Det portabla utförbara (PE) formatet
Det första man bör börja med är PE-formatet. Kunskap och förståelse för detta format är en förutsättning för att utveckla antivirusmotorer för Windows-plattformen (historiskt sett är majoriteten av världens virus riktade mot Windows).
Det portabla exekverbara formatet (PE) är ett filformat som används av Windows-operativsystemet för att lagra exekverbara filer, såsom .EXE och .DLL filer. Det introducerades med lanseringen av Windows NT 1993, och har sedan dess blivit standardformatet för exekverbart innehåll på Windows-system.
Före införandet av PE-formatet använde Windows en mängd olika format för körbara filer, inklusive New Executable (NE) formatet för 16-bitarsprogram och Compact Executable (CE) formatet för 32-bitarsprogram. Dessa format hade sina egna unika uppsättningar av regler och konventioner, vilket gjorde det svårt för operativsystemet att pålitligt ladda och köra program.
För att standardisera layouten och strukturen för körbara filer introducerade Microsoft PE-formatet med lanseringen av Windows NT. PE-formatet designades för att vara ett gemensamt format för både 32-bitars och 64-bitars program.
En av de viktigaste funktionerna hos PE-formatet är dess användning av en standardiserad rubrik, som är placerad i början av filen och innehåller ett antal fält som ger operativsystemet viktig information om den körbara filen. Denna rubrik inkluderar strukturerna IMAGE_DOS_HEADER och IMAGE_NT_HEADER , som är uppdelade i två huvudsektioner: IMAGE_FILE_HEADER och IMAGE_OPTIONAL_HEADER.
De flesta av rubrikerna för PE-formatet deklareras i headerfilen WinNT.h
IMAGE_DOS_HEADER
Strukturen IMAGE_DOS_HEADER är en äldre rubrik som används för att stödja bakåtkompatibilitet med MS-DOS. Den används för att lagra information om filen som krävs av MS-DOS, såsom programmets kod- och dataplacering i filen, samt programmets startpunkt. Detta möjliggjorde att program som skrivits för MS-DOS kunde köras på Windows NT, förutsatt att de kompilerades som PE-filer.
typedef struct _IMAGE_DOS_HEADER
{
WORD e_magic;
WORD e_cblp;
WORD e_cp;
WORD e_crlc;
WORD e_cparhdr;
WORD e_minalloc;
WORD e_maxalloc;
WORD e_ss;
WORD e_sp;
WORD e_csum;
WORD e_ip;
WORD e_cs;
WORD e_lfarlc;
WORD e_ovno;
WORD e_res[4];
WORD e_oemid;
WORD e_oeminfo;
WORD e_res2[10];
DWORD e_lfanew; // offset of IMAGE_NT_HEADER
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
Det finns följande intressanta områden för oss:
-
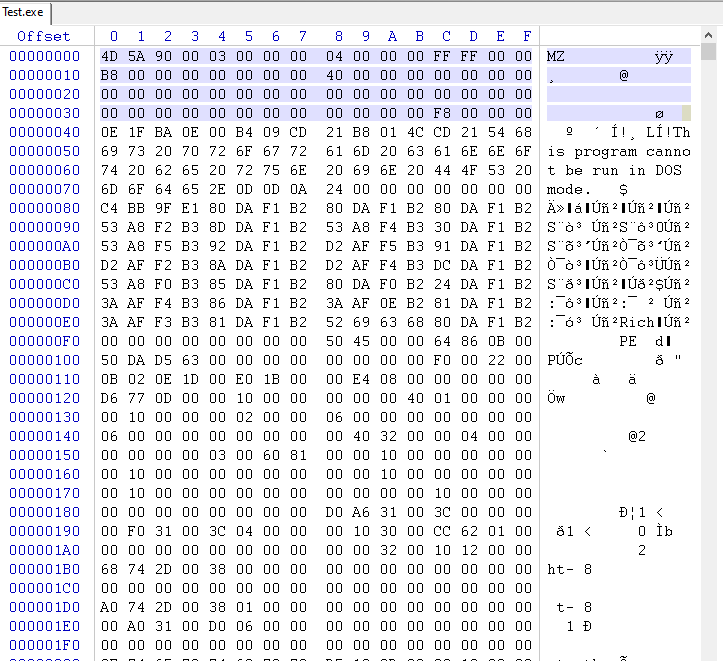
e_magic fältet används för att identifiera filen som en giltig PE-fil. Som du kan se är e_magic fältet ett 16-bitars osignerat heltal som anger filens "magiska nummer". Det magiska numret är ett speciellt värde som identifierar filen som en giltig PE-fil. Det är inställt på värdet 0x5A4D (hexadecimalt), vilket är ASCII-representationen av tecknen "MZ" (IMAGE_DOS_SIGNATURE).
-
e_lfanew fältet används för att ange platsen för IMAGE_NT_HEADERS strukturen, som innehåller information om layouten och egenskaperna för PE-filen. Som du kan se är e_lfanew fältet en 32-bitars signerad heltal som anger platsen för IMAGE_NT_HEADERS strukturen i filen. Det är vanligtvis inställt på strukturens förskjutning relativt till början av filen.
Historia
I början av 1980-talet arbetade Microsoft med ett nytt operativsystem som kallades MS-DOS, vilket var utformat för att vara ett enkelt, lättvikts operativsystem för persondatorer. En av de viktigaste egenskaperna hos MS-DOS var dess förmåga att köra exekverbara filer, vilka är program som kan köras på en dator.
För att göra det enkelt att identifiera körbara filer beslutade utvecklarna av MS-DOS att använda ett speciellt "magiskt nummer" i början av varje körbar fil. Detta magiska nummer skulle användas för att skilja körbara filer från andra typer av filer, såsom datafiler eller konfigurationsfiler.
