INTRODUCTION AUX RESSOURCES DU FICHIER PE
Salutations, nos chers lecteurs !
Dans cet article, nous allons vous parler d'une partie importante et intéressante des fichiers PE : les RESSOURCES D'IMAGE PE (données liées au programme après sa compilation). Nous allons examiner les structures internes de l'arbre des ressources et écrire notre propre analyseur de ressources natif sans utiliser WinAPI.
Les ressources dans les fichiers PE (Portable Executable) sont des données intégrées qui constituent une partie intégrale de l'application. Elles incluent une variété d'éléments tels que des images, des icônes, des chaînes de texte, des boîtes de dialogue, des polices. Ces ressources sont intégrées directement dans le fichier exécutable, assurant leur disponibilité pour l'application pendant son exécution. Il est important de noter que des ressources telles que les images, les textes et les sons sont souvent ajoutés au programme après qu'il a été compilé. Cette approche présente plusieurs avantages significatifs, rendant le processus de développement plus flexible et efficace.
Imaginez que vous faites partie d'une équipe de développement travaillant à la création d'une nouvelle application. Votre équipe est composée de programmeurs, de designers et de gestionnaires de contenu. Chacun de vous contribue à créer quelque chose d'unique et d'utile.
Au début du projet, les programmeurs se concentrent sur la rédaction et le test du code. Ils créent le cadre de l'application, en s'assurant que toutes les fonctions fonctionnent correctement. En même temps, les designers et les gestionnaires de contenu travaillent à la création de ressources - images, sons, textes pour l'interface. Ce travail parallèle permet à l'équipe d'avancer rapidement et efficacement.
Lorsque la partie principale de la programmation est terminée, il est temps d'intégrer les ressources dans l'application. Cela se fait à l'aide d'outils spéciaux qui permettent d'ajouter des ressources à une application déjà compilée sans nécessiter de recompilation. C'est très pratique, surtout si vous devez apporter des modifications ou mettre à jour des ressources - il n'est pas nécessaire de recompiler tout le projet.
Un des aspects clés de ce processus est la localisation. Grâce à la séparation des ressources du code principal, la localisation de l'application devient beaucoup plus simple. Les textes d'interface, les messages d'erreur peuvent être facilement traduits et remplacés sans interférer avec le code principal. Cela permet à l'application d'être adaptée pour différents marchés linguistiques, la rendant accessible et compréhensible pour un large éventail d'utilisateurs dans le monde entier.
EXEMPLES D'UTILISATION DES RESSOURCES
- Icônes d'application : Icônes affichées dans l'Explorateur Windows ou sur la barre des tâches qui offrent une représentation visuelle de l'application.
- Boîtes de dialogue : Définitions des boîtes de dialogue que l'application affiche pour l'interaction avec l'utilisateur, telles que les fenêtres de paramètres ou d'avertissement.
- Menus : Structures de menu utilisées dans l'interface utilisateur offrant navigation et fonctionnalité.
- Chaînes : Chaînes localisées utilisées pour afficher du texte dans l'application, y compris les messages d'erreur, les infobulles et d'autres interfaces utilisateur.
- Sons : Fichiers audio que l'application peut jouer dans certaines situations, comme les notifications sonores.
- Curseurs : Curseurs graphiques utilisés pour interagir avec l'interface utilisateur, tels que des flèches, des pointeurs ou des curseurs animés.
- Informations de version (Version Info) : Contient des informations sur la version de l'application, les droits d'auteur, le nom du produit et d'autres données liées à la version.
- Manifeste : Un fichier XML qui contient des informations sur la configuration de l'application, y compris les exigences de version de Windows et les paramètres de sécurité.
- RC_DATA : Données arbitraires définies par le développeur, qui peuvent inclure des données binaires, des fichiers de configuration ou d'autres ressources spécifiques à l'application.
COMMENT AFFICHER ET MODIFIER LES RESSOURCES DANS UN FICHIER EXÉCUTABLE PORTABLE ?
Pouvons-nous visualiser et modifier des ressources dans une application compilée ? Absolument ! Tout ce dont vous avez besoin est l'outil adéquat. Il existe des outils qui offrent une large gamme de capacités pour travailler avec les ressources dans les fichiers exécutables compilés, incluant la visualisation, la modification, l'ajout et la suppression de ressources.
