNT.h
CABECERA_DOS_IMAGEN
La estructura IMAGE_DOS_HEADER es un encabezado heredado que se utiliza para soportar la compatibilidad hacia atrás con MS-DOS. Se utiliza para almacenar información sobre el archivo que es requerida por MS-DOS, como la ubicación del código y los datos del programa en el archivo, y el punto de entrada del programa. Esto permitió que los programas que fueron escritos para MS-DOS se ejecutaran en Windows NT, siempre y cuando fueran compilados como archivos PE.
typedef struct _IMAGE_DOS_HEADER
{
WORD e_magic;
WORD e_cblp;
WORD e_cp;
WORD e_crlc;
WORD e_cparhdr;
WORD e_minalloc;
WORD e_maxalloc;
WORD e_ss;
WORD e_sp;
WORD e_csum;
WORD e_ip;
WORD e_cs;
WORD e_lfarlc;
WORD e_ovno;
WORD e_res[4];
WORD e_oemid;
WORD e_oeminfo;
WORD e_res2[10];
DWORD e_lfanew; // offset of IMAGE_NT_HEADER
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
Hay campos interesantes siguientes para nosotros:
-
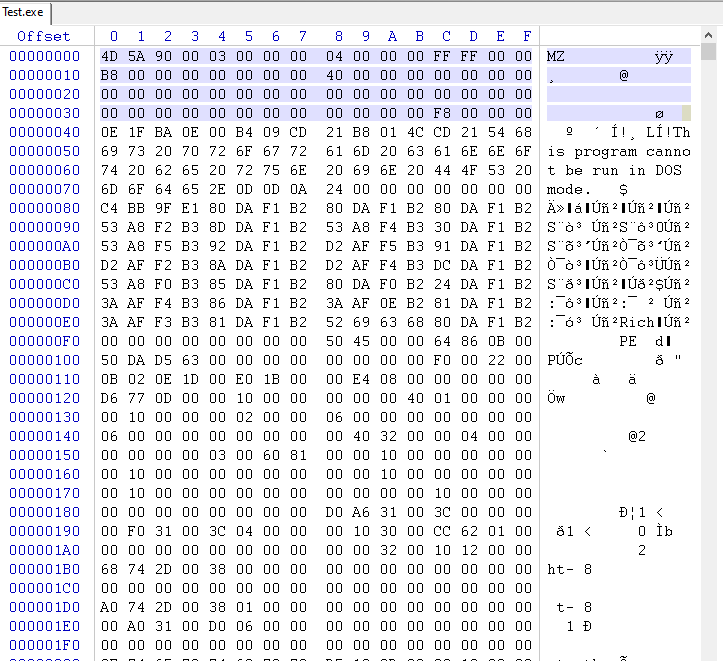
e_magic campo se utiliza para identificar el archivo como un archivo PE válido. Como puedes ver, el campo e_magic es un entero sin signo de 16 bits que especifica el "número mágico" del archivo. El número mágico es un valor especial que identifica el archivo como un archivo PE válido. Está establecido en el valor 0x5A4D (hexadecimal), que es la representación ASCII de los caracteres "MZ" (IMAGE_DOS_SIGNATURE).
-
e_lfanew campo se utiliza para especificar la ubicación de la estructura IMAGE_NT_HEADERS , que contiene información sobre la disposición y características del archivo PE. Como puedes ver, el campo e_lfanew es un entero con signo de 32 bits que especifica la ubicación de la estructura IMAGE_NT_HEADERS en el archivo. Generalmente se establece en el desplazamiento de la estructura relativo al inicio del archivo.
Historia
A principios de los años 1980, Microsoft estaba trabajando en un nuevo sistema operativo llamado MS-DOS, que estaba diseñado para ser un sistema operativo simple y ligero para computadoras personales. Una de las características clave de MS-DOS era su capacidad para ejecutar ejecutables, que son programas que se pueden correr en una computadora.
Para facilitar la identificación de los ejecutables, los desarrolladores de MS-DOS decidieron utilizar un "número mágico" especial al inicio de cada archivo ejecutable. Este número mágico se usaría para distinguir los ejecutables de otros tipos de archivos, como archivos de datos o archivos de configuración.
Mark Zbikowski, quien era desarrollador en el equipo de MS-DOS, tuvo la idea de usar los caracteres "MZ" como el número mágico. En código ASCII, la letra "M" está representada por el valor hexadecimal 0x4D, y la letra "Z" está representada por el valor hexadecimal 0x5A. Cuando estos valores se combinan, forman el número mágico 0x5A4D, que es la representación ASCII de los caracteres "MZ".
Hoy en día, la firma "MZ" todavía se utiliza para identificar archivos PE, que son el principal formato de archivo ejecutable utilizado en el sistema operativo Windows. Se almacena en el campo e_magic de la estructura IMAGE_DOS_HEADER , que es la primera estructura en un archivo PE.
IMAGE_NT_HEADER
La IMAGE_NT_HEADER es una estructura de datos que se introdujo con el sistema operativo Windows NT, el cual fue lanzado en 1993. Fue diseñada para proporcionar al sistema operativo una manera estándar de leer e interpretar los contenidos de los archivos ejecutables (archivos PE).
Con el lanzamiento de Windows NT, Microsoft introdujo el IMAGE_NT_HEADER como una forma de estandarizar el diseño y la estructura de los archivos ejecutables. Esto facilitó al sistema operativo la carga y ejecución de programas, ya que solo tenía que soportar un único formato.
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_nt_headers32
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_nt_headers64
typedef struct _IMAGE_NT_HEADERS32
{
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
typedef struct _IMAGE_NT_HEADERS64
{
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER64 OptionalHeader;
} IMAGE_NT_HEADERS64, *PIMAGE_NT_HEADERS64;
The IMAGE_NT_HEADER es una estructura que aparece al comienzo de cada archivo ejecutable portátil (PE) en el sistema operativo Windows. Contiene una serie de campos que proporcionan al sistema operativo información importante sobre el archivo ejecutable, como su tamaño, disposición y propósito previsto.