Mark Zbikowski, som var utvecklare i MS-DOS-teamet, kom på idén att använda tecknen "MZ" som det magiska numret. I ASCII-koden representeras bokstaven "M" av det hexadecimala värdet 0x4D, och bokstaven "Z" representeras av det hexadecimala värdet 0x5A. När dessa värden kombineras bildar de det magiska numret 0x5A4D, vilket är ASCII-representationen av tecknen "MZ".
Idag används fortfarande "MZ"-signaturen för att identifiera PE-filer, som är det huvudsakliga körbara filformatet som används på Windows-operativsystemet. Det lagras i fältet e_magic i IMAGE_DOS_HEADER-strukturen, som är den första strukturen i en PE-fil.
IMAGE_NT_HEADER
IMAGE_NT_HEADER är en datastruktur som introducerades med operativsystemet Windows NT, som släpptes 1993. Den är utformad för att ge operativsystemet ett standardiserat sätt att läsa och tolka innehållet i exekverbara filer (PE-filer).
Med lanseringen av Windows NT introducerade Microsoft IMAGE_NT_HEADER som ett sätt att standardisera layouten och strukturen på körbara filer. Detta underlättade för operativsystemet att ladda och köra program, eftersom det endast behövde stödja ett enda format.
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_nt_headers32
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_nt_headers64
typedef struct _IMAGE_NT_HEADERS32
{
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
typedef struct _IMAGE_NT_HEADERS64
{
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER64 OptionalHeader;
} IMAGE_NT_HEADERS64, *PIMAGE_NT_HEADERS64;
IMAGE_NT_HEADER är en struktur som förekommer i början av varje portabelt exekverbart (PE) fil i Windows-operativsystemet. Den innehåller ett antal fält som ger operativsystemet viktig information om den exekverbara filen, såsom dess storlek, layout och avsedda syfte.
Strukturen IMAGE_NT_HEADER är indelad i två huvuddelar: IMAGE_FILE_HEADER och IMAGE_OPTIONAL_HEADER.

IMAGE_FILE_HEADER
IMAGE_FILE_HEADER innehåller information om den körbara filen som helhet, inklusive dess maskintyp (t.ex. x86, x64), antalet sektioner i filen och datum och tid då filen skapades.
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_file_header
typedef struct _IMAGE_FILE_HEADER
{
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
Strukturen har följande fält:
-
Machine: Detta fält specificerar målarkitekturen för vilken filen har byggts. Värdet på detta fält bestäms av kompilatorn när filen byggs. Några vanliga värden är:
-
IMAGE_FILE_MACHINE_I386: Filen är avsedd att köras på x86-arkitektur, även känd som 32-bitars.
-
IMAGE_FILE_MACHINE_AMD64: Filen är avsedd att köras på x64-arkitektur, även känd som 64-bitars.
-
IMAGE_FILE_MACHINE_ARM: Filen är avsedd att köras på ARM-arkitektur.
-
-
NumberOfSections: Detta fält specificerar antalet sektioner i PE-filen. En PE-fil är indelad i flera sektioner, var och en innehåller olika typer av information såsom kod, data och resurser. Detta fält används av operativsystemet för att avgöra hur många sektioner som finns i filen.
-
TimeDateStamp: Detta fält innehåller tidsstämpeln för när filen byggdes. Tidsstämpeln lagras som ett 4-byte värde som representerar antalet sekunder sedan den 1 januari 1970, 00:00:00 UTC. Detta fält kan användas för att bestämma när filen senast byggdes, vilket kan vara användbart för felsökning eller versionshantering.
-
PointerToSymbolTable: Detta fält specificerar filoffseten för COFF (Common Object File Format) symboltabellen, om den finns. COFF-symboltabellen innehåller information om symboler som används i filen, såsom funktionsnamn, variabelnamn och radnummer. Detta fält används endast för felsökningsändamål och är vanligtvis inte närvarande i slutliga byggen.
-
NumberOfSymbols: Detta fält specificerar antalet symboler i COFF-symboltabellen, om den finns. Detta fält används tillsammans med PointerToSymbolTable för att lokalisera COFF-symboltabellen i filen.
-
SizeOfOptionalHeader: Detta fält specificerar storleken på den valfria headern, som innehåller ytterligare information om filen. Den valfria headern inkluderar vanligtvis information om filens startpunkt, de importerade biblioteken samt storleken på stacken och heapen.
-
Characteristics: Detta fält specificerar olika attribut för filen. Några vanliga värden är:
-
IMAGE_FILE_EXECUTABLE_IMAGE: Filen är en exekverbar fil.
-
IMAGE_FILE_DLL: Filen är ett dynamiskt länkbibliotek (DLL).
-
IMAGE_FILE_32BIT_MACHINE: Filen är en 32-bitars fil.
-
IMAGE_FILE_DEBUG_STRIPPED: Filen har avlägsnats från felsökningsinformation.
-
Dessa fält tillhandahåller viktig information om filen som används av operativsystemet när filen laddas in i minnet och körs. Genom att förstå fälten i IMAGE_FILE_HEADER strukturen, kan du få en djupare förståelse för hur PE-filer är strukturerade och hur operativsystemet använder dem.
De flesta av de möjliga värdena för varje fält deklareras i header-filen WinNT.h
IMAGE_OPTIONAL_HEADER
Strukturen IMAGE_FILE_HEADER följs av den valfria headern, vilken beskrivs av strukturen IMAGE_OPTIONAL_HEADER . Den valfria headern innehåller ytterligare information om bilden, såsom adressen till startpunkten, bildens storlek och adressen till importkatalogen.
