Hash
Först och främst, låt oss gå igenom grunderna och bekanta oss med ett sådant begrepp som en hash!
Hash-algoritm - är en matematisk funktion som tar emot data av valfri storlek och producerar en output kallad hash eller meddelandesammanfattning. Outputen är en unik representation av indatat, vilken kan användas för att verifiera att datan inte har manipulerats. Hash-algoritmer används för att säkerställa integritet och autenticitet hos data. I enkla termer är en hash ett unikt digitalt fingeravtryck av en datamängd. Det är som en kod som representerar datan. Koden genereras av en matematisk funktion kallad hashfunktion. Om datan förändras även lite, kommer hashen att vara annorlunda.
Det finns primära nyckelkarakteristika för hash:
-
Deterministisk: En hashfunktion ska alltid producera samma utdata för en given indata. Detta innebär att om du haschar samma data två gånger ska du få samma hashvärde båda gångerna.
-
Oåterkallebarhet: Det ska vara beräkningsmässigt ogenomförbart att rekonstruera den ursprungliga indatan från dess hashvärde. Denna egenskap är viktig för säkerheten, eftersom den skyddar den ursprungliga datan från att upptäckas av angripare som endast har tillgång till hashvärdet.
-
Uniformitet: En hashfunktion bör producera en jämn distribution av hashvärden över alla möjliga indata. Detta innebär att varje hashvärde bör vara lika sannolikt att förekomma, och det bör inte finnas några mönster eller skevheter i distributionen av hashvärden.
-
Oförutsägbarhet: Det ska vara beräkningsmässigt ogenomförbart att förutsäga hashvärdet av en indata baserat på hashvärden av andra indata eller egenskaperna hos hashfunktionen själv. Denna egenskap är viktig för säkerheten, eftersom det gör det svårt för angripare att skapa en kollision (två olika indata som producerar samma hashvärde).
-
Oåterkallebarhet: Det ska vara beräkningsmässigt ogenomförbart att rekonstruera den ursprungliga indatan från dess hashvärde. Denna egenskap är viktig för säkerheten, eftersom den skyddar den ursprungliga datan från att upptäckas av angripare som endast har tillgång till hashvärdet.
-
Motstånd mot kollisionsattacker: En hashfunktion bör vara resistent mot kollisionsattacker, som innebär att man hittar två olika indata som producerar samma hashvärde. Kollisionsattacker kan användas för att skapa falska digitala signaturer eller för att kringgå åtkomstkontroller, så det är viktigt att en hashfunktion är utformad för att motstå dem.
Andra egenskaper hos hashar som du kan hitta på Wikipedia-sidan:
https://en.wikipedia.org/wiki/Hash_function
Data verifiering. Svartlista och Vitlista.
I sammanhanget av antivirusprogram används hashalgoritmer för att upptäcka skadlig programvara eller utesluta falsklarm. Antivirusprogram underhåller en databas med kända hashvärden för skadlig programvara (svartlista) och betrodda programvaruhashar (vitlista). När en fil skannas jämförs dess hash med hasharna i databasen. De vanligast använda hashalgoritmerna för datakontroll är MD5, SHA-1, SHA-256 och SHA-512.
Användningen av hashar i antivirusprogrammens svarta och vita listor hjälper till att snabba upp skanningsprocessen, eftersom antivirusprogrammet inte behöver utföra en detaljerad analys av varje fil för att avgöra om den är skadlig eller inte. Istället kan det jämföra hashvärdena för filerna mot de som finns i svartlistan/vitlistan för att snabbt identifiera kända hot eller betrodda appar.
Svartlista. I sammanhanget av cybersäkerhet och antivirusprogram är en svartlista en lista över kända skadliga filer eller delar av dessa filer. När ett antivirusprogram skannar en dator eller ett nätverk jämför det filerna och enheterna det stöter på mot svartlistan för att identifiera eventuella hot. Om en fil eller enhet matchar en post på svartlistan kommer antivirusprogrammet att vidta åtgärder för att ta bort eller sätta filen i karantän för att förhindra att den orsakar skada.
Även om svartlistor kan vara användbara för att upptäcka och förebygga kända hot, är de inte alltid effektiva för att skydda mot nya och okända hot. Angripare kan använda olika tekniker, såsom obfuskering eller polymorfism, för att modifiera koden eller beteendet hos en fil eller enhet för att undvika upptäckt av antivirusprogram.
Därför använder antivirusprogram ofta en kombination av tekniker, såsom whitelisting och beteendebaserad detektion, för att komplettera användningen av svartlistor och erbjuda ett mer omfattande skydd mot ett bredare spektrum av hot.
Whitelist. I sammanhanget av cybersäkerhet och antivirusprogram, är en whitelist en lista över betrodda filer som är kända för att vara säkra. Om en fil eller enhet matchar en post på whitelisten, kommer antivirusprogrammet att tillåta den att öppnas/köras utan att vidta någon åtgärd, eftersom den anses vara säker.
Vitlistor är användbara för att förhindra falska positiva resultat i antivirus- och säkerhetsprogram. Falska positiva resultat inträffar när ett program eller en fil markeras som skadlig eller farlig när den i själva verket är säker. Genom att använda en vitlista kan säkerhetsprogram undvika dessa falska positiva resultat, vilket kan spara tid och förhindra onödiga larm.
Användning av hashar och svartlistor/vitlistor kan vara ett effektivt sätt att skydda mot kända hot och förhindra falska positiva resultat i antivirus- och säkerhetsprogram.
Varför använder antivirusprogram flera hash-algoritmer?