La estructura IMAGE_NT_HEADER se divide en dos secciones principales: el IMAGE_FILE_HEADER y el IMAGE_OPTIONAL_HEADER.

IMAGE_FILE_HEADER
El IMAGE_FILE_HEADER contiene información sobre el archivo ejecutable en su totalidad, incluyendo su tipo de máquina (por ejemplo, x86, x64), el número de secciones en el archivo y la fecha y hora en que el archivo fue creado.
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_file_header
typedef struct _IMAGE_FILE_HEADER
{
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
La estructura tiene los siguientes campos:
-
Machine: Este campo especifica la arquitectura objetivo para la cual se construyó el archivo. El valor de este campo lo determina el compilador cuando se construye el archivo. Algunos valores comunes son:
-
IMAGE_FILE_MACHINE_I386: El archivo está destinado a ejecutarse en arquitectura x86, también conocida como 32 bits.
-
IMAGE_FILE_MACHINE_AMD64: El archivo está destinado a ejecutarse en arquitectura x64, también conocida como 64 bits.
-
IMAGE_FILE_MACHINE_ARM: El archivo está destinado a ejecutarse en arquitectura ARM.
-
-
NumberOfSections: Este campo especifica el número de secciones en el archivo PE. Un archivo PE se divide en varias secciones, cada una de las cuales contiene diferentes tipos de información como código, datos y recursos. Este campo es utilizado por el sistema operativo para determinar cuántas secciones están presentes en el archivo.
-
TimeDateStamp: Este campo contiene la marca de tiempo de cuándo se construyó el archivo. La marca de tiempo se almacena como un valor de 4 bytes que representa el número de segundos desde el 1 de enero de 1970, 00:00:00 UTC. Este campo se puede utilizar para determinar cuándo se construyó por última vez el archivo, lo cual puede ser útil para la depuración o la gestión de versiones.
-
PointerToSymbolTable: Este campo especifica el desplazamiento de archivo de la tabla de símbolos COFF (Formato de Archivo de Objeto Común), si está presente. La tabla de símbolos COFF contiene información sobre los símbolos utilizados en el archivo, como nombres de funciones, nombres de variables y números de línea. Este campo solo se utiliza con fines de depuración y generalmente no está presente en las compilaciones de lanzamiento.
-
NumberOfSymbols: Este campo especifica el número de símbolos en la tabla de símbolos COFF, si está presente. Este campo se utiliza en conjunto con Puntero a la Tabla de Símbolos para localizar la tabla de símbolos COFF en el archivo.
-
SizeOfOptionalHeader: Este campo especifica el tamaño de la cabecera opcional, que contiene información adicional sobre el archivo. La cabecera opcional típicamente incluye información sobre el punto de entrada del archivo, las bibliotecas importadas y el tamaño del stack y el heap.
-
Characteristics: Este campo especifica varios atributos del archivo. Algunos valores comunes son:
-
IMAGE_FILE_EXECUTABLE_IMAGE: El archivo es un archivo ejecutable.
-
IMAGE_FILE_DLL: El archivo es una biblioteca de vínculo dinámico (DLL).
-
IMAGE_FILE_32BIT_MACHINE: El archivo es un archivo de 32 bits.
-
IMAGE_FILE_DEBUG_STRIPPED: Al archivo se le ha eliminado la información de depuración.
-
Estos campos proporcionan información importante sobre el archivo que es utilizada por el sistema operativo al cargar el archivo en la memoria y ejecutarlo. Al comprender los campos en la estructura IMAGE_FILE_HEADER , puedes obtener un entendimiento más profundo de cómo están estructurados los archivos PE y cómo los utiliza el sistema operativo.
La mayoría de los valores posibles para cada campo se declaran en el archivo de cabecera WinNT.h
IMAGE_OPTIONAL_HEADER
La estructura IMAGE_FILE_HEADER es seguida por el encabezado opcional, que está descrito por la estructura IMAGE_OPTIONAL_HEADER . El encabezado opcional contiene información adicional sobre la imagen, como la dirección del punto de entrada, el tamaño de la imagen y la dirección del directorio de importación.
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_optional_header32
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_optional_header64
typedef struct _IMAGE_OPTIONAL_HEADER32
{
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
typedef struct _IMAGE_OPTIONAL_HEADER64
{
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
ULONGLONG ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
ULONGLONG SizeOfStackReserve;
ULONGLONG SizeOfStackCommit;
ULONGLONG SizeOfHeapReserve;
ULONGLONG SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER64, *PIMAGE_OPTIONAL_HEADER64;
Aquí tienes una descripción detallada de cada campo en la estructura IMAGE_OPTIONAL_HEADER :
-
Magic: Este campo especifica el tipo de cabecera opcional que está presente en el archivo PE. El valor más común es IMAGE_NT_OPTIONAL_HDR32_MAGIC para un archivo de 32 bits o IMAGE_NT_OPTIONAL_HDR64_MAGIC para un archivo de 64 bits.
-
MajorLinkerVersion y MinorLinkerVersion: Estos campos especifican la versión del enlazador que se utilizó para construir el archivo. El enlazador es una herramienta que se utiliza para combinar archivos objeto y bibliotecas en un único archivo ejecutable.
-
SizeOfCode: Este campo especifica el tamaño de la sección de código en el archivo. La sección de código contiene el código máquina para el archivo ejecutable.
-
SizeOfInitializedData: Este campo especifica el tamaño de la sección de datos inicializados en el archivo. La sección de datos inicializados contiene datos que se inicializan en tiempo de ejecución, como las variables globales.
-
SizeOfUninitializedData: Este campo especifica el tamaño de la sección de datos no inicializados en el archivo. La sección de datos no inicializados contiene datos que no se inicializan en tiempo de ejecución, como la sección bss.
-
AddressOfEntryPoint: Este campo especifica la dirección virtual del punto de entrada del archivo. El punto de entrada es la dirección inicial del programa y es la primera instrucción que se ejecuta cuando el archivo se carga en la memoria.
