Hachage
Tout d'abord, abordons les bases et familiarisons-nous avec un concept tel que le hash !
Algorithme de hachage - est une fonction mathématique qui prend des données de n'importe quelle taille et produit une sortie appelée hachage ou empreinte numérique. La sortie est une représentation unique des données d'entrée, qui peut être utilisée pour vérifier que les données n'ont pas été altérées. Les algorithmes de hachage sont utilisés pour garantir l'intégrité et l'authenticité des données. En termes simples, un hachage est une empreinte digitale numérique unique d'une donnée. C'est comme un code qui représente les données. Le code est généré par une fonction mathématique appelée fonction de hachage. Si les données changent ne serait-ce qu'un peu, le hachage sera différent.
Il existe des caractéristiques clés primaires pour le hash :
-
Déterministe : Une fonction de hachage doit toujours produire la même sortie pour une entrée donnée. Cela signifie que si vous hachez deux fois les mêmes données, vous devriez obtenir la même valeur de hachage les deux fois.
-
Irreversibility : Il doit être infaisable sur le plan computationnel de reconstruire les données d'entrée originales à partir de leur valeur de hachage. Cette propriété est importante pour la sécurité, car elle protège les données originales d'être découvertes par des attaquants qui n'ont accès qu'à la valeur de hachage.
-
Uniformité : Une fonction de hachage devrait produire une distribution uniforme des valeurs de hachage à travers toutes les entrées possibles. Cela signifie que chaque valeur de hachage devrait être également susceptible de se produire, et il ne devrait y avoir aucun motif ni biais dans la distribution des valeurs de hachage.
-
Imprévisibilité : Il doit être infaisable sur le plan computationnel de prédire la valeur de hachage d'une entrée en se basant sur les valeurs de hachage d'autres entrées ou les propriétés de la fonction de hachage elle-même. Cette propriété est importante pour la sécurité, car elle rend difficile pour les attaquants de créer une collision (deux entrées différentes qui produisent la même valeur de hachage).
-
Irreversibility : Il doit être infaisable sur le plan computationnel de reconstruire les données d'entrée originales à partir de leur valeur de hachage. Cette propriété est importante pour la sécurité, car elle protège les données originales d'être découvertes par des attaquants qui n'ont accès qu'à la valeur de hachage.
-
Résistance aux attaques par collisions : Une fonction de hachage devrait résister aux attaques par collisions, qui consistent à trouver deux entrées différentes qui produisent la même valeur de hachage. Les attaques par collisions peuvent être utilisées pour créer des signatures numériques frauduleuses ou pour contourner les contrôles d'accès, il est donc important qu'une fonction de hachage soit conçue pour y résister.
Autres caractéristiques des hachages que vous pouvez trouver sur la page Wikipédia :
https://en.wikipedia.org/wiki/Hash_function
Vérification des données. Liste noire et liste blanche.
Dans le contexte des logiciels antivirus, les algorithmes de hachage sont utilisés pour détecter les logiciels malveillants ou exclure les alertes de faux positifs. Les logiciels antivirus maintiennent une base de données des hachages de malwares connus (blacklist) et des hachages de logiciels de confiance (whitelist). Lorsqu'un fichier est analysé, son hachage est comparé aux hachages présents dans la base de données. Les algorithmes de hachage les plus couramment utilisés pour la vérification des données sont MD5, SHA-1, SHA-256 et SHA-512.
L'utilisation de hachages dans les listes noires et blanches des antivirus aide à accélérer le processus de balayage, car le programme antivirus n'a pas besoin de réaliser une analyse détaillée de chaque fichier pour déterminer s'il est malveillant ou non. Au lieu de cela, il peut comparer les valeurs de hachage des fichiers à celles présentes dans la liste noire/blanche pour identifier rapidement les menaces connues ou les applications de confiance.