Antivirusprogram använder flera hashalgoritmer av flera anledningar:
-
Medan svartlistor kan vara effektiva för att upptäcka och förhindra kända hot, är de inte felfria. Angripare kan använda olika tekniker för att undvika upptäckt, såsom att modifiera data för att undvika att matcha signaturerna i svartlistan. Dessa tekniker kallas "kollisionsattacker". En kollisionattack är en typ av kryptografisk attack där en angripare försöker hitta två olika inmatningar, som filer eller meddelanden, som producerar samma hashvärde när de körs genom en hashfunktion (kollision). Målet med en kollisionattack är att skapa ett par av inmatningar som kan användas för att kringgå ett system som är beroende av integriteten hos hashvärden, såsom digitala signaturer, lösenordsautentisering eller kontroller av dataintegritet. Om en angripare kan hitta en kollision kan han använda den för att kringgå de säkerhetsåtgärder som är beroende av hashfunktionen. För att minska risken för kollisionsattacker använder antivirusprogram starka hashfunktioner som är motståndskraftiga mot attacker och använder flera hashfunktioner samtidigt. Till exempel, om ett antivirusprogram endast använde MD5-hashalgoritmen, så kunde en angripare potentiellt skapa en skadlig fil som har samma MD5-hash som en legitim fil och lura antivirusprogrammet att behandla den skadliga filen som säker. Att använda flera hashalgoritmer, såsom MD5, SHA-1 och SHA-256, gör det dock svårare för en angripare att skapa en kollisionsattack som skulle fungera mot alla algoritmer samtidigt.
-
Effektivitet: Olika hashalgoritmer har olika beräkningskrav och vissa kan vara mer effektiva än andra beroende på filstorlek, typ eller andra faktorer. Att använda flera hashalgoritmer tillåter antivirusprogram att välja den mest lämpliga algoritmen för en given situation, vilket kan spara tid och processorkraft. Till exempel kan SHA-256 vara mer beräkningsintensiv än MD5, så ett antivirusprogram kan välja att använda MD5 för mindre filer och SHA-256 för större filer.
-
Flexibilitet: Olika hashalgoritmer är utformade för olika användningsområden och applikationer. Genom att använda flera hashalgoritmer kan antivirusprogram anpassa sig till olika behov och scenarier, såsom att upptäcka skadlig programvara, verifiera filintegritet eller upptäcka manipulering eller modifiering. Till exempel kan en forensisk utredare använda en annan hashalgoritm än ett antivirusprogram för att säkerställa att data inte har modifierats under en undersökning.
Att använda flera hashalgoritmer är en bästa praxis inom cybersäkerhet och utveckling av antivirusprogram, eftersom det ger robusthet, kompatibilitet, effektivitet och flexibilitet i detektering och förebyggande av cyberhot.
Hur känner antivirusprogram igen liknande men inte identiska data och filer?
Similära men inte identiska filer kan vara ett problem inom cybersäkerhet eftersom de kan användas av angripare för att undvika upptäckt av antivirusprogram.
Till exempel kan en angripare ta en känd skadlig fil och göra små ändringar i dess kod eller struktur, till exempel genom att ändra variabelnamn eller omorganisera instruktioner. Dessa ändringar kan vara tillräckliga för att skapa en ny fil som är liknande men inte identisk med den ursprungliga skadliga filen, och som kanske inte upptäcks av antivirusprogram som förlitar sig på traditionella hash-baserade detekteringsmetoder.
Dessutom kan angripare använda liknande men inte identiska filer för att skapa polymorfisk skadlig programvara, som kan ändra sin kod eller struktur med varje infektion för att undvika upptäckt. Polymorfisk skadlig programvara kan vara mycket svår att upptäcka med traditionella antivirusmetoder, som bygger på att känna igen specifika mönster eller signaturer i skadeprogrammets kod.
För att lösa detta problem använder antivirusprogram fuzzy hashar.
Fuzzy hashing är en teknik som används av vissa antivirusprogram för att upptäcka liknande, men inte identiska filer, inklusive polymorfisk skadprogramvara. Genom att dela upp en fil i mindre bitar och jämföra hashar av dessa bitar med hashar av andra filer, kan fuzzy hashing identifiera filer som har liknande kod eller struktur, även om de inte är identiska.
Fuzzy hashing fungerar genom att identifiera sekvenser av byte som förekommer frekvent över hela filen. Dessa sekvenser, även kända som "chunks," hashas sedan med en kryptografisk hashfunktion för att generera ett hashvärde. Hashvärdena för dessa chunks jämförs sedan med dem från andra filer för att identifiera liknande chunks.
Fördelen med fuzzy hashing är att det kan upptäcka likheter även när filer har modifierats eller dolt, vilket gör det till ett kraftfullt verktyg för att identifiera varianter av känd malware. Till exempel, om en angripare modifierar en känd malware-fil genom att ändra namnen på variabler eller funktioner, kanske traditionella hash-baserade detektionsmetoder inte upptäcker den modifierade filen. Fuzzy hashing kan dock fortfarande upptäcka den modifierade filen genom att identifiera bitar som liknar dem i den ursprungliga malware-filen. Till skillnad från kryptografiska hashningsalgoritmer som MD5, SHA-1 eller SHA-512, producerar fuzzy hashningsalgoritmer variabla hashvärden som baseras på likheten i indatat.
Fördelar med fuzzy hashes:
-
Upptäckt av liknande filer: Fuzzy hashes kan upptäcka liknande filer även om de har modifierats något, vilket är användbart för att identifiera varianter av känd skadlig programvara.
-
Minskat antal falska positiva: Fuzzy hashes kan minska antalet falska positiva som genereras av traditionella hashbaserade detektionsmetoder. Detta beror på att fuzzy hashes kan upptäcka filer som är liknande men inte identiska med känd skadlig programvara.
-
Resistens mot maskering: Fuzzy hashes är mer motståndskraftiga mot maskeringstekniker som används av angripare för att undvika upptäckt. Detta beror på att fuzzy hash-algoritmen bryter ner filen i mindre delar och genererar hashar för varje del, vilket gör det svårare för en angripare att modifiera filen på ett sätt som undviker upptäckt.
Fuzzy hashing har vissa begränsningar som kan påverka dess effektivitet när det gäller att upptäcka liknande, men inte identiska filer:
Falska positiva: Fuzzy hashing kan producera falska positiva resultat, där legitima filer flaggas som skadliga eftersom de har liknande kod eller struktur som känd skadlig programvara. Detta kan inträffa om filerna delar gemensamma bibliotek eller ramverk.