-
BaseOfCode: Este campo especifica la dirección virtual del inicio de la sección de código.
-
ImageBase: Este campo especifica la dirección virtual preferida en la que el archivo debe cargarse en la memoria. Esta dirección se utiliza como dirección base para todas las direcciones virtuales dentro del archivo.
-
SectionAlignment: Este campo especifica la alineación de las secciones dentro del archivo. Las secciones en el archivo típicamente están alineadas en múltiplos de este valor para mejorar el rendimiento.
-
FileAlignment: Este campo especifica la alineación de las secciones dentro del archivo en el disco. Las secciones en el archivo típicamente están alineadas en múltiplos de este valor para mejorar el rendimiento del disco.
-
MajorOperatingSystemVersion y MinorOperatingSystemVersion: Estos campos especifican la versión mínima requerida del sistema operativo que se necesita para ejecutar el archivo.
-
MajorImageVersion y MinorImageVersion: Estos campos especifican la versión de la imagen. La versión de la imagen se utiliza para identificar la versión del archivo con fines de gestión de versiones.
-
MajorSubsystemVersion y MinorSubsystemVersion: Estos campos especifican la versión del subsistema que se requiere para ejecutar el archivo. El subsistema es el entorno en el que se ejecuta el archivo, como la Consola de Windows o la GUI de Windows.
-
Win32VersionValue: Este campo está reservado y típicamente se establece en 0.
-
SizeOfImage: Este campo especifica el tamaño de la imagen, en bytes, cuando se carga en la memoria.
-
SizeOfHeaders: Este campo especifica el tamaño de las cabeceras, en bytes. Las cabeceras incluyen el IMAGE_FILE_HEADER y el IMAGE_OPTIONAL_HEADER.
-
CheckSum: Este campo se utiliza para verificar la integridad del archivo. La suma de verificación se calcula sumando los contenidos del archivo y almacenando el resultado en este campo. La suma de verificación se utiliza para detectar cambios en el archivo que pueden ocurrir debido a manipulación o corrupción.
-
Subsystem: Este campo especifica el subsistema que se requiere para ejecutar el archivo. Los valores posibles incluyen IMAGE_SUBSYSTEM_NATIVE, IMAGE_SUBSYSTEM_WINDOWS_GUI, IMAGE_SUBSYSTEM_WINDOWS_CUI, IMAGE_SUBSYSTEM_OS2_CUI, etc.
-
DllCharacteristics: Este campo especifica las características del archivo, como si es una biblioteca de enlace dinámico (DLL) o si puede ser reubicado en el momento de la carga. Los valores posibles incluyen IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASE, IMAGE_DLLCHARACTERISTICS_NX_COMPAT, etc.
-
SizeOfStackReserve: Este campo especifica el tamaño de la pila, en bytes, que está reservada para el programa. La pila se utiliza para almacenar datos temporales, como la información de llamadas a funciones.
-
SizeOfStackCommit: Este campo especifica el tamaño de la pila, en bytes, que está comprometida para el programa. La pila comprometida es la porción de la pila que realmente está reservada en la memoria.
-
SizeOfHeapReserve: Este campo especifica el tamaño del montón, en bytes, que está reservado para el programa. El montón se utiliza para asignar memoria dinámicamente en tiempo de ejecución.
-
SizeOfHeapCommit: Este campo especifica el tamaño del montón, en bytes, que está comprometido para el programa. El montón comprometido es la porción del montón que realmente está reservada en la memoria.
-
LoaderFlags: Este campo está reservado y típicamente se establece en 0.
-
NumberOfRvaAndSizes: Este campo especifica el número de entradas de directorio de datos en el IMAGE_OPTIONAL_HEADER. Los directorios de datos contienen información sobre las importaciones, exportaciones, recursos, etc. en el archivo.
-
DataDirectory: Este campo es un arreglo de estructuras IMAGE_DATA_DIRECTORY que especifican la ubicación y el tamaño de los directorios de datos en el archivo
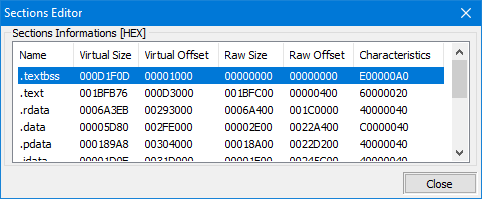
IMAGE_SECTION_HEADER
Una sección, en el contexto de un archivo PE (Ejecutable Portátil), es un bloque contiguo de memoria en el archivo que contiene un tipo específico de datos o código. En un archivo PE, las secciones se utilizan para organizar y almacenar diferentes partes del archivo, como el código, los datos, los recursos, etc.
Cada sección en un archivo PE tiene un nombre único y es descrita por una estructura IMAGE_SECTION_HEADER que contiene información sobre la sección como su tamaño, ubicación, características, etc. A continuación se presentan los campos de IMAGE_SECTION_HEADER:
Un IMAGE_SECTION_HEADER es una estructura de datos utilizada en el formato de archivo Portable Executable (PE), que se utiliza en el sistema operativo Windows para definir la distribución de un archivo en la memoria. El formato de archivo PE se utiliza para archivos ejecutables, DLLs y otros tipos de archivos que son cargados en la memoria por el sistema operativo Windows. Cada encabezado de sección describe un bloque contiguo de datos dentro del archivo e incluye información como el nombre de la sección, la dirección de memoria virtual en la que se debe cargar la sección y el tamaño de la sección. Los encabezados de sección se pueden utilizar para localizar y acceder a partes específicas del archivo, como las secciones de código o datos.