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_optional_header32
https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_optional_header64
typedef struct _IMAGE_OPTIONAL_HEADER32
{
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
typedef struct _IMAGE_OPTIONAL_HEADER64
{
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
ULONGLONG ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
ULONGLONG SizeOfStackReserve;
ULONGLONG SizeOfStackCommit;
ULONGLONG SizeOfHeapReserve;
ULONGLONG SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER64, *PIMAGE_OPTIONAL_HEADER64;
Här är en detaljerad beskrivning av varje fält i IMAGE_OPTIONAL_HEADER strukturen:
-
Magic: Detta fält anger vilken typ av valfri rubrik som finns i PE-filen. Det vanligaste värdet är IMAGE_NT_OPTIONAL_HDR32_MAGIC för en 32-bitarsfil eller IMAGE_NT_OPTIONAL_HDR64_MAGIC för en 64-bitarsfil.
-
MajorLinkerVersion och MinorLinkerVersion: Dessa fält anger versionen av länkaren som användes för att bygga filen. Länkaren är ett verktyg som används för att kombinera objektfiler och bibliotek till en enda exekverbar fil.
-
SizeOfCode: Detta fält anger storleken på kodsektionen i filen. Kodsektionen innehåller maskinkod för den exekverbara filen.
-
SizeOfInitializedData: Detta fält anger storleken på den initierade datasektionen i filen. Den initierade datasektionen innehåller data som initieras vid körning, såsom globala variabler.
-
SizeOfUninitializedData: Detta fält anger storleken på den oinitierade datasektionen i filen. Den oinitierade datasektionen innehåller data som inte initieras vid körning, såsom bss-sektionen.
-
AddressOfEntryPoint: Detta fält anger den virtuella adressen för programmets startpunkt i filen. Ingångspunkten är startadressen för programmet och är den första instruktionen som utförs när filen laddas in i minnet.
-
BaseOfCode: Detta fält anger den virtuella adressen för starten av kodsektionen.
-
ImageBase: Detta fält anger den föredragna virtuella adressen där filen bör laddas in i minnet. Denna adress används som basadress för alla virtuella adresser inom filen.
-
SectionAlignment: Detta fält anger inpassningen av sektioner inom filen. Sektionerna i filen är vanligtvis anpassade i multipler av detta värde för att förbättra prestanda.
-
FileAlignment: Detta fält anger inpassningen av sektioner inom filen på disken. Sektionerna i filen är vanligtvis anpassade i multipler av detta värde för att förbättra diskprestanda.
-
MajorOperatingSystemVersion och MinorOperatingSystemVersion: Dessa fält anger den lägsta nödvändiga versionen av operativsystemet som behövs för att köra filen.
-
MajorImageVersion och MinorImageVersion: Dessa fält anger versionen av bilden. Bildversionen används för att identifiera versionen av filen för versionshantering.
-
MajorSubsystemVersion och MinorSubsystemVersion: Dessa fält anger versionen av subsystemet som krävs för att köra filen. Subsystemet är miljön där filen körs, såsom Windows Console eller Windows GUI.
-
Win32VersionValue: Detta fält är reserverat och ställs vanligtvis in på 0.
-
SizeOfImage: Detta fält anger storleken på bilden, i byte, när den laddas in i minnet.
-
SizeOfHeaders: Detta fält anger storleken på rubrikerna, i byte. Rubrikerna inkluderar IMAGE_FILE_HEADER och IMAGE_OPTIONAL_HEADER.
-
CheckSum: Detta fält används för att kontrollera filens integritet. Kontrollsumman beräknas genom att summera filens innehåll och lagra resultatet i detta fält. Kontrollsumman används för att upptäcka förändringar i filen som kan bero på manipulering eller korruption.
-
Subsystem: Detta fält anger det subsystem som krävs för att köra filen. Möjliga värden inkluderar IMAGE_SUBSYSTEM_NATIVE, IMAGE_SUBSYSTEM_WINDOWS_GUI, IMAGE_SUBSYSTEM_WINDOWS_CUI, IMAGE_SUBSYSTEM_OS2_CUI, etc.
-
DllCharacteristics: Detta fält anger egenskaper för filen, såsom om den är ett dynamiskt länkbibliotek (DLL) eller om den kan omlokaliseras vid laddningstid. Möjliga värden inkluderar IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASE, IMAGE_DLLCHARACTERISTICS_NX_COMPAT, etc.
-
SizeOfStackReserve: Detta fält anger storleken på stacken, i byte, som är reserverad för programmet. Stacken används för att lagra tillfälliga data, såsom funktionsanropsinformation.
-
SizeOfStackCommit: Detta fält anger storleken på stacken, i byte, som är åtagen för programmet. Den åtagande stacken är den del av stacken som faktiskt är reserverad i minnet.
-
SizeOfHeapReserve: Detta fält anger storleken på högen, i byte, som är reserverad för programmet. Högen används för att dynamiskt allokera minne vid körning.
-
SizeOfHeapCommit: Detta fält anger storleken på högen, i byte, som är åtagen för programmet. Den åtagande högen är den del av högen som faktiskt är reserverad i minnet.
-
LoaderFlags: Detta fält är reserverat och ställs vanligtvis in på 0.
-
NumberOfRvaAndSizes: Detta fält anger antalet datakatalogposter i IMAGE_OPTIONAL_HEADER. Datakatalogerna innehåller information om import, export, resurser, etc. i filen.
-
DataDirectory: Detta fält är en array av IMAGE_DATA_DIRECTORY-strukturer som anger placering och storlek på datakatalogerna i filen.
IMAGE_SECTION_HEADER
En sektion, i sammanhanget av en PE (Portable Executable) fil, är ett sammanhängande minnesblock i filen som innehåller en specifik typ av data eller kod. I en PE-fil används sektioner för att organisera och lagra olika delar av filen, såsom kod, data, resurser, etc.