Prestanda: Fuzzy hashing kan vara beräkningsintensivt, särskilt för stora filer. Detta kan fördröja skanningsprocessen och påverka systemets prestanda.
Storleksbegränsningar: Fuzzy hashing kanske inte fungerar väl på mycket små filer eller filer med låg entropi, då det kanske inte finns tillräckligt unika bitar för att generera meningsfulla hashar.
Manipulering: Fuzzy hashing kan vara ineffektivt om en angripare specifikt riktar in sig på det och modifierar en fil för att undvika upptäckt. Till exempel kunde en angripare medvetet ändra strukturen på en fil för att förhindra att den identifieras av fuzzy hashing.
Vad är skillnaden mellan kryptografiska hashalgoritmer och fuzzy hashalgoritmer?
Kryptografiska hashalgoritmer och fuzzy hashalgoritmer används båda inom cybersäkerhet, men de har olika syften och egenskaper.
Kryptografiska hashalgoritmer, såsom SHA-256 och MD5, är utformade för att tillhandahålla dataintegritet och äkthet genom att generera hashvärden av fast längd som är nästan omöjliga att backa. Kryptografiska hashalgoritmer används för att verifiera dataintegritet.
Fuzzy hash-algoritmer, så som SSDEEP, är utformade för att identifiera liknande men inte identiska data, såsom filer som har modifierats eller omförpackats av skapare av skadlig kod. Fuzzy hashing använder en teknik med glidande fönster för att dela upp data i små bitar och generera variabellängd, probabilistiska hashar som jämförs mot en databas med kända skadliga kodhashar för att identifiera potentiellt skadliga filer.
Kryptografiska hashalgoritmer är utformade för att vara kollisionsresistenta, vilket innebär att det är extremt svårt att hitta två indata som producerar samma hashutdata. Fuzzy hash-algoritmer behöver inte vara kollisionsresistenta eftersom de är utformade för att upptäcka likheter mellan filer snarare än att producera unika hashutdata
Den huvudsakliga skillnaden mellan kryptografiska hashalgoritmer och fuzzy hashalgoritmer är deras nivå av determinism. Kryptografiska hashalgoritmer producerar fasta längder, deterministiska hashar som är unika för varje indata, medan fuzzy hashalgoritmer producerar variabla längder, probabilistiska hashar som är liknande för liknande indata.
Vilka fuzzy hashing-algoritmer kommer vi att använda i vår lösning?
I vår lösning kommer vi att använda SSDEEP och TLSH.
ssdeep är en suddig hashningsalgoritm som används för att identifiera liknande men inte identiska data, såsom malwarevarianter. Den fungerar genom att generera ett hashvärde som representerar likheten hos indata, snarare än en unik identifierare som kryptografiska hashfunktioner. Utdata från ssdeep är av variabel längd och probabilistisk, vilket gör att den kan upptäcka även mindre skillnader mellan två filer. ssdeep används vanligtvis i analys och upptäckt av malware och är också integrerad i olika säkerhetsverktyg och antivirusprogram.
TLSH (Trend Micro Locality Sensitive Hash) är en fuzzy hashningsalgoritm som används för att identifiera liknande men inte identiska data, såsom malware-varianter. Den fungerar genom att skapa ett hashvärde som fångar de unika egenskaperna hos indata, såsom bytefrekvens och ordning. Utdata från TLSH är av variabel längd och probabilistisk, vilket gör att den kan upptäcka likheter även om indatan har modifierats eller förfalskats. TLSH används vanligtvis i analys och detektion av malware, och den är också integrerad i olika säkerhetsverktyg och antivirusprogram.
ssdeep och TLSH använder båda avståndsmått för att bestämma likheten mellan två hash-värden. Dock är avståndsmåtten som används av ssdeep och TLSH olika.
ssdeep använder metriken "fuzzy hash distance" för att beräkna avståndet mellan två hashvärden. Denna avståndsmetrik är baserad på antalet matchande och icke-matchande block mellan de två hasharna, samt storleken på hasharna. Avståndsmetriken är ett procentuellt värde som sträcker sig från 0 till 100, där 0 innebär att de två hasharna är identiska, och 100 innebär att de två hasharna är helt olika.
TLSH använder å andra sidan "total diff"-metriken för att beräkna avståndet mellan två hashvärden. Denna avståndsmetrik baseras på skillnaden mellan de lokalitet-känsliga funktionerna hos de två datamängderna. Resultatet av "total diff"-metriken är ett värde mellan 0 och 1000, där 0 innebär att de två hashvärdena är identiska, och 1000 innebär att de två hashvärdena är helt olika.
Bygga hashningsmodulen
För vår lösning kommer vi att använda öppen källkods-bibliotek:
1. PolarSSL: https://polarssl.org/
PolarSSL är ett fritt och öppen källkod mjukvarubibliotek för att implementera kryptografiska protokoll såsom Transport Layer Security (TLS), Secure Sockets Layer (SSL), Datagram Transport Layer Security (DTLS). Det tillhandahåller olika kryptografiska algoritmer och protokoll, inklusive hashfunktioner, symmetrisk och asymmetrisk kryptering, digitala signaturer och nyckelutbytesalgoritmer. PolarSSL är designat för att vara lättviktigt och effektivt, vilket gör det lämpligt för användning i resursbegränsade miljöer.