La estructura IMAGE_SECTION_HEADER está definida en el SDK de la Plataforma Windows, y se puede encontrar en el archivo de cabecera winnt.h. Aquí tienes un ejemplo de cómo se define la estructura en C++:
#pragma pack(push, 1)
typedef struct _IMAGE_SECTION_HEADER
{
BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; // 8
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
#pragma pack(pop)
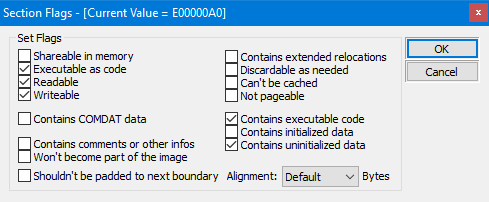
Como puedes ver, la estructura está definida como una estructura de C++ y contiene campos para el nombre de la sección, tamaño virtual, dirección virtual, tamaño de los datos brutos, y puntero a datos brutos, reubicaciones, números de línea, y el número de reubicaciones y números de línea. Además, el campo de Características contiene banderas que describen las características de la sección, tales como si es ejecutable, legible o escribible.
-
Name: Esta matriz de 8 bytes se utiliza para especificar el nombre de la sección. El nombre puede ser cualquier cadena terminada en nulo, pero se utiliza típicamente para dar nombres significativos a diferentes partes del archivo, como ".text" para código ejecutable, ".data" para datos inicializados, ".rdata" para datos de solo lectura y ".bss" para datos no inicializados. El nombre de la sección es utilizado por el sistema operativo para localizar la sección dentro del archivo, y también es utilizado por depuradores y otras herramientas para identificar la sección y su contenido.
-
VirtualSize: Este campo especifica el tamaño de la sección en memoria, en bytes. Este valor representa la cantidad de memoria que la sección ocupará en memoria cuando el archivo se cargue en memoria. El tamaño virtual de la sección es utilizado por el sistema operativo para determinar la cantidad de memoria que necesita ser asignada para la sección cuando el archivo se carga en memoria.
-
VirtualAddress: Este campo especifica la dirección de inicio de la sección en memoria, en bytes. Este valor es la dirección de inicio en la que la sección será cargada en memoria, y es utilizada por el sistema operativo para determinar la ubicación en la memoria donde la sección será cargada. La dirección virtual de la sección también es utilizada por el sistema operativo para resolver direcciones dentro de la sección, de modo que puedan ser correctamente traducidas a direcciones de memoria cuando el archivo se carga en memoria.
-
SizeOfRawData: Este campo especifica el tamaño de la sección en el archivo, en bytes. Este valor representa la cantidad de espacio en el archivo que la sección ocupará, y es utilizado por el sistema operativo para determinar el tamaño de la sección en el archivo. El tamaño de los datos crudos de una sección es utilizado por el sistema operativo para localizar la sección dentro del archivo, y para determinar el tamaño de la sección cuando se carga en memoria.
-
PointerToRawData: Este campo especifica el desplazamiento de la sección en el archivo, en bytes. Este valor representa la ubicación de la sección dentro del archivo, y es utilizado para determinar dónde se pueden encontrar los datos de la sección. El puntero a los datos crudos de una sección es utilizado por el sistema operativo para localizar la sección dentro del archivo, y para determinar la ubicación de la sección cuando se carga en memoria.
-
PointerToRelocations: Este campo especifica el desplazamiento de la información de relocalización para la sección, en bytes. La información de relocalización es utilizada para ajustar direcciones dentro de la sección, de modo que puedan ser correctamente resueltas cuando el archivo se carga en memoria. El puntero a las relocalizaciones de una sección es utilizado por el sistema operativo para localizar la información de relocalización para la sección, y para determinar cómo ajustar las direcciones dentro de la sección cuando el archivo se carga en memoria.
-
PointerToLinenumbers: Este campo especifica el desplazamiento de la información de números de línea para la sección, en bytes. La información de números de línea es utilizada para propósitos de depuración, y proporciona información sobre el código fuente que generó la sección. El puntero a los números de línea de una sección es utilizado por depuradores y otras herramientas para identificar el código fuente que generó la sección, y para proporcionar información más detallada sobre los contenidos de la sección.
-
NumberOfRelocations: Este campo especifica el número de entradas de relocalización para la sección. Una entrada de relocalización es un registro que describe cómo ajustar una dirección dentro de la sección, de modo que pueda ser correctamente resuelta cuando el archivo se carga en memoria. El número de relocalizaciones de una sección es utilizado por el sistema operativo para determinar el tamaño de la información de relocalización para la sección, y para saber cuántas entradas de relocalización necesitan ser procesadas cuando el archivo se carga en memoria.
-
NumberOfLinenumbers: Este campo especifica el número de entradas de números de línea para la sección. Una entrada de número de línea es un registro que proporciona información sobre el código fuente que generó la sección, y es utilizado para propósitos de depuración. El número de números de línea de una sección es utilizado por depuradores y otras herramientas para determinar el tamaño de la información de números de línea para la sección, y para saber cuántas entradas de números de línea necesitan ser procesadas para obtener información sobre el código fuente que generó la sección.
-
Characteristics: Este campo es un conjunto de banderas que especifican los atributos de la sección. Algunas de las banderas comunes utilizadas para secciones son: IMAGE_SCN_CNT_CODE para indicar que la sección contiene código ejecutable, IMAGE_SCN_CNT_INITIALIZED_DATA para indicar que la sección contiene datos inicializados, IMAGE_SCN_CNT_UNINITIALIZED_DATA para indicar que la sección contiene datos no inicializados, IMAGE_SCN_MEM_EXECUTE para indicar que la sección puede ser ejecutada, IMAGE_SCN_MEM_READ para indicar que la sección puede ser leída, y IMAGE_SCN_MEM_WRITE para indicar que la sección puede ser escrita. Estas banderas son utilizadas por el sistema operativo para determinar las propiedades de la sección, y para saber cómo manejar la sección cuando el archivo se carga en memoria.
Estos campos son utilizados por el sistema operativo y otros programas para gestionar la disposición de la memoria del archivo, y para localizar y acceder a partes específicas del archivo, como las secciones de código o de datos.
IMPORTANTE: En el contexto de la estructura IMAGE_NT_HEADER , que se utiliza en el formato de archivo Ejecutable Portátil (PE), los campos VirtualAddress y PhysicalAddress se refieren a cosas diferentes.