Voici une liste d'éditeurs de ressources qui peuvent être utilisés pour visualiser ou modifier des ressources dans des fichiers exécutables déjà compilés :
- Resource Hacker : C'est un éditeur de ressources pour applications Windows 32-bit et 64-bit. Il permet de visualiser et d'éditer les ressources dans les fichiers exécutables (.exe, .dll, .scr, etc.) et les bibliothèques de ressources compilées (.res, .mui). Resource Hacker
- ResEdit : Un éditeur de ressources gratuit pour les programmes Win32. Convient pour travailler avec des dialogues, icônes, informations de version et autres types de ressources. ResEdit
- Resource Tuner : Un éditeur de ressources qui permet d'ouvrir des fichiers exécutables avec des problèmes et d'éditer des données cachées que d'autres éditeurs ne voient tout simplement pas. Resource Tuner
- Resource Builder : Un éditeur de ressources puissant et complet pour Windows. Permet de créer, éditer et compiler des fichiers de ressources (.RC, .RES, et autres), ainsi que d'éditer les ressources dans des fichiers exécutables compilés. Resource Builder
- Visual Studio : Fournit un éditeur de ressources qui permet d'ajouter, de supprimer et de modifier des ressources. Visual Studio
- Resource Tuner Console : Un outil puissant en ligne de commande pour éditer des ressources, idéal pour une utilisation dans des fichiers batch (.bat). Resource Tuner Console
- Qt Centre : Permet d'éditer les fichiers de ressources de fichiers exécutables compilés en utilisant Qt. Qt Centre
Examinons de plus près le premier outil de la liste : Resource Hacker.
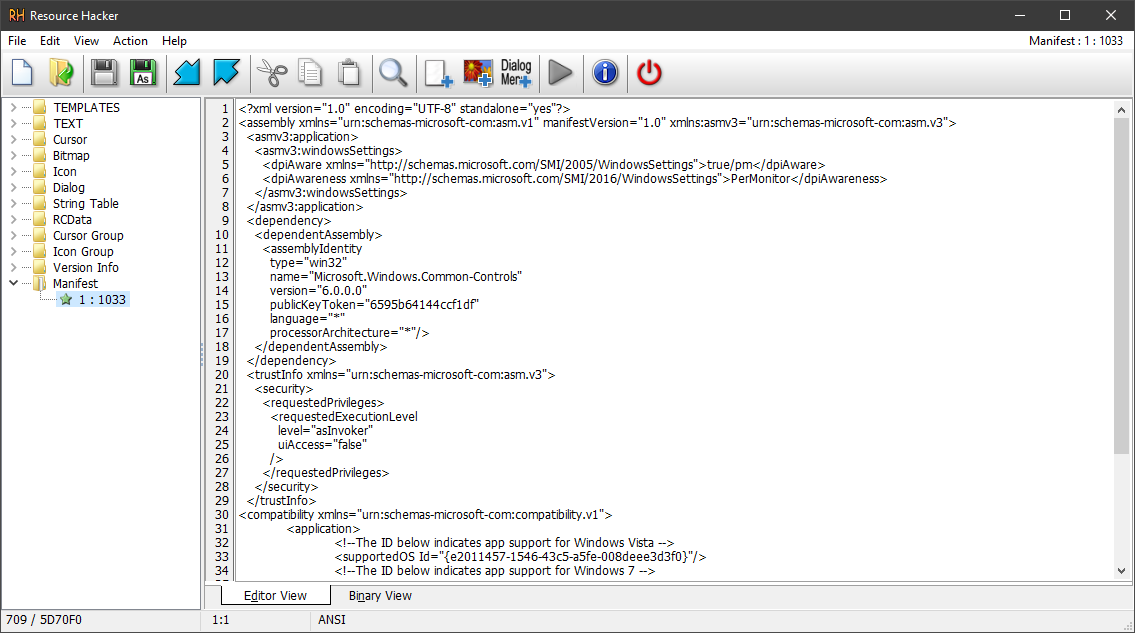
Cet outil vous permet non seulement de visualiser et d'extraire les ressources d'un fichier exécutable, mais aussi de les modifier !