Blacklist. Dans le contexte de la cybersécurité et des logiciels antivirus, une blacklist est une liste de fichiers malveillants connus ou de parties de ces fichiers. Lorsqu'un programme antivirus analyse un ordinateur ou un réseau, il compare les fichiers et les entités rencontrés à la blacklist pour identifier toute menace. Si un fichier ou une entité correspond à une entrée sur la blacklist, le programme antivirus prendra des mesures pour le supprimer ou le mettre en quarantaine afin d'éviter qu'il ne cause des dommages.
Bien que les listes noires puissent être utiles pour détecter et prévenir les menaces connues, elles ne sont pas toujours efficaces pour protéger contre les menaces nouvelles et inconnues. Les attaquants peuvent utiliser diverses techniques, telles que l'obfuscation ou le polymorphisme, pour modifier le code ou le comportement d'un fichier ou d'une entité afin d'échapper à la détection par les programmes antivirus.
Par conséquent, les programmes antivirus utilisent souvent une combinaison de techniques, telles que le whitelisting et la détection basée sur le comportement, pour compléter l'utilisation des listes noires et offrir une protection plus complète contre un plus large éventail de menaces.
Whitelist. Dans le contexte de la cybersécurité et des logiciels antivirus, une whitelist est une liste de fichiers de confiance qui sont reconnus comme sûrs. Si un fichier ou une entité correspond à une entrée de la whitelist, le programme antivirus permettra son ouverture/exécution sans prendre de mesure, car il est considéré comme sûr.
Les listes blanches sont utiles pour prévenir les faux positifs dans les programmes antivirus et de sécurité. Les faux positifs se produisent lorsque un programme ou un fichier est signalé comme malveillant ou nuisible alors qu'il est en réalité sûr. En utilisant une liste blanche, les programmes de sécurité peuvent contourner ces faux positifs, ce qui peut économiser du temps et éviter des alertes inutiles.
Utiliser des hachages et des blacklists/whitelists peut être un moyen efficace de se protéger contre les menaces connues et de prévenir les faux positifs dans les programmes antivirus et de sécurité.
Pourquoi les antivirus utilisent-ils plusieurs algorithmes de hachage ?
Les programmes antivirus utilisent plusieurs algorithmes de hachage pour plusieurs raisons :
-
Bien que les listes noires puissent être efficaces pour détecter et prévenir les menaces connues, elles ne sont pas infaillibles. Les attaquants peuvent utiliser diverses techniques pour échapper à la détection, telles que la modification des données pour éviter de correspondre aux signatures dans la liste noire. Ces techniques sont appelées « attaques par collision ». Une attaque par collision est un type d'attaque cryptographique où l'attaquant essaie de trouver deux entrées différentes, comme des fichiers ou des messages, qui produisent la même valeur de hachage lorsqu'elles sont traitées par une fonction de hachage (collision). Le but d'une attaque par collision est de créer une paire d'entrées qui peut être utilisée pour subvertir un système qui repose sur l'intégrité des valeurs de hachage, telles que les signatures numériques, l'authentification des mots de passe ou les contrôles d'intégrité des données. Si un attaquant trouve une collision, il peut l'utiliser pour contourner les mesures de sécurité qui dépendent de la fonction de hachage. Pour atténuer le risque d'attaques par collision, les antivirus utilisent des fonctions de hachage robustes résistantes aux attaques, et emploient plusieurs fonctions de hachage simultanément. Par exemple, si un programme antivirus utilisait uniquement l'algorithme de hachage MD5, un attaquant pourrait potentiellement créer un fichier malveillant qui a la même valeur de hachage MD5 qu'un fichier légitime, et tromper le programme antivirus pour qu'il traite le fichier malveillant comme sûr. Cependant, utiliser plusieurs algorithmes de hachage, tels que MD5, SHA-1 et SHA-256, rend plus difficile pour un attaquant de créer une attaque par collision qui fonctionnerait contre tous les algorithmes simultanément.