2. ssdeep: http://ssdeep.sf.net/
3. TLSH: https://github.com/trendmicro/tlsh/
Efter att ha implementerat biblioteken i projektet lägger vi till en enkel kod:
struct HashData
{
BYTE md5[16];
BYTE sha1[20];
BYTE sha512[64];
std::string ssdeep;
std::string tlsh;
};
HashData hash(const void* buff, uint64_t size)
{
HashData snap = {};
hashes::md5(buff, size, snap.md5);
hashes::sha1(buff, size, snap.sha1);
hashes::sha4(buff, size, snap.sha512);
snap.ssdeep = hashes::ssdeepHash(buff, size);
snap.tlsh = hashes::tlshHash(buff, size);
return snap;
}
Kontrollera hashningsmodulen
Det är dags att testa hashningsmodulen! För att göra detta kommer vi att skapa en textfil med följande innehåll:
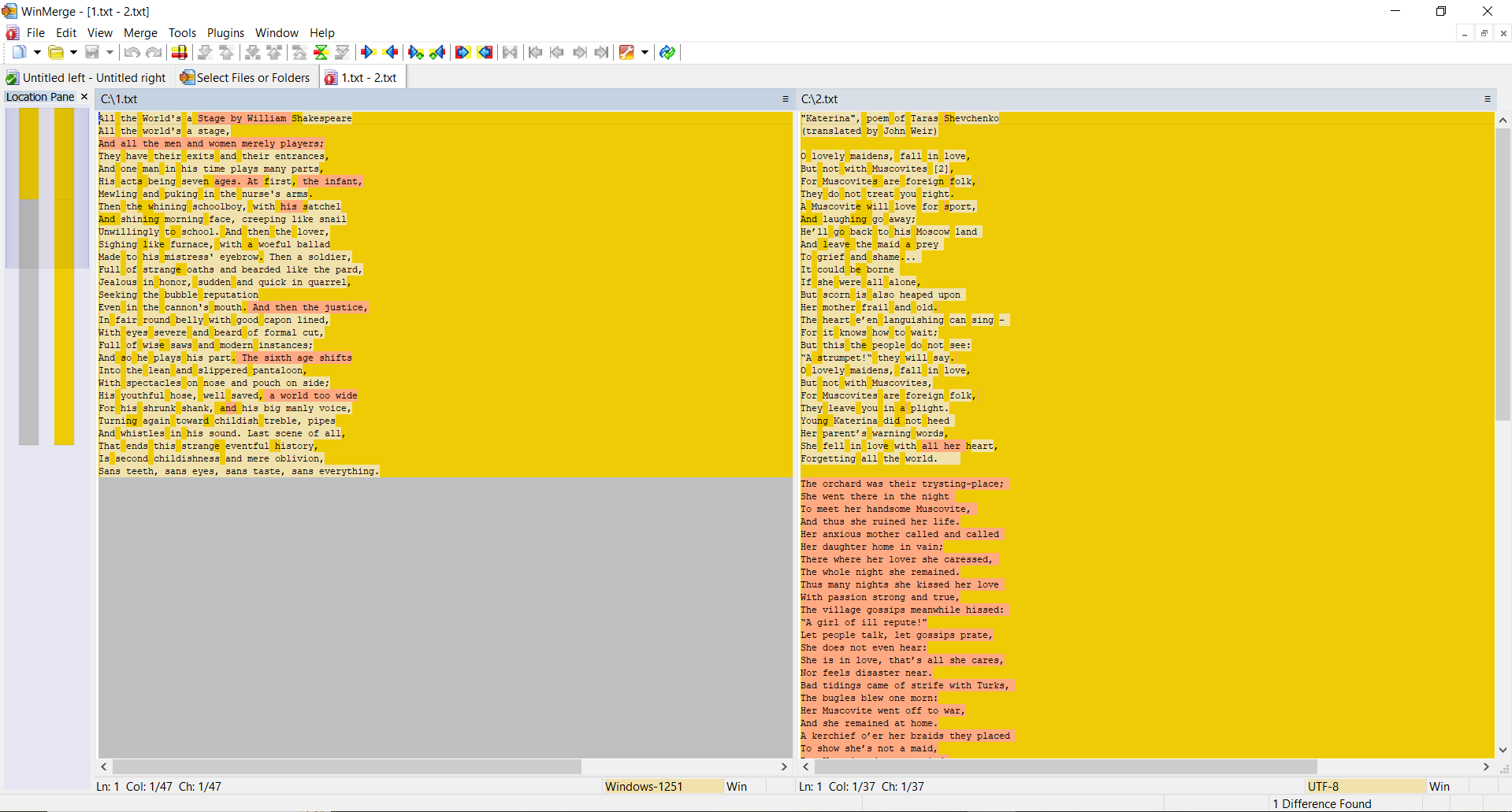
All the World`s a Stage by William Shakespeare
All the world`s a stage,
And all the men and women merely players;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first, the infant,
Mewling and puking in the nurse`s arms.
Then the whining schoolboy, with his satchel
And shining morning face, creeping like snail
Unwillingly to school. And then the lover,
Sighing like furnace, with a woeful ballad
Made to his mistress` eyebrow. Then a soldier,
Full of strange oaths and bearded like the pard,
Jealous in honor, sudden and quick in quarrel,
Seeking the bubble reputation
Even in the cannon`s mouth. And then the justice,
In fair round belly with good capon lined,
With eyes severe and beard of formal cut,
Full of wise saws and modern instances;
And so he plays his part. The sixth age shifts
Into the lean and slippered pantaloon,
With spectacles on nose and pouch on side;
His youthful hose, well saved, a world too wide
For his shrunk shank, and his big manly voice,
Turning again toward childish treble, pipes
And whistles in his sound. Last scene of all,
That ends this strange eventful history,
Is second childishness and mere oblivion,
Sans teeth, sans eyes, sans taste, sans everything.
TEST 1: skapa två identiska filer med samma innehåll (text ovan) och beräkna hashar.