Ces ressources, qui peuvent inclure des icônes, des menus, des boîtes de dialogue et d'autres types de données, se trouvent généralement dans une section spécifique du fichier PE appelée .rsrc (section des ressources). Toutefois, il est important de noter que ce n'est pas une règle stricte et des exceptions peuvent survenir.
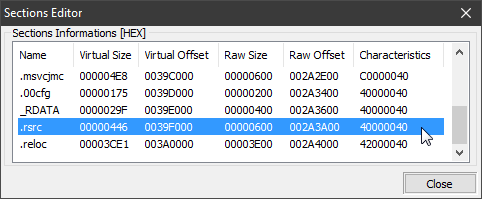
Un aspect essentiel de la navigation et de l'accès à ces ressources dans un fichier PE est le IMAGE_DATA_DIRECTORY[IMAGE_DIRECTORY_ENTRY_RESOURCES]. Cette entrée de répertoire fait partie de l'en-tête optionnel du fichier PE, spécifiquement dans le tableau des répertoires de données. Elle sert de pointeur ou de référence aux ressources dans l'image. Le IMAGE_DIRECTORY_ENTRY_RESOURCES fournit des informations sur l'emplacement (tel que l'adresse virtuelle relative) et la taille des données de ressource.
STRUCTURE DES RESSOURCES DANS LES FICHIERS EXÉCUTABLES PORTABLES
Vue Générale
Examinons en détail les structures utilisées dans la section des ressources d'un fichier PE (Portable Executable). La section des ressources dans les fichiers PE de Windows possède une structure arborescente hiérarchique unique à trois niveaux. Cette arborescence est utilisée pour organiser et accéder à des ressources telles que les icônes, les curseurs, les chaînes de caractères, les dialogues, et autres. Voici comment elle est structurée :
Niveau 1 : Types de Ressources
Au niveau supérieur de l'arbre se trouvent les types de ressources. Chaque type de ressource peut être identifié soit par un identifiant numérique (ID), soit par un nom sous forme de chaîne.
Niveau 2 : Noms des Ressources
Au deuxième niveau, chaque type de ressource possède ses propres noms ou identifiants. Cela vous permet d'avoir plusieurs ressources du même type, comme plusieurs icônes ou lignes.
Niveau 3 : Langues de Ressources
Au troisième niveau, chaque ressource dispose de variantes pour différentes localisations linguistiques. Cela permet de localiser la même ressource, comme un dialogue, dans différentes langues.
Structures de données
Les structures de données suivantes sont utilisées pour représenter cette hiérarchie :
- IMAGE_RESOURCE_DIRECTORY : Cette structure représente un en-tête pour chaque niveau de l'arbre et contient des informations générales sur les entrées de ce niveau.
- IMAGE_RESOURCE_DIRECTORY_ENTRY : Ce sont des éléments qui peuvent soit être des sous-répertoires (pointant vers un autre IMAGE_RESOURCE_DIRECTORY), soit les feuilles finales de l'arbre, pointant vers les données de ressource réelles.
- IMAGE_RESOURCE_DATA_ENTRY : Cette structure pointe vers les données de la ressource elle-même et contient sa taille et son décalage.
La visualisation de l'arbre des ressources pourrait ressembler à ce qui suit :
Root (IMAGE_DATA_DIRECTORY[IMAGE_DIRECTORY_ENTRY_RESOURCES].VirtualAddress)
|
+-- Type (RT_ICON, RT_STRING, ...)
|
+-- Name (ID or String)
|
+-- Language (Locale ID)
|
+-- Data (Actual resource data)
IMAGE_RESOURCE_DIRECTORY
|
|-- IMAGE_RESOURCE_DIRECTORY_ENTRY (Resource Types)
| |-- IMAGE_RESOURCE_DIRECTORY (Resource names)
| | |-- IMAGE_RESOURCE_DIRECTORY_ENTRY (Names)
| | | |-- IMAGE_RESOURCE_DIRECTORY (Languages)
| | | | |-- IMAGE_RESOURCE_DIRECTORY_ENTRY (Languages)
| | | | | |-- IMAGE_RESOURCE_DATA_ENTRY (Resource data)
Chaque nœud de cet arbre représente un IMAGE_RESOURCE_DIRECTORY, et les feuilles sont des IMAGE_RESOURCE_DATA_ENTRIES, qui pointent directement vers les données de la ressource. Lors de l'analyse manuelle des ressources, un développeur doit parcourir cet arbre, en commençant par la racine, et naviguer séquentiellement à travers tous les niveaux pour trouver les données nécessaires.