El campo VirtualAddress se utiliza para especificar la dirección virtual en la que se carga en memoria la sección que contiene la estructura IMAGE_NT_HEADER en tiempo de ejecución. Esta dirección es relativa a la dirección base del proceso y es utilizada por el programa para acceder a los datos de la sección.
El campo PhysicalAddress se utiliza para especificar el desplazamiento del archivo de la sección que contiene la estructura IMAGE_NT_HEADER en el archivo PE. Es utilizado por el sistema operativo para localizar los datos de la sección en el archivo cuando se carga en la memoria.
Todos los campos de encabezado y desplazamientos para IMAGE_NT_HEADER están definidos para la memoria y operan sobre direcciones virtuales. Si necesitas desplazar cualquier campo en el disco, necesitas convertir la dirección virtual a una dirección física usando la función rva2offset en el código a continuación.
En resumen, VirtualAddress es utilizado por el programa para acceder a la sección en la memoria y PhysicalAddress es utilizado por el sistema operativo para localizar la sección en el archivo.

IMPORTAR
Cuando un programa se compila, el compilador genera archivos objeto que contienen el código máquina de las funciones del programa. Sin embargo, los archivos objeto podrían no tener toda la información necesaria para que el programa funcione. Por ejemplo, los archivos objeto pueden contener llamadas a funciones que no están definidas en el programa, sino que son proporcionadas por bibliotecas externas.
Este es el lugar donde entra en juego la tabla de importación. La tabla de importación enumera las dependencias externas del programa y las funciones que el programa necesita importar de estas dependencias. El enlazador dinámico utiliza esta información en tiempo de ejecución para resolver las direcciones de las funciones importadas y enlazarlas al programa.
Por ejemplo, considera un programa que utiliza las funciones del sistema operativo Windows. El programa puede contener llamadas a la función MessageBox de la biblioteca user32.dll, que muestra un cuadro de mensaje en la pantalla. Para resolver la dirección de la función MessageBox, el programa necesita incluir una importación de user32.dll en su tabla de importaciones.
De manera similar, si un programa necesita utilizar funciones de una biblioteca de terceros, necesita incluir una importación para esa biblioteca en su tabla de importaciones. Por ejemplo, un programa que utiliza las funciones de la biblioteca OpenSSL incluiría una importación para la biblioteca libssl.dll en su tabla de importaciones.
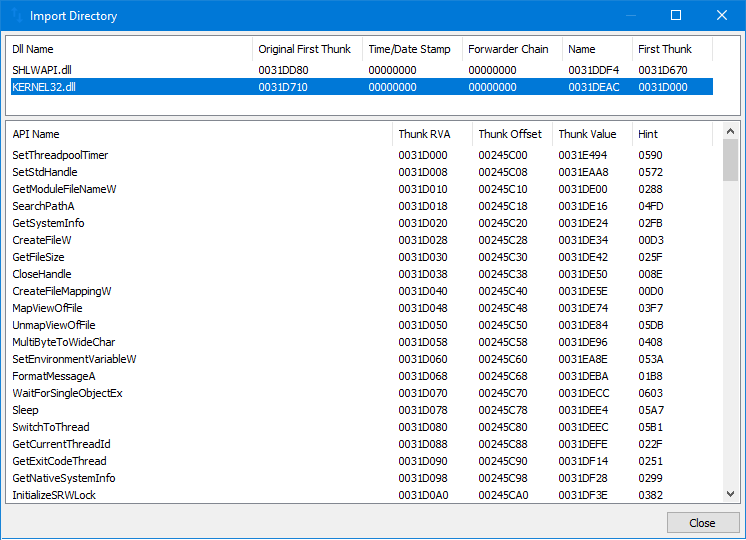
IMAGE_IMPORT_DIRECTORY
El IMAGE_IMPORT_DIRECTORY es una estructura de datos que es utilizada por el sistema operativo Windows para importar funciones y datos desde bibliotecas de vínculos dinámicos (DLLs) a un archivo ejecutable portátil (PE). Es parte del IMAGE_DATA_DIRECTORY, que es una tabla de estructuras de datos almacenada en el IMAGE_OPTIONAL_HEADER de un archivo PE.
El IMAGE_IMPORT_DIRECTORY es utilizado por el cargador de Windows para resolver las funciones y datos importados que son utilizados por el archivo PE. Esto lo hace mapeando las direcciones de las funciones y datos importados a las direcciones de las funciones y datos correspondientes en las DLLs. Esto permite que el archivo PE utilice las funciones y datos de las DLLs como si fueran parte del propio archivo PE.
El IMAGE_IMPORT_DIRECTORY consiste en una serie de estructuras IMAGE_IMPORT_DESCRIPTOR , cada una de las cuales describe una sola DLL que es importada por el archivo PE. Cada estructura IMAGE_IMPORT_DESCRIPTOR contiene los siguientes campos:
-
OriginalFirstThunk: un puntero a una tabla de funciones importadas.
-
TimeDateStamp: la fecha y hora de la última actualización de la DLL.
-
ForwarderChain: una cadena de funciones importadas reenviadas.
-
Name: el nombre de la DLL como una cadena terminada en nulo.
-
FirstThunk: un puntero a una tabla de funciones importadas que están vinculadas a la DLL.