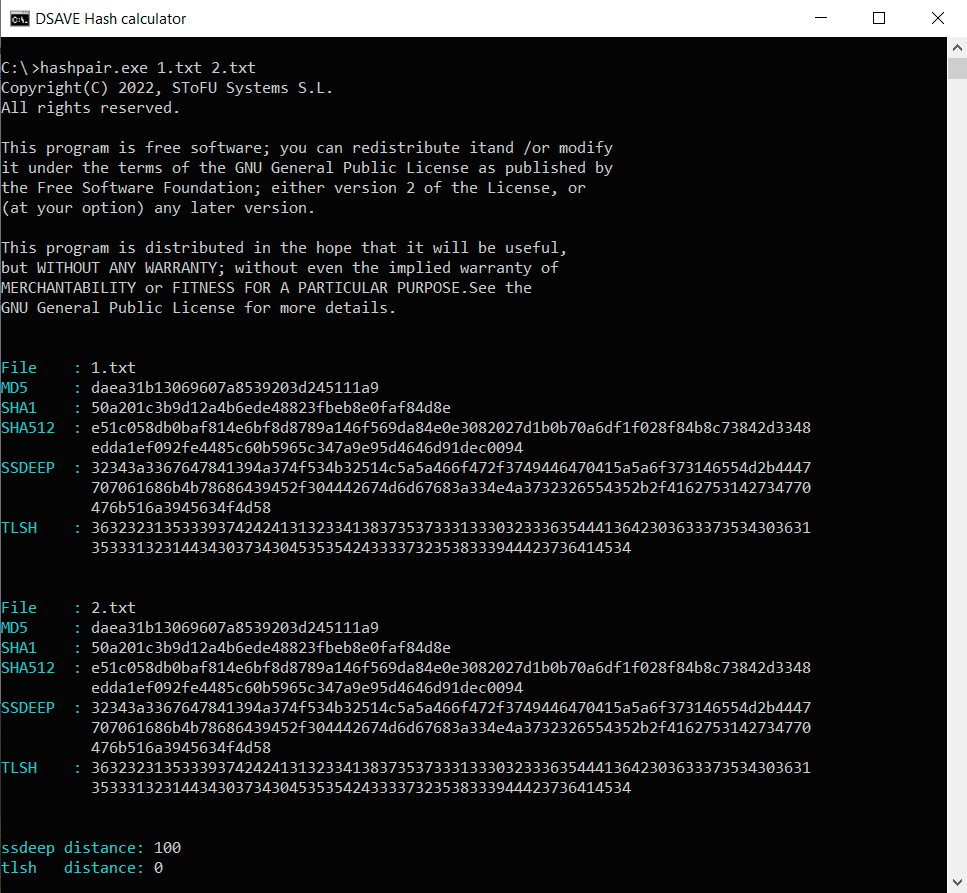
SSDEEP säger att filerna är 100% identiska. TLSH säger att det finns 0% skillnader mellan filerna.
TEST 2: Skapa två identiska filer med samma innehåll, gör ändringar i den andra filen och beräkna hashar
Innehåll i andra filen:
All the World`s a Stage by William Shakespeare
O lovely maidens, fall in love,
But not with Muscovites,
For Muscovites are foreign folk,
They do not treat you right.
A Muscovite will love for sport,
And laughing go away;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first, the infant,
Mewling and puking in the nurse`s arms.
Then the whining schoolboy, with his satchel
And shining morning face, creeping like snail
Unwillingly to school. And then the lover,
Sighing like furnace, with a woeful ballad
Made to his mistress` eyebrow. Then a soldier,
Full of strange oaths and bearded like the pard,
Jealous in honor, sudden and quick in quarrel,
Seeking the bubble reputation
Even in the cannon`s mouth. And then the justice,
In fair round belly with good capon lined,
With eyes severe and beard of formal cut,
Full of wise saws and modern instances;
And so he plays his part. The sixth age shifts
Into the lean and slippered pantaloon,
With spectacles on nose and pouch on side;
His youthful hose, well saved, a world too wide
For his shrunk shank, and his big manly voice,
Turning again toward childish treble, pipes
And whistles in his sound. Last scene of all,
That ends this strange eventful history,
Is second childishness and mere oblivion,
Sans teeth, sans eyes, sans taste, sans everything.
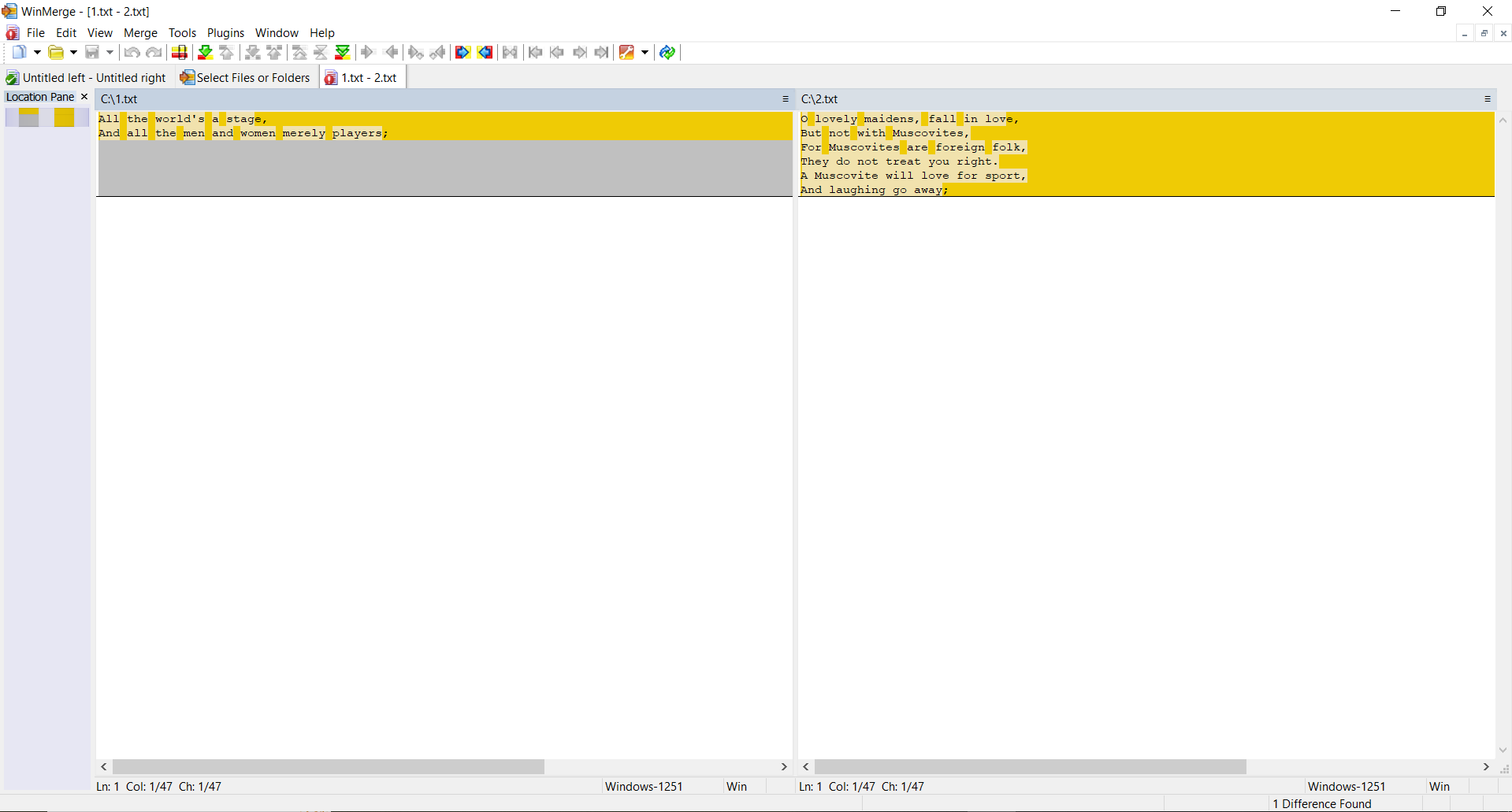