IMAGE_RESOURCE_DIRECTORY
Cette structure sert de en-tête pour chaque niveau de l'arbre de ressources et contient des informations sur les entrées de ce niveau.
typedef struct _IMAGE_RESOURCE_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
WORD NumberOfNamedEntries;
WORD NumberOfIdEntries;
// IMAGE_RESOURCE_DIRECTORY_ENTRY DirectoryEntries[];
} IMAGE_RESOURCE_DIRECTORY, *PIMAGE_RESOURCE_DIRECTORY;
- Characteristics : Typiquement inutilisées et définies à 0.
- TimeDateStamp : Horodatage de la création de la ressource.
- MajorVersion and MinorVersion: La version de l'annuaire de ressources.
- NumberOfNamedEntries: Le nombre d'entrées de ressources avec des noms.
- NumberOfIdEntries: Le nombre d'entrées de ressources avec des identificateurs numériques.
IMAGE_RESOURCE_DIRECTORY_ENTRY
Éléments qui peuvent être soit des sous-répertoires, soit les feuilles finales de l'arbre.
typedef struct _IMAGE_RESOURCE_DIRECTORY_ENTRY {
union {
struct {
DWORD NameOffset:31;
DWORD NameIsString:1;
};
DWORD Name;
WORD Id;
};
union {
DWORD OffsetToData;
struct {
DWORD OffsetToDirectory:31;
DWORD DataIsDirectory:1;
};
};
} IMAGE_RESOURCE_DIRECTORY_ENTRY, *PIMAGE_RESOURCE_DIRECTORY_ENTRY;
- Name: Si NameIsString est défini sur 1, ce champ contient un décalage pointant vers une chaîne UNICODE représentant le nom de la ressource. Si NameIsString est défini sur 0, le champ Id est utilisé pour identifier la ressource par un identifiant numérique.
- OffsetToData : Si DataIsDirectory est défini sur 1, ce champ contient un décalage pointant vers un autre IMAGE_RESOURCE_DIRECTORY (c.-à-d., un sous-répertoire). Si DataIsDirectory est défini sur 0, ce décalage pointe vers un IMAGE_RESOURCE_DATA_ENTRY.
IMAGE_RESOURCE_DATA_ENTRY
Cette structure pointe vers les données réelles de la ressource.
typedef struct _IMAGE_RESOURCE_DATA_ENTRY {
DWORD OffsetToData;
DWORD Size;
DWORD CodePage;
DWORD Reserved;
} IMAGE_RESOURCE_DATA_ENTRY, *PIMAGE_RESOURCE_DATA_ENTRY;
- OffsetToData : Le décalage depuis le début de la section des ressources jusqu'aux données de la ressource.
- Size : La taille des données de la ressource en octets.
- CodePage : La page de code utilisée pour le codage des données de la ressource.
- Reserved : Réservé ; généralement défini à 0.
IMPORTANT ! Les décalages dans IMAGE_RESOURCE_DIRECTORY et IMAGE_RESOURCE_DIRECTORY_ENTRY sont calculés à partir du début des ressources (IMAGE_DATA_DIRECTORY[IMAGE_DIRECTORY_ENTRY_RESOURCES].VirtualAddress), et seuls les décalages dans IMAGE_RESOURCE_DATA_ENTRY sont calculés à partir du début de l'image de base !
ÉCRIVONS UN ANALYSEUR DE RESSOURCES NATIVES !
Il est temps d'écrire notre propre analyseur de ressources natif sans utiliser WinAPI ! Le parsing manuel des ressources, au lieu d'utiliser les fonctions de l'API Windows telles que EnumResourceTypes ou EnumResourceNames, présente plusieurs avantages, notamment dans le contexte de l'analyse de sécurité et de la vérification antivirus :
- Sécurité : Les fonctions de l'API telles que EnumResourceTypes et EnumResourceNames nécessitent que le fichier exécutable soit chargé dans l'espace d'adresse du processus, ce qui pourrait conduire à l'exécution de code malveillant si le fichier contient des virus ou des chevaux de Troie. L'analyse manuelle des ressources évite ce risque.