-
Efficacité : Les différents algorithmes de hachage ont des exigences computationnelles différentes, et certains peuvent être plus efficaces que d'autres selon la taille du fichier, le type ou d'autres facteurs. L'utilisation de plusieurs algorithmes de hachage permet aux programmes antivirus de sélectionner l'algorithme le plus approprié pour une situation donnée, ce qui peut économiser du temps et de la puissance de traitement. Par exemple, SHA-256 peut être plus intensif en calcul que MD5, donc un programme antivirus peut choisir d'utiliser MD5 pour les fichiers plus petits et SHA-256 pour les fichiers plus volumineux.
-
Flexibilité : Les différents algorithmes de hachage sont conçus pour différents cas d'utilisation et applications. En utilisant plusieurs algorithmes de hachage, les programmes antivirus peuvent s'adapter à différents besoins et scénarios, tels que la détection de malwares, la vérification de l'intégrité des fichiers, ou la détection de modifications ou altérations. Par exemple, un enquêteur en informatique judiciaire peut utiliser un algorithme de hachage différent de celui d'un programme antivirus pour s'assurer que les données n'ont pas été modifiées pendant une investigation.
Utiliser plusieurs algorithmes de hachage est une meilleure pratique dans le développement de logiciels de cybersécurité et d'antivirus, car cela offre robustesse, compatibilité, efficacité et flexibilité dans la détection et la prévention des menaces cybernétiques.
Comment les antivirus reconnaissent-ils des données et des fichiers similaires mais non identiques ?
Des fichiers similaires mais non identiques peuvent poser un problème en cybersécurité car ils peuvent être utilisés par les attaquants pour échapper à la détection par les logiciels antivirus.
Par exemple, un attaquant peut prendre un fichier de logiciel malveillant connu et apporter de légères modifications à son code ou à sa structure, telles que changer les noms de variables ou réorganiser les instructions. Ces modifications peuvent suffire à créer un nouveau fichier qui est similaire mais pas identique au fichier de logiciel malveillant original, et qui peut ne pas être détecté par les logiciels antivirus qui se fondent sur des méthodes de détection basées sur des hachages traditionnels.
De plus, les attaquants peuvent utiliser des fichiers similaires mais pas identiques pour créer des malwares polymorphes, qui peuvent changer leur code ou leur structure à chaque infection pour éviter la détection. Les malwares polymorphes peuvent être très difficiles à détecter en utilisant les techniques antivirus traditionnelles, qui dépendent de la reconnaissance de modèles ou de signatures spécifiques dans le code du malware.
Pour résoudre ce problème, les antivirus utilisent des hachages flous.
Le hachage flou est une technique utilisée par certains logiciels antivirus pour détecter des fichiers similaires mais non identiques, y compris les malwares polymorphes. En divisant un fichier en morceaux plus petits et en comparant les hachages de ces morceaux à ceux d'autres fichiers, le hachage flou peut identifier des fichiers qui ont un code ou une structure similaires, même s'ils ne sont pas identiques.
Le hachage flou fonctionne en identifiant les séquences d'octets qui apparaissent fréquemment dans le fichier. Ces séquences, également connues sous le nom de "morceaux", sont ensuite hachées à l'aide d'une fonction de hachage cryptographique pour générer une valeur de hachage. Les valeurs de hachage des morceaux sont ensuite comparées à celles d'autres fichiers pour identifier les morceaux qui sont similaires.
L'avantage du hachage flou est qu'il peut détecter des similitudes même lorsque les fichiers ont été modifiés ou obscurcis, ce qui en fait un outil puissant pour identifier les variantes de logiciels malveillants connus. Par exemple, si un attaquant modifie un fichier de logiciel malveillant connu en changeant les noms des variables ou des fonctions, les méthodes de détection basées sur le hachage traditionnel peuvent ne pas détecter le fichier modifié. Cependant, le hachage flou peut toujours détecter le fichier modifié en identifiant des blocs qui sont similaires à ceux du fichier de logiciel malveillant original. Contrairement aux algorithmes de hachage cryptographique comme MD5, SHA-1 ou SHA-512, les algorithmes de hachage flou produisent des valeurs de hachage de longueur variable qui sont basées sur la similarité des données d'entrée.