typedef struct _IMAGE_IMPORT_DESCRIPTOR
{
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date ime stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name;
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;
Tabla OriginalFirstThunk (o FirstThunk si OriginalFirstThunk es 0)
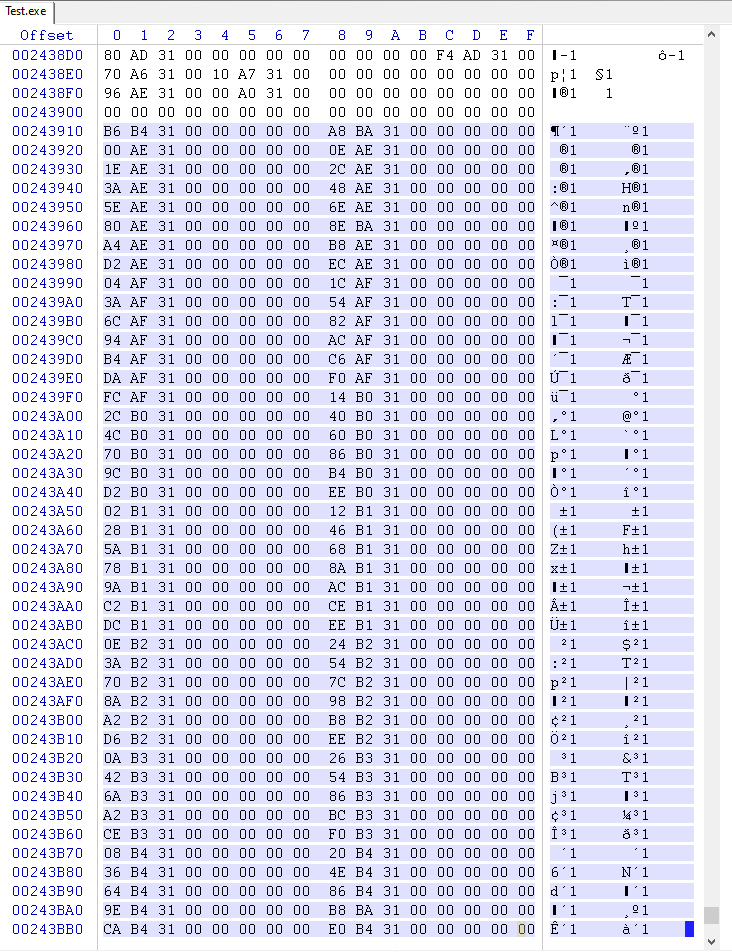
Cadenas señaladas por la tabla de desplazamientos (tabla OriginalFirstThunk o FirstThunk si OriginalFirstThunk es 0)

¿CÓMO FUNCIONA?
¡El mecanismo de importación implementado por Microsoft es compacto y hermoso!
Las direcciones de todas las funciones de bibliotecas de terceros (incluyendo las del sistema operativo Windows) que utiliza la aplicación se almacenan en una tabla especial - la tabla de importaciones. Esta tabla se llena cuando se carga el módulo (sobre otros mecanismos para llenar importaciones hablaremos más adelante).
Además, cada vez que se llama a una función de una biblioteca de terceros, el compilador generalmente genera el siguiente código:
call dword ptr [__cell_with_address_of_function] // for x86 architecture
call qword ptr [__cell_with_address_of_function] // for x64 architecture
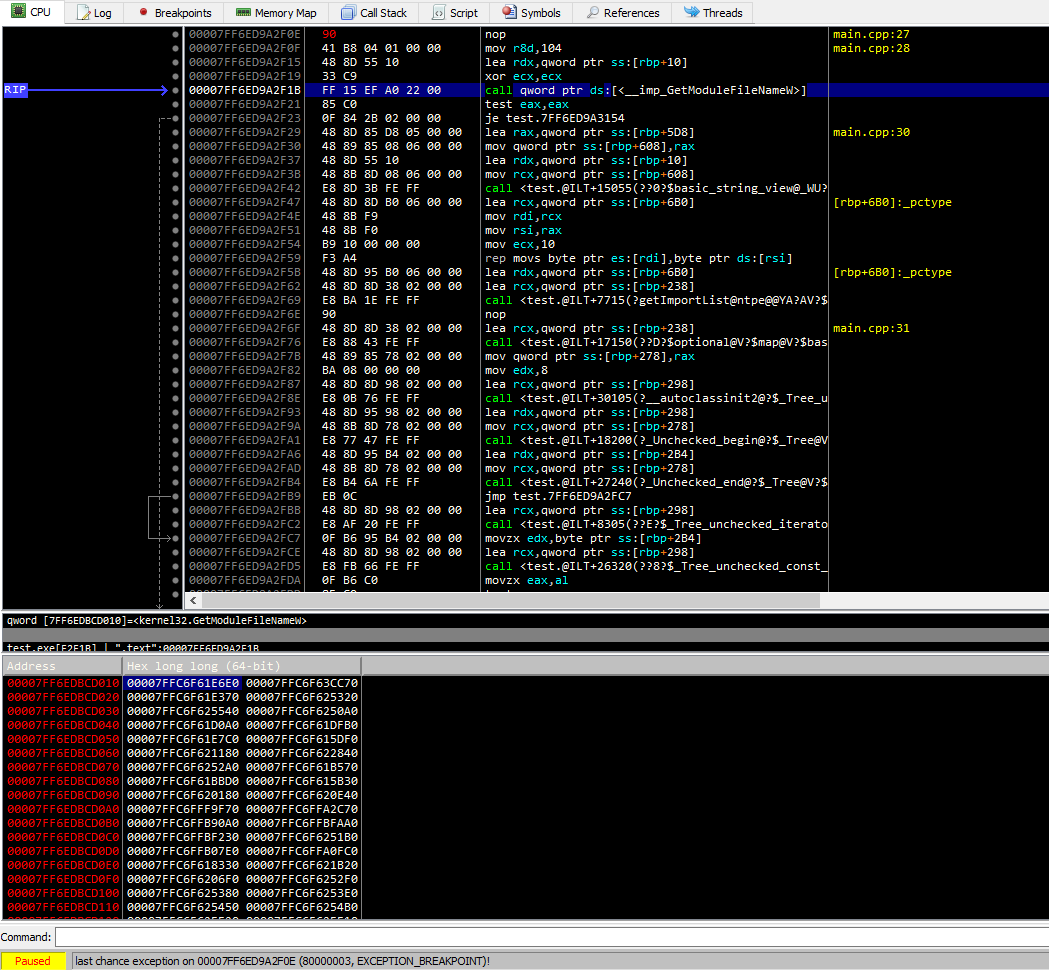
Así, para poder llamar a una función de una biblioteca, el cargador del sistema solo necesita escribir la dirección de esta función una vez en un lugar en la imagen.
ANALIZADOR DE C++
¡Y ahora escribiremos el analizador más simple (compatible con x86 y x64) de la tabla de importación de archivos ejecutables!