- Indépendance de la Plateforme : L'analyse manuelle des ressources n'est pas dépendante de la version du système d'exploitation et de son WinAPI, ce qui en fait une solution plus universelle.
- Analyse Heuristique : L'analyse manuelle permet l'application d'heuristiques complexes et d'algorithmes de détection qui peuvent être nécessaires pour identifier des menaces nouvelles ou inconnues.
- Performance : L'analyse peut être optimisée pour de meilleures performances par rapport à l'utilisation de WinAPI, surtout lors de l'analyse d'un grand nombre de fichiers.
- Contrôle : Avec l'analyse manuelle, l'analyste a un contrôle total sur le processus et peut le peaufiner pour des besoins d'analyse spécifiques, tandis que les fonctions de l'API offrent un contrôle limité et peuvent ne pas révéler tous les aspects des ressources.
- Protection : Les logiciels malveillants peuvent utiliser diverses méthodes pour échapper à la détection, y compris manipuler les ressources de manière à ce qu'elles ne soient pas détectées par les API standard. L'analyse manuelle permet de détecter de telles manipulations.
- Accès Complet : Les fonctions de l'API peuvent ne pas fournir un accès à toutes les ressources, notamment si elles sont corrompues ou délibérément altérées. L'analyse manuelle permet d'analyser toutes les données sans les limitations imposées par l'API.
- Gestion des Erreurs : L'utilisation des fonctions de l'API peut limiter la gestion des erreurs, tandis que l'analyse manuelle permet des réponses plus flexibles aux situations non standard et aux anomalies dans la structure du fichier.
struct ResourceInfo
{
DWORD Size; // Size of the resource data
PBYTE data; // Offset of the resource data from the beginning of the file
union {
WORD TypeID; // Resource type ID or
PIMAGE_RESOURCE_DIR_STRING_U Type; // resource type
};
union {
WORD NameID; // Resource name ID or
PIMAGE_RESOURCE_DIR_STRING_U Name; // resource name
};
WORD Language; // Language of the resource
};
std::optional> getAllResources(BYTE* pBase, uint64_t fileSize)
{
IMAGE_RESOURCE_DIRECTORY* pTypesDirectory = nullptr;
std::vector resources;
try
{
//********************************************************
// parse PE header
//********************************************************
IMAGE_DOS_HEADER* pDosHeader = reinterpret_cast(pBase);
IMAGE_NT_HEADERS* pNtHeaders = reinterpret_cast(pBase + pDosHeader->e_lfanew);
// Verify that the PE signature is valid, indicating a valid PE file.
if (pNtHeaders->Signature != IMAGE_NT_SIGNATURE)
return std::nullopt;
// Depending on the machine type (32-bit or 64-bit), obtain the resource directory data.
IMAGE_DATA_DIRECTORY resourceDirectory;
switch (pNtHeaders->FileHeader.Machine)
{
case IMAGE_FILE_MACHINE_I386:
resourceDirectory = reinterpret_cast(pNtHeaders)->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_RESOURCE];
break;
case IMAGE_FILE_MACHINE_AMD64:
resourceDirectory = reinterpret_cast(pNtHeaders)->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_RESOURCE];
break;
default:
return std::nullopt;
};
// If the resource directory is empty, exit as there are no resources.
if (resourceDirectory.Size == 0)
return std::nullopt;
// Convert the RVA of the resources to a RAW offset
uint64_t resourceBase = ntpe::RvaToOffset(pBase, resourceDirectory.VirtualAddress);
IMAGE_RESOURCE_DIRECTORY* pResourceDir = reinterpret_cast(pBase + resourceBase);
//********************************************************
// Start parsing the resource directory
//********************************************************
// Iterate through type entries in the resource directory.