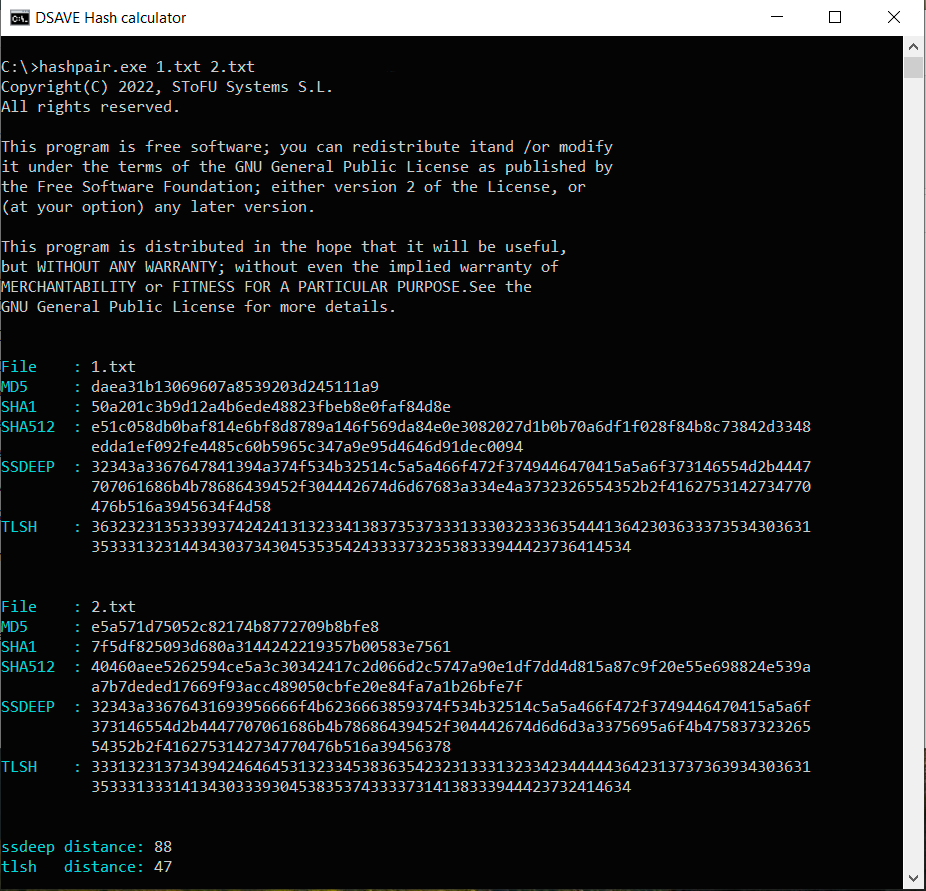
SSDEEP säger att filerna är 88% identiska. TLSH säger att det finns 4,7% skillnader mellan filerna.
TEST 3: beräkna hashar för två helt olika textfiler
Andra filinnehållet:
"Katerina", poem of Taras Shevchenko
(translated by John Weir)
O lovely maidens, fall in love,
But not with Muscovites [2],
For Muscovites are foreign folk,
They do not treat you right.
A Muscovite will love for sport,
And laughing go away;
He`ll go back to his Moscow land
And leave the maid a prey
To grief and shame...
It could be borne
If she were all alone,
But scorn is also heaped upon
Her mother frail and old.
The heart e`en languishing can sing –
For it knows how to wait;
But this the people do not see:
“A strumpet!“ they will say.
O lovely maidens, fall in love,
But not with Muscovites,
For Muscovites are foreign folk,
They leave you in a plight.
Young Katerina did not heed
Her parent`s warning words,
She fell in love with all her heart,
Forgetting all the world.
The orchard was their trysting-place;
She went there in the night
To meet her handsome Muscovite,
And thus she ruined her life.
Her anxious mother called and called
Her daughter home in vain;
There where her lover she caressed,
The whole night she remained.
Thus many nights she kissed her love
With passion strong and true,
The village gossips meanwhile hissed:
“A girl of ill repute!”
Let people talk, let gossips prate,
She does not even hear:
She is in love, that`s all she cares,
Nor feels disaster near.
Bad tidings came of strife with Turks,
The bugles blew one morn:
Her Muscovite went off to war,
And she remained at home.