Varje avsnitt i en PE-fil har ett unikt namn och beskrivs av en IMAGE_SECTION_HEADER struktur, som innehåller information om avsnittet såsom dess storlek, placering, egenskaper, och så vidare. Följande är fälten i IMAGE_SECTION_HEADER:
En IMAGE_SECTION_HEADER är en datastruktur som används i det portabla exekverbara (PE) filformatet, vilket används på Windows-operativsystemet för att definiera layouten av en fil i minnet. PE-filformatet används för exekverbara filer, DLL-filer och andra typer av filer som laddas in i minnet av Windows-operativsystemet. Varje sektionshuvud beskriver ett sammanhängande data block inom filen och inkluderar information som sektionens namn, den virtuella minnesadressen där sektionen ska laddas och sektionens storlek. Sektionshuvudena kan användas för att lokalisera och få tillgång till specifika delar av filen, såsom kod- eller datasektionerna.
IMAGE_SECTION_HEADER-strukturen är definierad i Windows Platform SDK och kan hittas i winnt.h-huvudfilen. Här är ett exempel på hur strukturen är definierad i C++:
#pragma pack(push, 1)
typedef struct _IMAGE_SECTION_HEADER
{
BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; // 8
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
#pragma pack(pop)
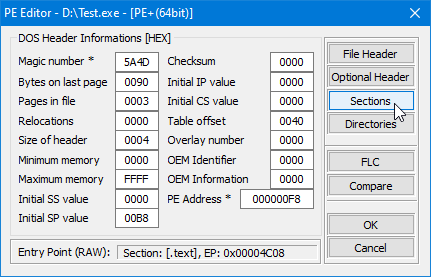
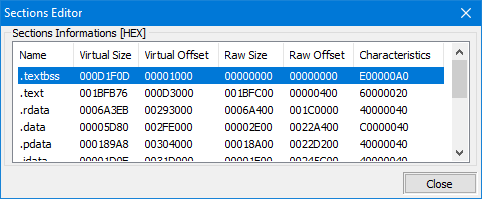
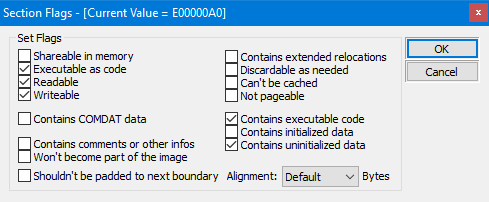
Som du kan se är strukturen definierad som en C++ struct och den innehåller fält för sektionens namn, virtuell storlek, virtuell adress, storlek på rådata och pekare till rådata, omlokaliseringar, radnummer och antalet omlokaliseringar och radnummer. Dessutom innehåller fältet Characteristics flaggor som beskriver sektionens egenskaper, såsom om den är exekverbar, läsbar eller skrivbar.
-
Name: Denna 8-byte array används för att ange namnet på sektionen. Namnet kan vara vilken null-terminerad sträng som helst, men det används vanligtvis för att ge meningsfulla namn till olika delar av filen, såsom ".text" för exekverbar kod, ".data" för initierad data, ".rdata" för skrivskyddad data och ".bss" för oinitierad data. Sektionens namn används av operativsystemet för att lokalisera sektionen inom filen, och används även av felsökare och andra verktyg för att identifiera sektionen och dess innehåll.
-
VirtualSize: Det här fältet anger sektionens storlek i minnet, i byte. Detta värde representerar den mängd minne som sektionen kommer att uppta i minnet när filen laddas in i minnet. Den virtuella storleken på sektionen används av operativsystemet för att bestämma hur mycket minne som behöver allokeras för sektionen när filen laddas in i minnet.
-
VirtualAddress: Det här fältet anger startadressen för sektionen i minnet, i byte. Detta värde är startadressen där sektionen kommer att laddas in i minnet och används av operativsystemet för att bestämma platsen i minnet där sektionen kommer att laddas. Den virtuella adressen för sektionen används också av operativsystemet för att lösa adresser inom sektionen, så att de kan översättas korrekt till minnesadresser när filen laddas in i minnet.
-
SizeOfRawData: Det här fältet anger sektionens storlek i filen, i byte. Detta värde representerar den mängd utrymme i filen som sektionen kommer att uppta, och används av operativsystemet för att bestämma sektionens storlek i filen. Storleken på rådatan för en sektion används av operativsystemet för att lokalisera sektionen inom filen och för att bestämma storleken på sektionen när den laddas in i minnet.
-
PointerToRawData: Det här fältet anger offsetten för sektionen i filen, i byte. Detta värde representerar sektionens plats inom filen och används för att bestämma var datan för sektionen kan hittas. Pekaren till rådatan för en sektion används av operativsystemet för att lokalisera sektionen inom filen och för att bestämma sektionens placering när den laddas in i minnet.
-
PointerToRelocations: Det här fältet anger offsetten för omlokaliseringinformationen för sektionen, i byte. Omlokaliseringinformationen används för att justera adresser inom sektionen, så att de kan lösas korrekt när filen laddas in i minnet. Pekaren till omlokaliseringarna för en sektion används av operativsystemet för att lokalisera omlokaliseringinformationen för sektionen och för att bestämma hur adresserna inom sektionen ska justeras när filen laddas in i minnet.
-
PointerToLinenumbers: Det här fältet anger offsetten för radnummerinformationen för sektionen, i byte. Radnummerinformationen används för felsökningsändamål och ger information om källkoden som genererade sektionen. Pekaren till radnumren för en sektion används av felsökare och andra verktyg för att identifiera källkoden som genererade sektionen och för att ge mer detaljerad information om innehållet i sektionen.
-
NumberOfRelocations: Det här fältet anger antalet omlokaliseringar för sektionen. En omlokalisering är en post som beskriver hur en adress inom sektionen ska justeras så att den kan lösas korrekt när filen laddas in i minnet. Antalet omlokaliseringar för en sektion används av operativsystemet för att bestämma storleken på omlokaliseringinformationen för sektionen och för att veta hur många omlokaliseringar som behöver bearbetas när filen laddas in i minnet.