#include "stdafx.h"
/*
*
* Copyright (C) 2022, SToFU Systems S.L.
* All rights reserved.
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation; either version 2 of the License, or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License along
* with this program; if not, write to the Free Software Foundation, Inc.,
* 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
*
*/
namespace ntpe
{
static constexpr uint64_t g_kRvaError = -1;
// These types is defined in NTPEParser.h
// typedef std::map< std::string, std::set< std::string >> IMPORT_LIST;
// typedef std::vector< IMAGE_SECTION_HEADER > SECTIONS_LIST;
//**********************************************************************************
// FUNCTION: alignUp(DWORD value, DWORD align)
//
// ARGS:
// DWORD value - value to align.
// DWORD align - alignment.
//
// DESCRIPTION:
// Aligns argument value with the given alignment.
//
// Documentation links:
// Alignment: https://learn.microsoft.com/en-us/cpp/cpp/alignment-cpp-declarations?view=msvc-170
//
// RETURN VALUE:
// DWORD aligned value.
//
//**********************************************************************************
DWORD alignUp(DWORD value, DWORD align)
{
DWORD mod = value % align;
return value + (mod ? (align - mod) : 0);
};
//**********************************************************************************
// FUNCTION: rva2offset(IMAGE_NTPE_DATA& ntpe, DWORD rva)
//
// ARGS:
// IMAGE_NTPE_DATA& ntpe - data from PE file.
// DWORD rva - relative virtual address.
//
// DESCRIPTION:
// Parse RVA (relative virtual address) to offset.
//
// RETURN VALUE:
// int64_t offset.
// g_kRvaError (-1) in case of error.
//
//**********************************************************************************
int64_t rva2offset(IMAGE_NTPE_DATA& ntpe, DWORD rva)
{
/* retrieve first section */
try
{
/* if rva is inside MZ header */
PIMAGE_SECTION_HEADER sec = ntpe.sectionDirectories;
if (!ntpe.fileHeader->NumberOfSections || rva < sec->VirtualAddress)
return rva;
/* walk on sections */
for (uint32_t sectionIndex = 0; sectionIndex < ntpe.fileHeader->NumberOfSections; sectionIndex++, sec++)
{
/* count section end and allign it after each iteration */
DWORD secEnd = ntpe::alignUp(sec->Misc.VirtualSize, ntpe.SecAlign) + sec->VirtualAddress;
if (sec->VirtualAddress <= rva && secEnd > rva)
return rva - sec->VirtualAddress + sec->PointerToRawData;
};
}
catch (std::exception&)
{
}
return g_kRvaError;
};
//**********************************************************************************
// FUNCTION: getNTPEData(char* fileMapBase)
//
// ARGS:
// char* fileMapBase - the starting address of the mapped file.
//
// DESCRIPTION:
// Parses following data from mapped PE file.
//
// Documentation links:
// PE format structure: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format
//
// RETURN VALUE:
// std::optional< IMAGE_NTPE_DATA >.
// std::nullopt in case of error.
//
//**********************************************************************************
#define initNTPE(HeaderType, cellSize) \
{ \
char* ntstdHeader = (char*)fileHeader + sizeof(IMAGE_FILE_HEADER); \
HeaderType* optHeader = (HeaderType*)ntstdHeader; \
data.sectionDirectories = (PIMAGE_SECTION_HEADER)(ntstdHeader + sizeof(HeaderType)); \
data.SecAlign = optHeader->SectionAlignment; \
data.dataDirectories = optHeader->DataDirectory; \
data.CellSize = cellSize; \
}
std::optional< IMAGE_NTPE_DATA > getNTPEData(char* fileMapBase, uint64_t fileSize)
{
try
{
/* PIMAGE_DOS_HEADER from starting address of the mapped view*/
PIMAGE_DOS_HEADER dosHeader = (IMAGE_DOS_HEADER*)fileMapBase;
/* return std::nullopt in case of no IMAGE_DOS_SIGNATUR signature */
if (dosHeader->e_magic != IMAGE_DOS_SIGNATURE)
return std::nullopt;
/* PE signature adress from base address + offset of the PE header relative to the beginning of the file */
PDWORD peSignature = (PDWORD)(fileMapBase + dosHeader->e_lfanew);
if ((char*)peSignature <= fileMapBase || (char*)peSignature - fileMapBase >= fileSize)
return std::nullopt;
/* return std::nullopt in case of no PE signature */
if (*peSignature != IMAGE_NT_SIGNATURE)
return std::nullopt;
/* file header address from PE signature address */
PIMAGE_FILE_HEADER fileHeader = (PIMAGE_FILE_HEADER)(peSignature + 1);
if (fileHeader->Machine != IMAGE_FILE_MACHINE_I386 &&
fileHeader->Machine != IMAGE_FILE_MACHINE_AMD64)
return std::nullopt;
/* result IMAGE_NTPE_DATA structure with info from PE file */
IMAGE_NTPE_DATA data = {};
/* base address and File header address assignment */
data.fileBase = fileMapBase;
data.fileHeader = fileHeader;
/* addresses of PIMAGE_SECTION_HEADER, PIMAGE_DATA_DIRECTORIES, SectionAlignment, CellSize depending on processor architecture */
switch (fileHeader->Machine)
{
case IMAGE_FILE_MACHINE_I386:
initNTPE(IMAGE_OPTIONAL_HEADER32, 4);
return data;
case IMAGE_FILE_MACHINE_AMD64:
initNTPE(IMAGE_OPTIONAL_HEADER64, 8);
return data;
}
}
catch (std::exception&)
{
}
return std::nullopt;
}
//**********************************************************************************
// FUNCTION: getImportList(IMAGE_NTPE_DATA& ntpe)
//
// ARGS:
// IMAGE_NTPE_DATA& ntpe - data from PE file.
//
// DESCRIPTION:
// Retrieves IMPORT_LIST(std::map< std::string, std::set< std::string >>) with all loaded into PE libraries names and imported functions.
// Map key: loaded dll's names.