Avantages des empreintes floues :
-
Détection de fichiers similaires : Les hachages flous peuvent détecter des fichiers similaires même s'ils ont été légèrement modifiés, ce qui est utile pour identifier des variantes de malwares connus.
-
Réduction des faux positifs : Les hachages flous peuvent réduire le nombre de faux positifs générés par les méthodes de détection basées sur les hachages traditionnels. Cela est dû au fait que les hachages flous peuvent détecter des fichiers qui sont similaires mais pas identiques aux malwares connus.
-
Résilience à l'obfuscation : Les hachages flous sont plus résistants aux techniques d'obfuscation utilisées par les attaquants pour éviter la détection. Cela est dû au fait que l'algorithme de hachage flou divise le fichier en petits morceaux et génère des hachages pour chaque morceau, rendant ainsi plus difficile pour un attaquant de modifier le fichier de manière à échapper à la détection.
Le hachage flou présente certaines limitations qui peuvent affecter son efficacité pour détecter des fichiers similaires mais non identiques :
-
Faux positifs : Le hachage flou peut produire des faux positifs, où des fichiers légitimes sont signalés comme malveillants parce qu'ils présentent un code ou une structure similaires à ceux d'un malware connu. Cela peut se produire si les fichiers partagent des bibliothèques ou des cadres communs.
-
Performance : Le hachage flou peut être intensif en termes de calcul, en particulier pour les gros fichiers. Cela peut ralentir le processus de balayage et affecter la performance du système.
-
Limitations de taille : Le hachage flou peut ne pas fonctionner correctement sur des fichiers très petits ou des fichiers à faible entropie, car il peut ne pas y avoir suffisamment de blocs uniques pour générer des hachages significatifs.
-
Altération : Le hachage flou peut ne pas être efficace si un attaquant le cible spécifiquement et modifie un fichier pour éviter la détection. Par exemple, un attaquant pourrait délibérément changer la structure d'un fichier pour empêcher qu'il soit identifié par le hachage flou.
Quelle est la différence entre les algorithmes de hachage cryptographique et les algorithmes de hachage flou ?
Les algorithmes de hachage cryptographique et les algorithmes de hachage flou sont tous deux utilisés en cybersécurité, mais ils ont des objectifs et des caractéristiques différents.
Les algorithmes de hachage cryptographique, tels que SHA-256 et MD5, sont conçus pour fournir l'intégrité et l'authenticité des données en générant des valeurs de hachage uniques de longueur fixe qui sont presque impossibles à inverser. Les algorithmes de hachage cryptographique sont utilisés pour vérifier l'intégrité des données.
Les algorithmes de hachage flou, tels que SSDEEP, sont conçus pour identifier des données similaires mais non identiques, telles que des fichiers qui ont été modifiés ou reconditionnés par des auteurs de logiciels malveillants. Le hachage flou utilise une technique de fenêtre glissante pour diviser les données en petits morceaux et générer des hachages probabilistes de longueur variable, qui sont comparés à une base de données de hachages de logiciels malveillants connus pour identifier les fichiers potentiellement malveillants.
Les algorithmes de hachage cryptographique sont conçus pour être résistants aux collisions, ce qui signifie qu'il est extrêmement difficile de trouver deux entrées qui produisent le même résultat de hachage. Les algorithmes de hachage flou n'ont pas besoin d'être résistants aux collisions car ils sont conçus pour détecter des similitudes entre les fichiers plutôt que de produire des résultats de hachage uniques
La principale différence entre les algorithmes de hachage cryptographique et les algorithmes de hachage flou réside dans leur niveau de déterminisme. Les algorithmes de hachage cryptographique produisent des hachages déterministes de longueur fixe qui sont uniques pour chaque entrée, tandis que les algorithmes de hachage flou produisent des hachages probabilistes de longueur variable qui sont similaires pour des entrées similaires.