A kerchief o`er her braids they placed
To show she`s not a maid,
But Katerina does not mind,
Her lover she awaits.
He promised her that he’d return
If he was left alive,
That he`d come back after the war –
And then she`d be his wife,
An army bride, a Muscovite
Herself, her ills forgot,
And if in meantime people prate,
Well, let the people talk!
She does not worry, not a bit –
The reason that she weeps
Is that the girls at sundown sing
Without her on the streets.
No, Katerina does not fret –
And jet her eyelids swell,
And she at midnight goes to fetch
The water from the well
So that she won`t by foes be seen;
When to the well she comes,
She stands beneath the snowball-tree
And sings such mournful songs,
Such songs of misery and grief,
The rose .itself must weep.
Then she comes home - content that she
By neighbours was not seen.
No, Katerina does not fret.
She`s carefree as can be -
With her new kerchief on her head
She looks out on the street.
So at the window day by day
Six months she sat in vain....
With sickness then was overcome,
Her body racked with pain.
Her illness very grievous proved.
She barely breathed for days ...
When it was over - by the stove
She rocked her tiny babe.
The gossips` tongues now got free rein.
The other mothers jibed
That soldiers marching home again
At her house spent the night.
“Oh, you have reared a daughter fair.
And not alone beside
The stove she sits - she`s drilling there
A little Muscovite.
She found herself a brown-eyed son...
You must have taught her how!...
Oh fie on ye, ye prattle tongues,
I hope yourselves you`ll feel
Someday such pains as she who bore
A son that you should jeer!
Oh, Katerina, my poor dear!
How cruel a fate is thine!
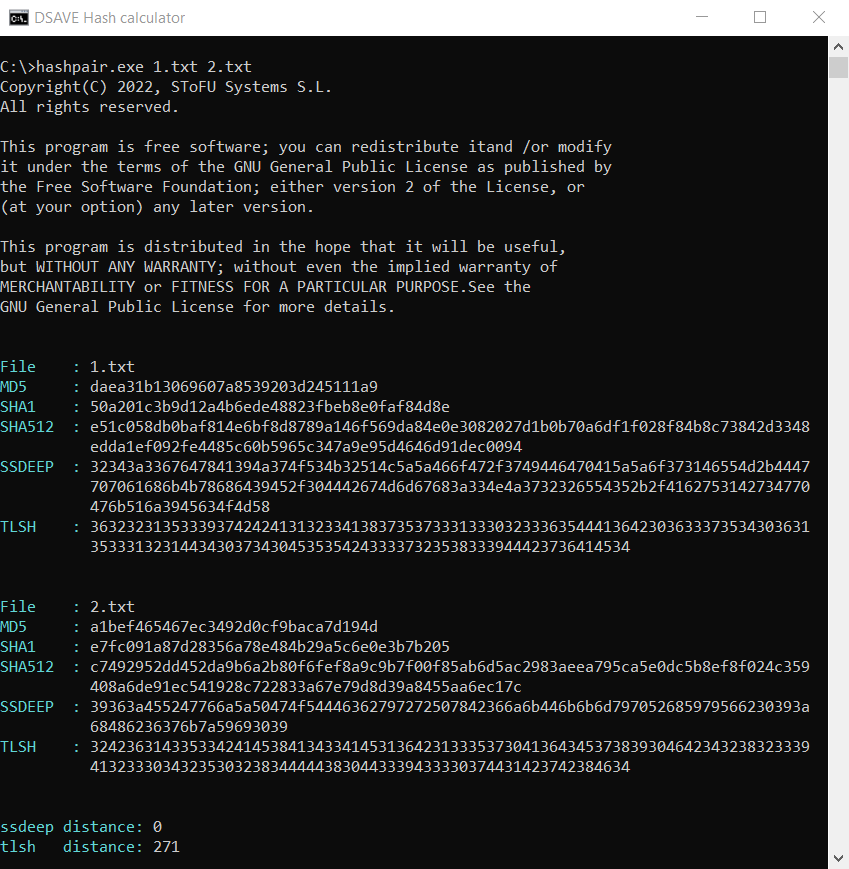
SSDEEP säger att filerna är helt olika, med 0% matchningar. Dock säger TLSH att filerna endast är 27,1% olika.
Varför är det så? Trots allt, vi betraktar avståndet mellan två helt olika textfiler, eller hur?
Det är så att, som vi nämnde ovan, TLSH-algoritmen tar hänsyn till frekvenser.
Trots att texterna är olika är de ändå skrivna på samma språk, använder samma alfabet och har ett antal samma ord. Denna egenskap hos denna hashningsalgoritm hjälper till att upptäcka ändringar av skadliga filer.