// Map value: set of imported functions names.
//
// Documentation links:
// Import Directory Table: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#import-directory-table
//
// RETURN VALUE:
// std::optional< IMPORT_LIST >.
// std::nullopt in case of error.
//
//**********************************************************************************
std::optional< IMPORT_LIST > getImportList(IMAGE_NTPE_DATA& ntpe)
{
try
{
/* if no imaage import directory in file returns std::nullopt */
if (ntpe.dataDirectories[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress == 0)
return std::nullopt;
IMPORT_LIST result;
/* import table offset */
DWORD impOffset = rva2offset(ntpe, ntpe.dataDirectories[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress);
/* imoprt table descriptor from import table offset + file base adress */
PIMAGE_IMPORT_DESCRIPTOR impTable = (PIMAGE_IMPORT_DESCRIPTOR)(impOffset + ntpe.fileBase);
/* while names in import table */
while (impTable->Name != 0)
{
/* pointer to DLL name from offset of current section name + file base adress */
std::string modname = rva2offset(ntpe, impTable->Name) + ntpe.fileBase;
std::transform(modname.begin(), modname.end(), modname.begin(), ::toupper);
/* start adress of names in look up table from import table name RVA */
char* cell = ntpe.fileBase + ((impTable->OriginalFirstThunk) ? rva2offset(ntpe, impTable->OriginalFirstThunk) : rva2offset(ntpe, impTable->FirstThunk));
/* while names in look up table */
for (;; cell += ntpe.CellSize)
{
int64_t rva = 0;
/* break if rva = 0 */
memcpy(&rva, cell, ntpe.CellSize);
if (!rva)
break;
/* if rva > 0 function was imported by name. if rva < 0 function was imported by ordinall */
if (rva > 0)
result[modname].emplace(ntpe.fileBase + rva2offset(ntpe, rva) + 2);
else
result[modname].emplace(std::string("#ord: ") + std::to_string(rva & 0xFFFF));
};
impTable++;
};
return result;
}
catch (std::exception&)
{
return std::nullopt;
}
};
//**********************************************************************************
// FUNCTION: getImportList(IMAGE_NTPE_DATA& ntpe)
//
// ARGS:
// std::wstring_view filePath - path to file.
//
// DESCRIPTION:
// Retrieves IMPORT_LIST(std::map< std::string, std::set< std::string >>) with all loaded into PE libraries names and imported functions bu path.
// Map key: loaded dll's names.
// Map value: set of imported functions names.
//
// Documentation links:
// Import Directory Table: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#import-directory-table
//
// RETURN VALUE:
// std::optional< IMPORT_LIST >.
// std::nullopt in case of error.
//
//**********************************************************************************
std::optional< IMPORT_LIST > getImportList(std::wstring_view filePath)
{
std::vector< char > buffer;
/* obtain base address of mapped file from tools::readFile function */
bool result = tools::readFile(filePath, buffer);
/* return nullopt if readFile failes or obtained buffer is empty */
if (!result || buffer.empty())
return std::nullopt;
/* get IMAGE_NTPE_DATA from base address of mapped file */
std::optional< IMAGE_NTPE_DATA > ntpe = getNTPEData(buffer.data(), buffer.size());
if (!ntpe)
return std::nullopt;
/* return result of overloaded getImportList function with IMAGE_NTPE_DATA as argument */
return getImportList(*ntpe);
}
//**********************************************************************************
// FUNCTION: getSectionsList(IMAGE_NTPE_DATA& ntpe)
//
// ARGS:
// IMAGE_NTPE_DATA& ntpe - data from PE file.
//
// DESCRIPTION:
// Retrieves SECTIONS_LIST from IMAGE_NTPE_DATA.
// SECTIONS_LIST - vector of sections headers from portable executable file.
// Sections names exmaple: .data, .code, .src
//
// Documentation links:
// IMAGE_SECTION_HEADER: https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_section_header
// Section Table (Section Headers): https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#section-table-section-headers
//
// RETURN VALUE:
// std::optional< SECTIONS_LIST >.
// std::nullopt in case of error.
//
//**********************************************************************************
std::optional< SECTIONS_LIST > getSectionsList(IMAGE_NTPE_DATA& ntpe)
{
try
{
/* result vector of section directories */
SECTIONS_LIST result;
/* iterations through all image section headers poiners in IMAGE_NTPE_DATA structure */
for (uint64_t sectionIndex = 0; sectionIndex < ntpe.fileHeader->NumberOfSections; sectionIndex++)
{
/* pushing IMAGE_SECTION_HEADER from iamge section headers */
result.push_back(ntpe.sectionDirectories[sectionIndex]);
}
return result;
}
catch (std::exception&)
{
}
/* returns nullopt in case of error */
return std::nullopt;
}
}
Puedes encontrar el código completo del proyecto en nuestro github:
https://github.com/SToFU-Systems/DSAVE
Lista de herramientas utilizadas
- Herramientas PE: https://github.com/petoolse/petools Esta es una herramienta de código abierto para manipular los campos del encabezado PE. Soporta archivos x86 y x64.
- WinDbg: https://learn.microsoft.com/en-us/windows-hardware/drivers/debugger/debugger-download-tools El depurador de sistemas de Microsoft. Indispensable en el trabajo de un programador de sistemas para Windows OS.
- x64Dbg: https://x64dbg.com Depurador open-source simple y ligero para windows x64/x86.
- WinHex: http://www.winhex.com/winhex/hex-editor.html WinHex es un editor hexadecimal universal, particularmente útil en el ámbito de la informática forense, recuperación de datos, edición de datos a bajo nivel.
¿QUÉ SIGUE?
Apreciamos su apoyo y esperamos contar con su participación continua en nuestra comunidad
En el próximo artículo escribiremos juntos el módulo de hashing difuso y abordaremos la cuestión de las listas negras y blancas.Simplest import table analyzer.
Cualquier pregunta para los autores del artículo puede enviarse al correo electrónico: articles@stofu.io
Gracias por su atención y que tenga un buen día!