Quels algorithmes de hachage flou utiliserons-nous dans notre solution ?
Dans notre solution, nous allons utiliser SSDEEP et TLSH.
ssdeep est un algorithme de hachage flou utilisé pour identifier des données similaires mais non identiques, telles que des variantes de logiciels malveillants. Il fonctionne en générant une valeur de hachage qui représente la similarité des données d'entrée, plutôt qu'un identifiant unique comme les fonctions de hachage cryptographique. La sortie de ssdeep est de longueur variable et probabiliste, ce qui lui permet de détecter même de légères différences entre deux fichiers. ssdeep est couramment utilisé dans l'analyse et la détection de malwares, et il est également intégré à divers outils de sécurité et logiciels antivirus.
TLSH (Trend Micro Locality Sensitive Hash) est un algorithme de hachage flou qui est utilisé pour identifier des données similaires mais pas identiques, telles que des variantes de logiciels malveillants. Il fonctionne en créant une valeur de hachage qui capture les caractéristiques uniques des données d'entrée, telles que la fréquence et l'ordre des octets. Le résultat de TLSH est de longueur variable et probabiliste, ce qui lui permet de détecter des similitudes même si les données d'entrée ont été modifiées ou obscurcies. TLSH est couramment utilisé dans l'analyse et la détection de logiciels malveillants, et il est également intégré dans divers outils de sécurité et logiciels antivirus.
ssdeep et TLSH utilisent tous les deux des métriques de distance pour déterminer la similarité entre deux valeurs de hachage. Cependant, les métriques de distance utilisées par ssdeep et TLSH sont différentes.
ssdeep utilise la métrique "fuzzy hash distance" pour calculer la distance entre deux valeurs de hachage. Cette métrique de distance est basée sur le nombre de blocs correspondants et non correspondants entre les deux hachages, ainsi que sur la taille des hachages. La métrique de distance est une valeur en pourcentage qui varie de 0 à 100, où 0 signifie que les deux hachages sont identiques, et 100 signifie que les deux hachages sont complètement différents.
TLSH, quant à lui, utilise la métrique "total diff" pour calculer la distance entre deux valeurs de hachage. Cette métrique de distance repose sur la différence entre les caractéristiques sensibles à la localité des deux ensembles de données en entrée. Le résultat de la métrique "total diff" est une valeur entre 0 et 1000, où 0 signifie que les deux valeurs de hachage sont identiques, et 1000 signifie que les deux valeurs de hachage sont complètement différentes.
Construction du module de hachage
Pour notre solution, nous utiliserons des bibliothèques open-source :
1. PolarSSL : https://polarssl.org/
PolarSSL est une bibliothèque logicielle libre et open-source pour l'implémentation de protocoles cryptographiques tels que Transport Layer Security (TLS), Secure Sockets Layer (SSL), Datagram Transport Layer Security (DTLS). Elle offre divers algorithmes et protocoles cryptographiques, incluant des fonctions de hachage, le chiffrement symétrique et asymétrique, les signatures numériques, et les algorithmes d'échange de clés. PolarSSL est conçu pour être léger et efficace, ce qui le rend approprié pour une utilisation dans des environnements à ressources limitées.
2. ssdeep : http://ssdeep.sf.net/
3. TLSH : https://github.com/trendmicro/tlsh/
Après avoir implémenté les bibliothèques dans le projet, nous ajoutons un code simple :
struct HashData
{
BYTE md5[16];
BYTE sha1[20];
BYTE sha512[64];
std::string ssdeep;
std::string tlsh;
};
HashData hash(const void* buff, uint64_t size)
{
HashData snap = {};
hashes::md5(buff, size, snap.md5);
hashes::sha1(buff, size, snap.sha1);
hashes::sha4(buff, size, snap.sha512);
snap.ssdeep = hashes::ssdeepHash(buff, size);
snap.tlsh = hashes::tlshHash(buff, size);
return snap;
}
Vérification du module de hachage
Il est temps de tester le module de hachage ! Pour ce faire, nous allons créer un fichier texte avec le contenu suivant :
All the World`s a Stage by William Shakespeare
All the world`s a stage,
And all the men and women merely players;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first, the infant,
Mewling and puking in the nurse`s arms.