-
NumberOfLinenumbers: Det här fältet anger antalet radnummerposter för sektionen. En radnummerpost är en post som ger information om källkoden som genererade sektionen och används för felsökningsändamål. Antalet radnummer för en sektion används av felsökare och andra verktyg för att bestämma storleken på radnummerinformationen för sektionen och för att veta hur många radnummerposter som behöver bearbetas för att få information om källkoden som genererade sektionen.
-
Characteristics: Det här fältet är en uppsättning flaggor som anger avsnittets attribut. Några vanliga flaggor som används för sektioner är: IMAGE_SCN_CNT_CODE för att ange att sektionen innehåller exekverbar kod, IMAGE_SCN_CNT_INITIALIZED_DATA för att ange att sektionen innehåller initierad data, IMAGE_SCN_CNT_UNINITIALIZED_DATA för att ange att sektionen innehåller oinitierad data, IMAGE_SCN_MEM_EXECUTE för att ange att sektionen kan exekveras, IMAGE_SCN_MEM_READ för att ange att sektionen kan läsas, och IMAGE_SCN_MEM_WRITE för att ange att sektionen kan skrivas till. Dessa flaggor används av operativsystemet för att bestämma egenskaperna hos sektionen och för att veta hur sektionen ska hanteras när filen laddas in i minnet.
Dessa fält används av operativsystemet och andra program för att hantera filens minneslayout och för att lokalisera och komma åt specifika delar av filen, såsom kod- eller datasektionerna.
VIKTIGT: I sammanhanget av IMAGE_NT_HEADER-strukturen, som används i det portabla exekverbara (PE) filformatet, refererar fälten VirtualAddress och PhysicalAddress till olika saker.
Fältet VirtualAddress används för att specificera den virtuella adressen där sektionen som innehåller IMAGE_NT_HEADER strukturen laddas in i minnet vid körning. Denna adress är relativ till processens basadress och används av programmet för att komma åt sektionens data.
Fältet PhysicalAddress används för att specificera filoffseten för sektionen som innehåller IMAGE_NT_HEADER -strukturen i PE-filen. Det används av operativsystemet för att lokalisera sektionens data i filen när den laddas in i minnet.
Alla rubrikfält och förskjutningar för IMAGE_NT_HEADER är definierade för minnet och fungerar på virtuella adresser. Om du behöver förskjuta något fält på disken behöver du konvertera den virtuella adressen till en fysisk adress med hjälp av funktionen rva2offset i koden nedan.
Sammanfattningsvis används VirtualAddress av programmet för att komma åt avsnittet i minnet och PhysicalAddress används av operativsystemet för att lokalisera avsnittet i filen.

IMPORT
När ett program kompileras genererar kompilatorn objektfiler som innehåller maskinkod för programmets funktioner. Objektfilerna kanske dock inte har all information som krävs för att programmet ska kunna köras. Till exempel kan objektfilerna innehålla anrop till funktioner som inte är definierade i programmet utan istället tillhandahålls av externa bibliotek.
Det här är där importtabellen kommer in. Importtabellen listar de externa beroendena för programmet och de funktioner som programmet behöver importera från dessa beroenden. Den dynamiska länkaren använder denna information vid körning för att lösa adresserna till de importerade funktionerna och länka dem till programmet.
Till exempel, tänk på ett program som använder funktioner från Windows operativsystem. Programmet kan innehålla anrop till funktionen MessageBox från biblioteket user32.dll, som visar en meddelanderuta på skärmen. För att lösa adressen till funktionen MessageBox måste programmet inkludera en import för user32.dll i sin importtabell.
På samma sätt, om ett program behöver använda funktioner från ett tredjepartsbibliotek, måste det inkludera en import för det biblioteket i sin importtabell. Till exempel skulle ett program som använder funktionerna från OpenSSL-biblioteket inkludera en import för libssl.dll i sin importtabell.
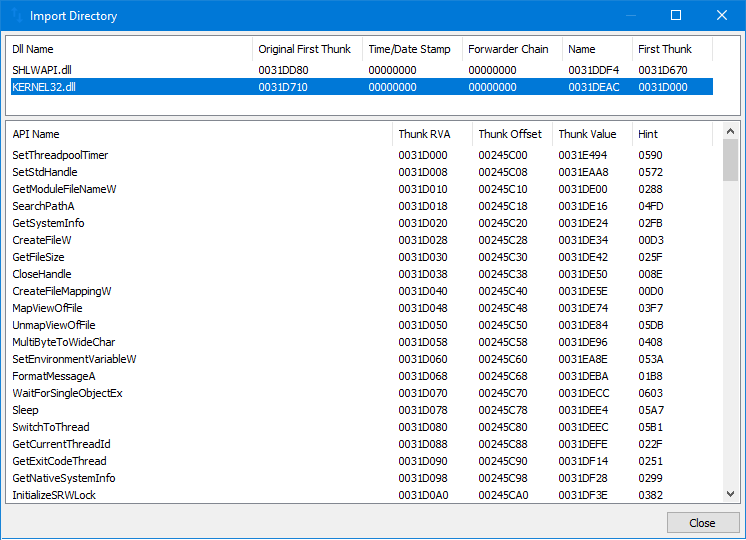
IMAGE_IMPORT_DIRECTORY
IMAGE_IMPORT_DIRECTORY är en datastruktur som används av Windows-operativsystemet för att importera funktioner och data från dynamiskt länkade bibliotek (DLLs) till en portabelt utförbar (PE) fil. Den är en del av IMAGE_DATA_DIRECTORY, vilket är en tabell med datastrukturer som lagras i IMAGE_OPTIONAL_HEADER av en PE-fil.
IMAGE_IMPORT_DIRECTORY används av Windows-laddaren för att lösa de importerade funktionerna och data som används av PE-filen. Detta görs genom att mappa adresserna för de importerade funktionerna och datan till adresserna för motsvarande funktioner och data i DLL:erna. Detta gör att PE-filen kan använda funktionerna och datan från DLL:erna som om de vore en del av själva PE-filen.