TEST 4: Jämför 2 Windows systemfiler
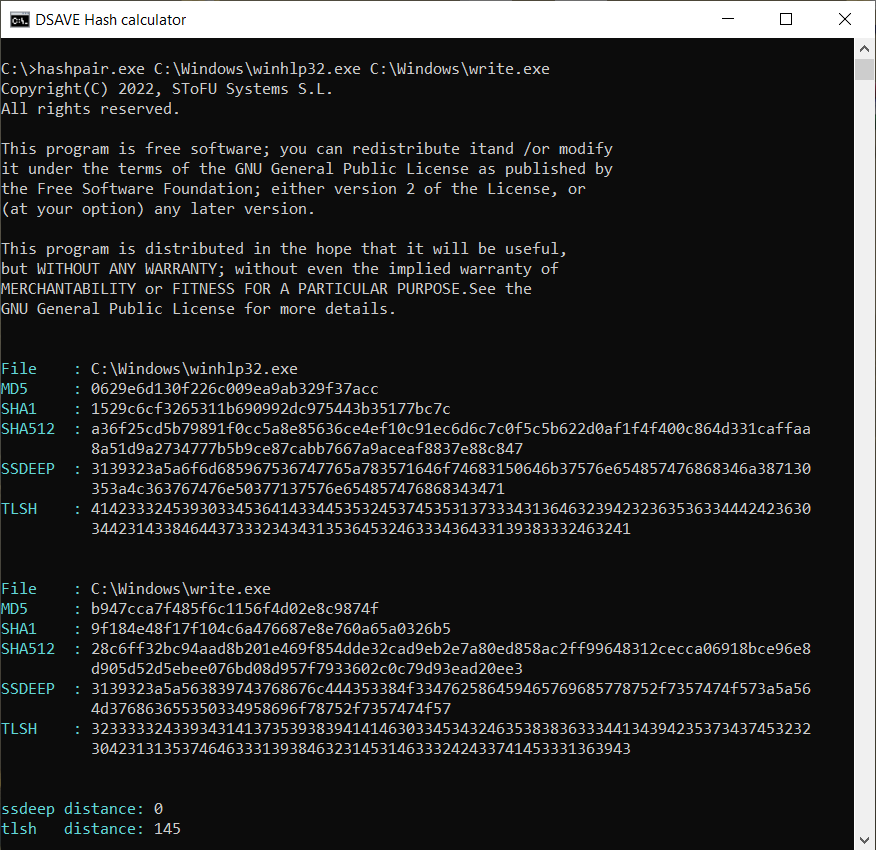
SSDEEP säger att filerna är helt olika, med 0% överensstämmelser.
Emellertid säger TLSH-algoritmen att filerna skiljer sig med endast 14,5%. Detta beror delvis på att filerna troligen byggdes av samma kompilator, av samma företag, möjligen med användning av samma kodmönster. Filerna har liknande VERSION_INFO och MZ-huvuden.
TEST 5: Jämför 2 systemfiler och vår hashpair.exe-fil
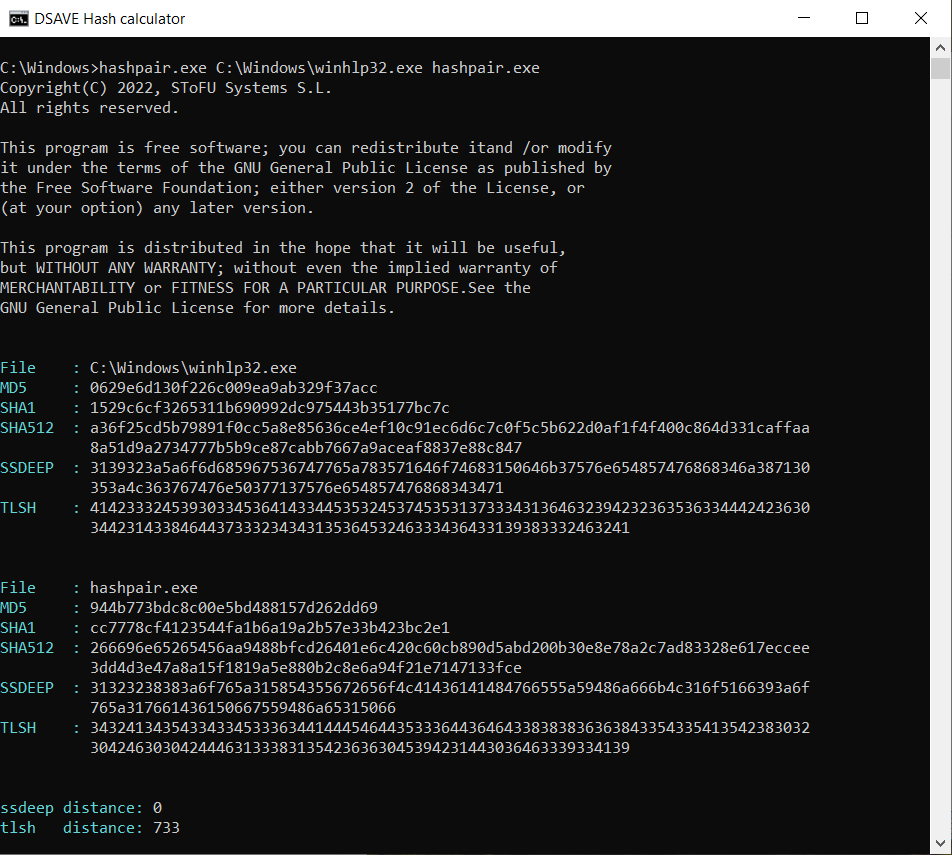
SSDEEP säger att filerna är helt olika, med 0% matchningar.
TLSH-algoritmen säger att filerna skiljer sig åt markant, med 73,3%. Dessa filer har kompilerats av olika företag, med användning av olika bibliotek och olika kompilatorer. Dessa filer har olika VERSION_INFO och olika MZ-huvuden. Sålunda tillåter TLSH-algoritmen dig att kategorisera körbara filer, vilket hjälper till att identifiera liknande skadliga filer eller skadliga filer från samma familj.
Lista över använda verktyg
1. WinMerge: https://winmerge.org
WinMerge är ett öppen källkods-verktyg för att jämföra och sammanfoga för Windows. WinMerge kan jämföra både mappar och filer, och presenterar skillnader i ett visuellt textformat som är lätt att förstå och hantera.
2. Notepad++: https://notepad-plus-plus.org/downloads
Notepad++ är en gratis (både i betydelsen "fri talan" och "gratis öl") källkodsredigerare och ersättning för Notepad som stödjer flera språk. Körs i MS Windows-miljön och dess användning regleras av GNU General Public License.
GITHUB
Du kan hitta koden för hela projektet på vår github:
https://github.com/SToFU-Systems/DSAVE
VAD ÄR NÄSTA?
Vi uppskattar ditt stöd och ser fram emot ditt fortsatta engagemang i vårt samhälle
I nästa artikel kommer vi tillsammans med dig att skriva den enklaste PE-resursparsaren.
Eventuella frågor till artikelförfattarna kan skickas till e-postadressen: articles@stofu.io
Tack för din uppmärksamhet och ha en trevlig dag!