Then the whining schoolboy, with his satchel
And shining morning face, creeping like snail
Unwillingly to school. And then the lover,
Sighing like furnace, with a woeful ballad
Made to his mistress` eyebrow. Then a soldier,
Full of strange oaths and bearded like the pard,
Jealous in honor, sudden and quick in quarrel,
Seeking the bubble reputation
Even in the cannon`s mouth. And then the justice,
In fair round belly with good capon lined,
With eyes severe and beard of formal cut,
Full of wise saws and modern instances;
And so he plays his part. The sixth age shifts
Into the lean and slippered pantaloon,
With spectacles on nose and pouch on side;
His youthful hose, well saved, a world too wide
For his shrunk shank, and his big manly voice,
Turning again toward childish treble, pipes
And whistles in his sound. Last scene of all,
That ends this strange eventful history,
Is second childishness and mere oblivion,
Sans teeth, sans eyes, sans taste, sans everything.
TEST 1 : créez deux fichiers identiques avec le même contenu (texte ci-dessus) et calculez les hash.
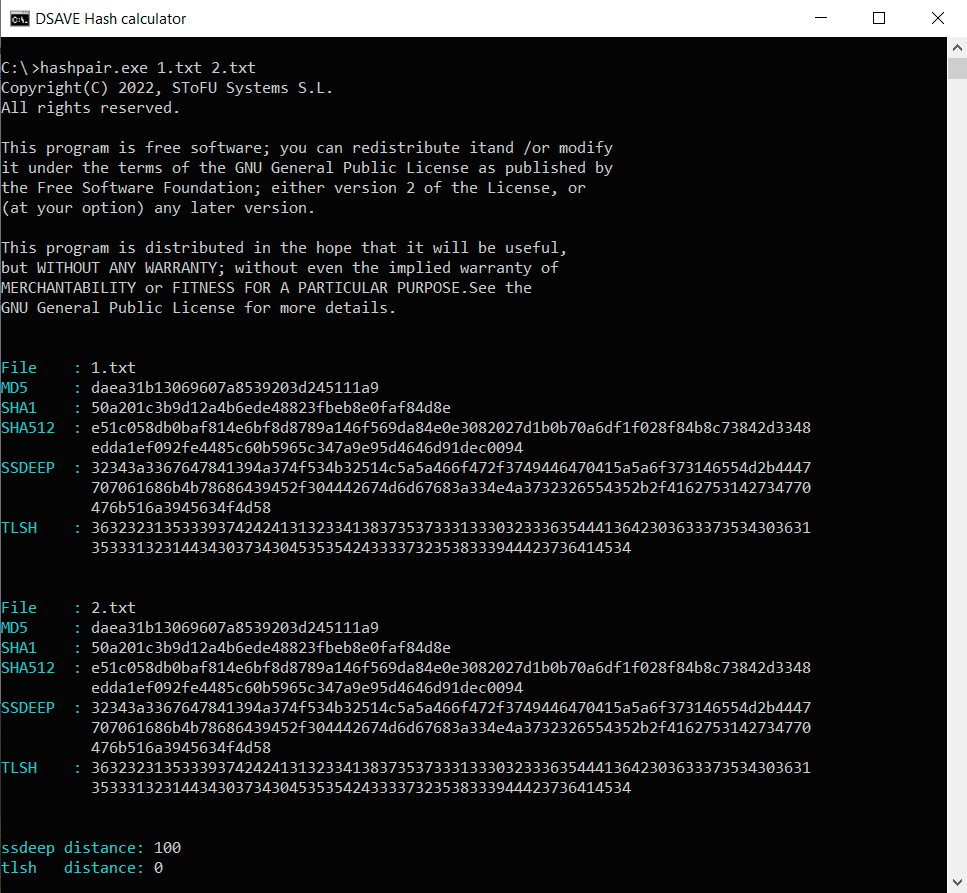
SSDEEP indique que les fichiers sont identiques à 100%. TLSH indique qu'il y a 0% de différences entre les fichiers.