IMAGE_IMPORT_DIRECTORY består av en serie IMAGE_IMPORT_DESCRIPTOR strukturer, var och en beskriver en enskild DLL som importeras av PE-filen. Varje IMAGE_IMPORT_DESCRIPTOR struktur innehåller följande fält:
-
OriginalFirstThunk: en pekare till en tabell med importerade funktioner.
-
TimeDateStamp: datumet och tiden då DLL senast uppdaterades.
-
ForwarderChain: en kedja av vidarebefordrade importerade funktioner.
-
Name: namnet på DLL som en null-terminerad sträng.
-
FirstThunk: en pekare till en tabell med importerade funktioner som är bundna till DLL.
typedef struct _IMAGE_IMPORT_DESCRIPTOR
{
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date ime stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name;
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;
OriginalFirstThunk tabellen (eller FirstThunk om OriginalFirstThunk är 0)
Strängar pekade på av tabellen med förskjutningar (OriginalFirstThunk-tabellen eller FirstThunk om OriginalFirstThunk är 0)

HUR FUNGERAR DET?
Importmekanismen som implementerats av Microsoft är kompakt och vacker!
Adresserna till alla funktioner från tredjepartsbibliotek (inklusive Windows systembibliotek) som applikationen använder lagras i en speciell tabell - importtabellen. Denna tabell fylls i när modulen laddas (om andra mekanismer för att fylla i import kommer vi att prata senare).
Ytterligare, varje gång en funktion anropas från ett externt bibliotek, genererar kompilatorn vanligtvis följande kod:
call dword ptr [__cell_with_address_of_function] // for x86 architecture
call qword ptr [__cell_with_address_of_function] // for x64 architecture
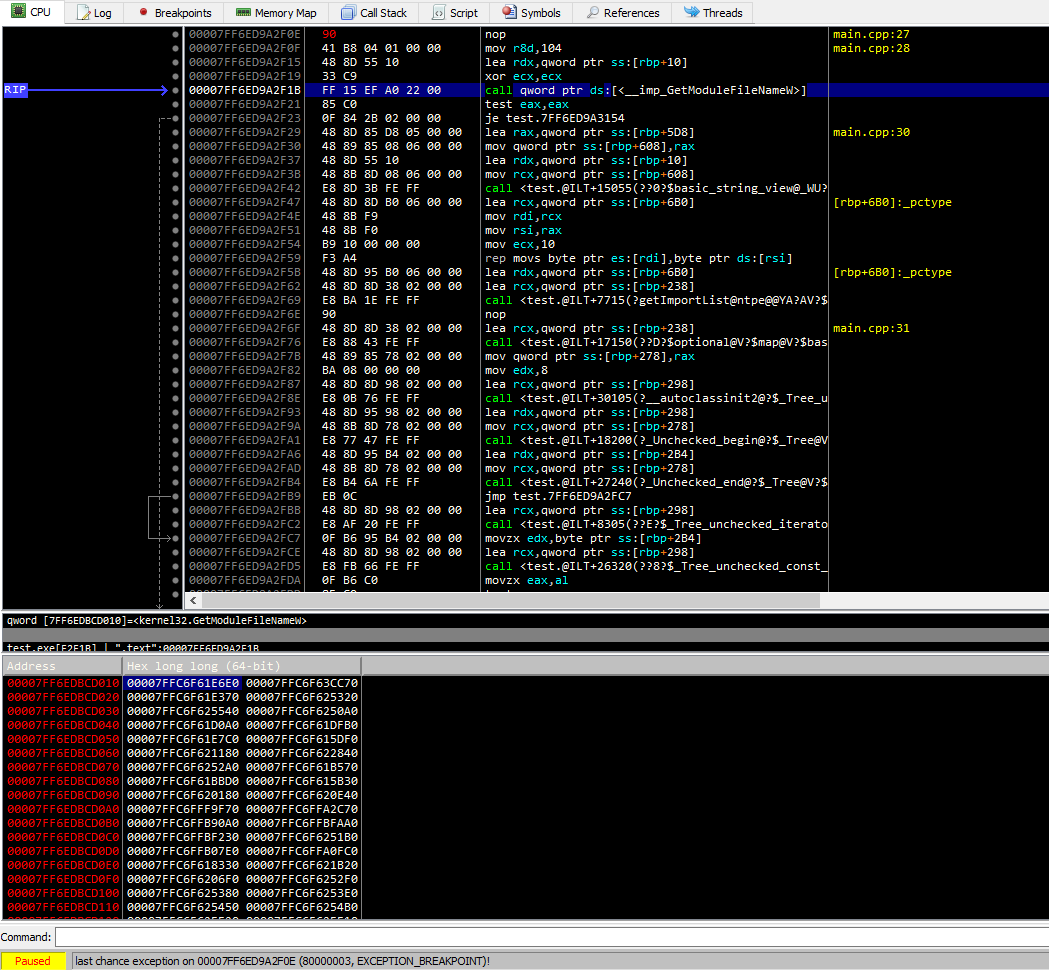
Således, för att kunna anropa en funktion från ett bibliotek, behöver systemladdaren endast skriva adressen till denna funktion en gång på ett ställe i bilden.
C++ PARSER
Och nu ska vi skriva den enklaste parsern (kompatibel med x86 och x64) för importtabellen i den körbara filen!
#include "stdafx.h"
/*
*
* Copyright (C) 2022, SToFU Systems S.L.
* All rights reserved.