// parse types
pTypesDirectory = pResourceDir;
IMAGE_RESOURCE_DIRECTORY_ENTRY* pTypeEntries = (IMAGE_RESOURCE_DIRECTORY_ENTRY*)(pTypesDirectory + 1);
for (uint64_t ti = 0; ti < pTypesDirectory->NumberOfNamedEntries + pTypesDirectory->NumberOfIdEntries; ti++)
{
// parse names
IMAGE_RESOURCE_DIRECTORY_ENTRY* pTypeEntry = &pTypeEntries[ti];
IMAGE_RESOURCE_DIRECTORY* pNamesDirectory = (IMAGE_RESOURCE_DIRECTORY*)(pBase + (pTypeEntry->OffsetToDirectory & 0x7FFFFFFF) + resourceBase);
for (uint64_t ni = 0; ni < pNamesDirectory->NumberOfNamedEntries + pNamesDirectory->NumberOfIdEntries; ni++)
{
// parse langs
IMAGE_RESOURCE_DIRECTORY_ENTRY* pNamesEntries = (IMAGE_RESOURCE_DIRECTORY_ENTRY*)(pNamesDirectory + 1);
IMAGE_RESOURCE_DIRECTORY_ENTRY* pNameEntry = &pNamesEntries[ni];
IMAGE_RESOURCE_DIRECTORY* pLangsDirectory = (IMAGE_RESOURCE_DIRECTORY*)(pBase + (pNameEntry->OffsetToDirectory & 0x7FFFFFFF) + resourceBase);
for (uint64_t li = 0; li < pLangsDirectory->NumberOfNamedEntries + pLangsDirectory->NumberOfIdEntries; li++)
{
// parse data
IMAGE_RESOURCE_DIRECTORY_ENTRY* pLangsEntries = (IMAGE_RESOURCE_DIRECTORY_ENTRY*)(pLangsDirectory + 1);
IMAGE_RESOURCE_DIRECTORY_ENTRY* pLangEntry = &pLangsEntries[li];
IMAGE_RESOURCE_DATA_ENTRY* pDataEntry = (IMAGE_RESOURCE_DATA_ENTRY*)(pBase + resourceBase + pLangEntry->OffsetToData);
// Save the resource information in a structured format.
ResourceInfo entry = {};
entry.Language = pLangsEntries->Id;
entry.Size = pDataEntry->Size;
entry.Type = (PIMAGE_RESOURCE_DIR_STRING_U)(pTypeEntry->NameIsString) ? (PIMAGE_RESOURCE_DIR_STRING_U)(pBase + pTypeEntry->NameOffset + resourceBase) : (PIMAGE_RESOURCE_DIR_STRING_U)(pTypeEntry->Id);
entry.Name = (PIMAGE_RESOURCE_DIR_STRING_U)(pNameEntry->NameIsString) ? (PIMAGE_RESOURCE_DIR_STRING_U)(pBase + pNameEntry->NameOffset + resourceBase) : (PIMAGE_RESOURCE_DIR_STRING_U)(pNameEntry->Id);
entry.data = ntpe::RvaToRaw(pBase, pDataEntry->OffsetToData);
resources.push_back(entry);
}
}
}
return resources;
}
catch (std::exception&)
{
return std::nullopt;
};
}
Vous pouvez trouver le code du projet entier sur notre github :
https://github.com/SToFU-Systems/DSAVE
Le parseur de ressources renvoie un vecteur contenant des structures avec des pointeurs vers les types de ressources, leurs noms, et l'identifiant de langue de chaque ressource. Dans chaque structure, il y a un pointeur vers les données de la ressource. Chaque structure reste valide tant que le fichier exécutable que nous lisons et analysons est en mémoire. Cela est très pratique pour écrire votre propre antivirus et scanner des fichiers. Une fois que le fichier est libéré, les pointeurs deviennent invalides.
LISTE DES OUTILS UTILISÉS
- PE Tools: https://github.com/petoolse/petools Ceci est un outil open source pour manipuler les champs d'en-tête PE. Prend en charge les fichiers x86 et x64.
- Resource Hacker: https://www.angusj.com/resourcehacker. C'est un éditeur de ressources pour les applications Windows 32 bits et 64 bits. Il vous permet de visualiser et d'éditer les ressources dans les fichiers exécutables (.exe, .dll, .scr, etc.) et les bibliothèques de ressources compilées (.res, .mui).
CONCLUSION
Et voilà, les amis !
Nous avons exploré les ressources des fichiers PORTABLE_EXECUTABLE du système d'exploitation Windows et avons écrit notre propre analyseur de ressources natif, simple mais assez efficace !
Nous apprécions votre soutien et attendons avec impatience votre participation continue dans notre communauté !
Toutes questions destinées aux auteurs de l'article peuvent être envoyées à l'email : articles@stofu.io
Merci !