TEST 2 : Créez deux fichiers identiques avec le même contenu, effectuez des modifications dans le deuxième fichier et calculez les hashes
Contenu du deuxième fichier :
All the World`s a Stage by William Shakespeare
O lovely maidens, fall in love,
But not with Muscovites,
For Muscovites are foreign folk,
They do not treat you right.
A Muscovite will love for sport,
And laughing go away;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first, the infant,
Mewling and puking in the nurse`s arms.
Then the whining schoolboy, with his satchel
And shining morning face, creeping like snail
Unwillingly to school. And then the lover,
Sighing like furnace, with a woeful ballad
Made to his mistress` eyebrow. Then a soldier,
Full of strange oaths and bearded like the pard,
Jealous in honor, sudden and quick in quarrel,
Seeking the bubble reputation
Even in the cannon`s mouth. And then the justice,
In fair round belly with good capon lined,
With eyes severe and beard of formal cut,
Full of wise saws and modern instances;
And so he plays his part. The sixth age shifts
Into the lean and slippered pantaloon,
With spectacles on nose and pouch on side;
His youthful hose, well saved, a world too wide
For his shrunk shank, and his big manly voice,
Turning again toward childish treble, pipes
And whistles in his sound. Last scene of all,
That ends this strange eventful history,
Is second childishness and mere oblivion,
Sans teeth, sans eyes, sans taste, sans everything.
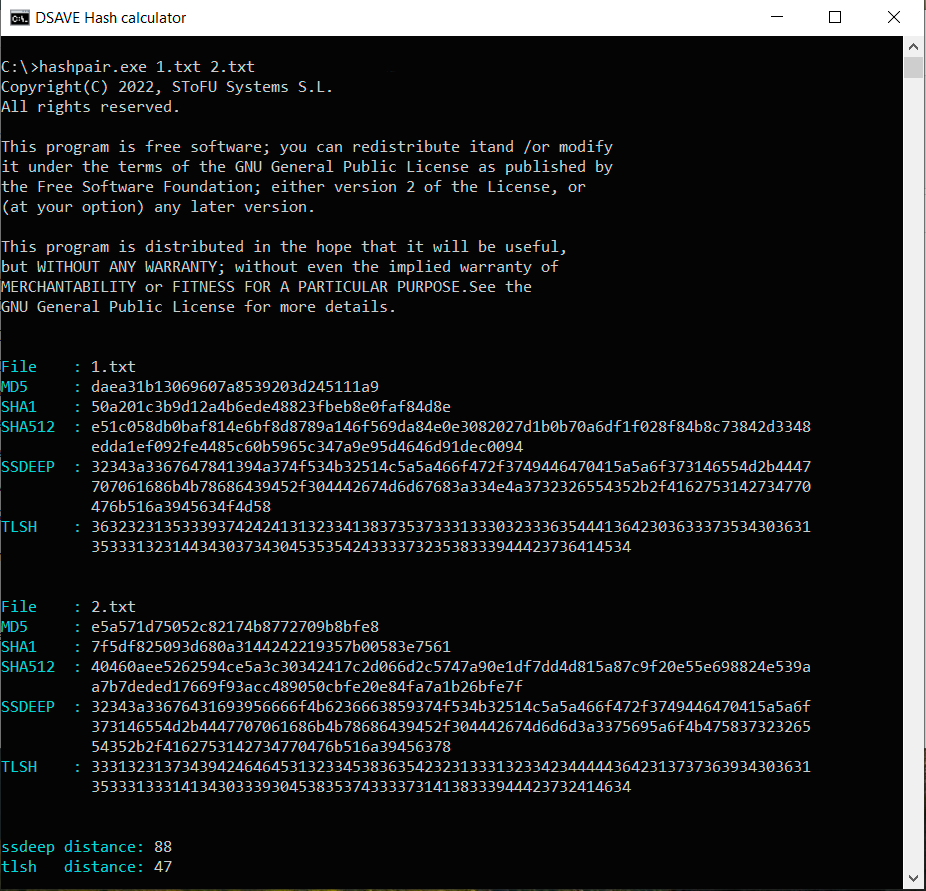
SSDEEP indique que les fichiers sont identiques à 88 %. TLSH indique qu'il y a 4,7 % de différences entre les fichiers.