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation; either version 2 of the License, or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License along
* with this program; if not, write to the Free Software Foundation, Inc.,
* 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
*
*/
namespace ntpe
{
static constexpr uint64_t g_kRvaError = -1;
// These types is defined in NTPEParser.h
// typedef std::map< std::string, std::set< std::string >> IMPORT_LIST;
// typedef std::vector< IMAGE_SECTION_HEADER > SECTIONS_LIST;
//**********************************************************************************
// FUNCTION: alignUp(DWORD value, DWORD align)
//
// ARGS:
// DWORD value - value to align.
// DWORD align - alignment.
//
// DESCRIPTION:
// Aligns argument value with the given alignment.
//
// Documentation links:
// Alignment: https://learn.microsoft.com/en-us/cpp/cpp/alignment-cpp-declarations?view=msvc-170
//
// RETURN VALUE:
// DWORD aligned value.
//
//**********************************************************************************
DWORD alignUp(DWORD value, DWORD align)
{
DWORD mod = value % align;
return value + (mod ? (align - mod) : 0);
};
//**********************************************************************************
// FUNCTION: rva2offset(IMAGE_NTPE_DATA& ntpe, DWORD rva)
//
// ARGS:
// IMAGE_NTPE_DATA& ntpe - data from PE file.
// DWORD rva - relative virtual address.
//
// DESCRIPTION:
// Parse RVA (relative virtual address) to offset.
//
// RETURN VALUE:
// int64_t offset.
// g_kRvaError (-1) in case of error.
//
//**********************************************************************************
int64_t rva2offset(IMAGE_NTPE_DATA& ntpe, DWORD rva)
{
/* retrieve first section */
try
{
/* if rva is inside MZ header */
PIMAGE_SECTION_HEADER sec = ntpe.sectionDirectories;
if (!ntpe.fileHeader->NumberOfSections || rva < sec->VirtualAddress)
return rva;
/* walk on sections */
for (uint32_t sectionIndex = 0; sectionIndex < ntpe.fileHeader->NumberOfSections; sectionIndex++, sec++)
{
/* count section end and allign it after each iteration */
DWORD secEnd = ntpe::alignUp(sec->Misc.VirtualSize, ntpe.SecAlign) + sec->VirtualAddress;
if (sec->VirtualAddress <= rva && secEnd > rva)
return rva - sec->VirtualAddress + sec->PointerToRawData;
};
}
catch (std::exception&)
{
}
return g_kRvaError;
};
//**********************************************************************************
// FUNCTION: getNTPEData(char* fileMapBase)
//
// ARGS:
// char* fileMapBase - the starting address of the mapped file.
//
// DESCRIPTION:
// Parses following data from mapped PE file.
//
// Documentation links:
// PE format structure: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format
//
// RETURN VALUE:
// std::optional< IMAGE_NTPE_DATA >.
// std::nullopt in case of error.
//
//**********************************************************************************
#define initNTPE(HeaderType, cellSize) \
{ \
char* ntstdHeader = (char*)fileHeader + sizeof(IMAGE_FILE_HEADER); \
HeaderType* optHeader = (HeaderType*)ntstdHeader; \
data.sectionDirectories = (PIMAGE_SECTION_HEADER)(ntstdHeader + sizeof(HeaderType)); \
data.SecAlign = optHeader->SectionAlignment; \
data.dataDirectories = optHeader->DataDirectory; \
data.CellSize = cellSize; \
}
std::optional< IMAGE_NTPE_DATA > getNTPEData(char* fileMapBase, uint64_t fileSize)
{
try
{
/* PIMAGE_DOS_HEADER from starting address of the mapped view*/
PIMAGE_DOS_HEADER dosHeader = (IMAGE_DOS_HEADER*)fileMapBase;
/* return std::nullopt in case of no IMAGE_DOS_SIGNATUR signature */
if (dosHeader->e_magic != IMAGE_DOS_SIGNATURE)
return std::nullopt;
/* PE signature adress from base address + offset of the PE header relative to the beginning of the file */
PDWORD peSignature = (PDWORD)(fileMapBase + dosHeader->e_lfanew);
if ((char*)peSignature <= fileMapBase || (char*)peSignature - fileMapBase >= fileSize)
return std::nullopt;
/* return std::nullopt in case of no PE signature */
if (*peSignature != IMAGE_NT_SIGNATURE)
return std::nullopt;
/* file header address from PE signature address */
PIMAGE_FILE_HEADER fileHeader = (PIMAGE_FILE_HEADER)(peSignature + 1);
if (fileHeader->Machine != IMAGE_FILE_MACHINE_I386 &&
fileHeader->Machine != IMAGE_FILE_MACHINE_AMD64)
return std::nullopt;
/* result IMAGE_NTPE_DATA structure with info from PE file */
IMAGE_NTPE_DATA data = {};
/* base address and File header address assignment */
data.fileBase = fileMapBase;
data.fileHeader = fileHeader;
/* addresses of PIMAGE_SECTION_HEADER, PIMAGE_DATA_DIRECTORIES, SectionAlignment, CellSize depending on processor architecture */
switch (fileHeader->Machine)
{
case IMAGE_FILE_MACHINE_I386:
initNTPE(IMAGE_OPTIONAL_HEADER32, 4);
return data;
case IMAGE_FILE_MACHINE_AMD64:
initNTPE(IMAGE_OPTIONAL_HEADER64, 8);
return data;
}
}
catch (std::exception&)
{
}
return std::nullopt;
}
//**********************************************************************************
// FUNCTION: getImportList(IMAGE_NTPE_DATA& ntpe)
//
// ARGS:
// IMAGE_NTPE_DATA& ntpe - data from PE file.
//
// DESCRIPTION:
// Retrieves IMPORT_LIST(std::map< std::string, std::set< std::string >>) with all loaded into PE libraries names and imported functions.
// Map key: loaded dll's names.
// Map value: set of imported functions names.
//
// Documentation links:
// Import Directory Table: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#import-directory-table
//
// RETURN VALUE:
// std::optional< IMPORT_LIST >.
// std::nullopt in case of error.
//
//**********************************************************************************
std::optional< IMPORT_LIST > getImportList(IMAGE_NTPE_DATA& ntpe)
{
try
{
/* if no imaage import directory in file returns std::nullopt */
if (ntpe.dataDirectories[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress == 0)
return std::nullopt;
IMPORT_LIST result;
/* import table offset */
DWORD impOffset = rva2offset(ntpe, ntpe.dataDirectories[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress);
/* imoprt table descriptor from import table offset + file base adress */
PIMAGE_IMPORT_DESCRIPTOR impTable = (PIMAGE_IMPORT_DESCRIPTOR)(impOffset + ntpe.fileBase);
/* while names in import table */
while (impTable->Name != 0)
{
/* pointer to DLL name from offset of current section name + file base adress */
std::string modname = rva2offset(ntpe, impTable->Name) + ntpe.fileBase;
std::transform(modname.begin(), modname.end(), modname.begin(), ::toupper);
/* start adress of names in look up table from import table name RVA */
char* cell = ntpe.fileBase + ((impTable->OriginalFirstThunk) ? rva2offset(ntpe, impTable->OriginalFirstThunk) : rva2offset(ntpe, impTable->FirstThunk));
/* while names in look up table */
for (;; cell += ntpe.CellSize)
{
int64_t rva = 0;
/* break if rva = 0 */
memcpy(&rva, cell, ntpe.CellSize);
if (!rva)
break;
/* if rva > 0 function was imported by name. if rva < 0 function was imported by ordinall */
if (rva > 0)
result[modname].emplace(ntpe.fileBase + rva2offset(ntpe, rva) + 2);
else
result[modname].emplace(std::string("#ord: ") + std::to_string(rva & 0xFFFF));
};
impTable++;
};
return result;
}
catch (std::exception&)
{
return std::nullopt;
}
};
//**********************************************************************************
// FUNCTION: getImportList(IMAGE_NTPE_DATA& ntpe)
//
// ARGS:
// std::wstring_view filePath - path to file.
//
// DESCRIPTION:
// Retrieves IMPORT_LIST(std::map< std::string, std::set< std::string >>) with all loaded into PE libraries names and imported functions bu path.
// Map key: loaded dll's names.
// Map value: set of imported functions names.
//
// Documentation links:
// Import Directory Table: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#import-directory-table
//
// RETURN VALUE:
// std::optional< IMPORT_LIST >.
// std::nullopt in case of error.
//
//**********************************************************************************
std::optional< IMPORT_LIST > getImportList(std::wstring_view filePath)
{
std::vector< char > buffer;
/* obtain base address of mapped file from tools::readFile function */
bool result = tools::readFile(filePath, buffer);
/* return nullopt if readFile failes or obtained buffer is empty */
if (!result || buffer.empty())
return std::nullopt;
/* get IMAGE_NTPE_DATA from base address of mapped file */
std::optional< IMAGE_NTPE_DATA > ntpe = getNTPEData(buffer.data(), buffer.size());
if (!ntpe)
return std::nullopt;
/* return result of overloaded getImportList function with IMAGE_NTPE_DATA as argument */
return getImportList(*ntpe);
}
//**********************************************************************************
// FUNCTION: getSectionsList(IMAGE_NTPE_DATA& ntpe)
//
// ARGS:
// IMAGE_NTPE_DATA& ntpe - data from PE file.
//
// DESCRIPTION:
// Retrieves SECTIONS_LIST from IMAGE_NTPE_DATA.
// SECTIONS_LIST - vector of sections headers from portable executable file.
// Sections names exmaple: .data, .code, .src
//
// Documentation links:
// IMAGE_SECTION_HEADER: https://learn.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-image_section_header
// Section Table (Section Headers): https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#section-table-section-headers
//
// RETURN VALUE:
// std::optional< SECTIONS_LIST >.
// std::nullopt in case of error.
//
//**********************************************************************************
std::optional< SECTIONS_LIST > getSectionsList(IMAGE_NTPE_DATA& ntpe)
{
try
{
/* result vector of section directories */
SECTIONS_LIST result;
/* iterations through all image section headers poiners in IMAGE_NTPE_DATA structure */
for (uint64_t sectionIndex = 0; sectionIndex < ntpe.fileHeader->NumberOfSections; sectionIndex++)
{
/* pushing IMAGE_SECTION_HEADER from iamge section headers */
result.push_back(ntpe.sectionDirectories[sectionIndex]);
}
return result;
}
catch (std::exception&)
{
}
/* returns nullopt in case of error */
return std::nullopt;
}
}
Du kan hitta koden för hela projektet på vår github:
https://github.com/SToFU-Systems/DSAVE
Lista över använda verktyg
- PE Tools: https://github.com/petoolse/petools Det här är ett öppen källkod-verktyg för att manipulera header PE-fält. Stöder x86- och x64-filer.
- WinDbg: https://learn.microsoft.com/en-us/windows-hardware/drivers/debugger/debugger-download-tools Microsofts systemfelsökare. Oumbärlig i arbetet för en systemprogrammerare för Windows OS.
- x64Dbg: https://x64dbg.com Enkel, lättvikts öppen källkod-debugger för x64/x86 för windows.
- WinHex: http://www.winhex.com/winhex/hex-editor.html WinHex är en universell hex-redigerare, speciellt användbar inom områdena för datarättsmedicin, dataåterställning, redigering av lågnivådata.
VAD ÄR NÄSTA STEG?
Vi uppskattar ditt stöd och ser fram emot din fortsatta medverkan i vår gemenskap
I nästa artikel kommer vi tillsammans med dig att skriva modulen för fuzzy hashing och beröra frågan om svarta och vita listor.simplest import table analyzer.
Eventuella frågor till författarna av artikeln kan skickas till e-post: articles@stofu.io
Tack för din uppmärksamhet och ha en trevlig dag!