TEST 3 : calculer les hachages pour deux fichiers texte complètement différents
Contenu du deuxième fichier :
"Katerina", poem of Taras Shevchenko
(translated by John Weir)
O lovely maidens, fall in love,
But not with Muscovites [2],
For Muscovites are foreign folk,
They do not treat you right.
A Muscovite will love for sport,
And laughing go away;
He`ll go back to his Moscow land
And leave the maid a prey
To grief and shame...
It could be borne
If she were all alone,
But scorn is also heaped upon
Her mother frail and old.
The heart e`en languishing can sing –
For it knows how to wait;
But this the people do not see:
“A strumpet!“ they will say.
O lovely maidens, fall in love,
But not with Muscovites,
For Muscovites are foreign folk,
They leave you in a plight.
Young Katerina did not heed
Her parent`s warning words,
She fell in love with all her heart,
Forgetting all the world.
The orchard was their trysting-place;
She went there in the night
To meet her handsome Muscovite,
And thus she ruined her life.
Her anxious mother called and called
Her daughter home in vain;
There where her lover she caressed,
The whole night she remained.
Thus many nights she kissed her love
With passion strong and true,
The village gossips meanwhile hissed:
“A girl of ill repute!”
Let people talk, let gossips prate,
She does not even hear:
She is in love, that`s all she cares,
Nor feels disaster near.
Bad tidings came of strife with Turks,
The bugles blew one morn:
Her Muscovite went off to war,
And she remained at home.
A kerchief o`er her braids they placed
To show she`s not a maid,
But Katerina does not mind,
Her lover she awaits.
He promised her that he’d return
If he was left alive,
That he`d come back after the war –
And then she`d be his wife,
An army bride, a Muscovite
Herself, her ills forgot,
And if in meantime people prate,
Well, let the people talk!
She does not worry, not a bit –
The reason that she weeps
Is that the girls at sundown sing
Without her on the streets.
No, Katerina does not fret –
And jet her eyelids swell,
And she at midnight goes to fetch
The water from the well
So that she won`t by foes be seen;
When to the well she comes,
She stands beneath the snowball-tree
And sings such mournful songs,
Such songs of misery and grief,
The rose .itself must weep.
Then she comes home - content that she
By neighbours was not seen.
No, Katerina does not fret.
She`s carefree as can be -
With her new kerchief on her head
She looks out on the street.
So at the window day by day
Six months she sat in vain....
With sickness then was overcome,
Her body racked with pain.
Her illness very grievous proved.
She barely breathed for days ...
When it was over - by the stove
She rocked her tiny babe.
The gossips` tongues now got free rein.
The other mothers jibed
That soldiers marching home again
At her house spent the night.
“Oh, you have reared a daughter fair.
And not alone beside
The stove she sits - she`s drilling there
A little Muscovite.
She found herself a brown-eyed son...
You must have taught her how!...
Oh fie on ye, ye prattle tongues,
I hope yourselves you`ll feel
Someday such pains as she who bore
A son that you should jeer!
Oh, Katerina, my poor dear!
How cruel a fate is thine!
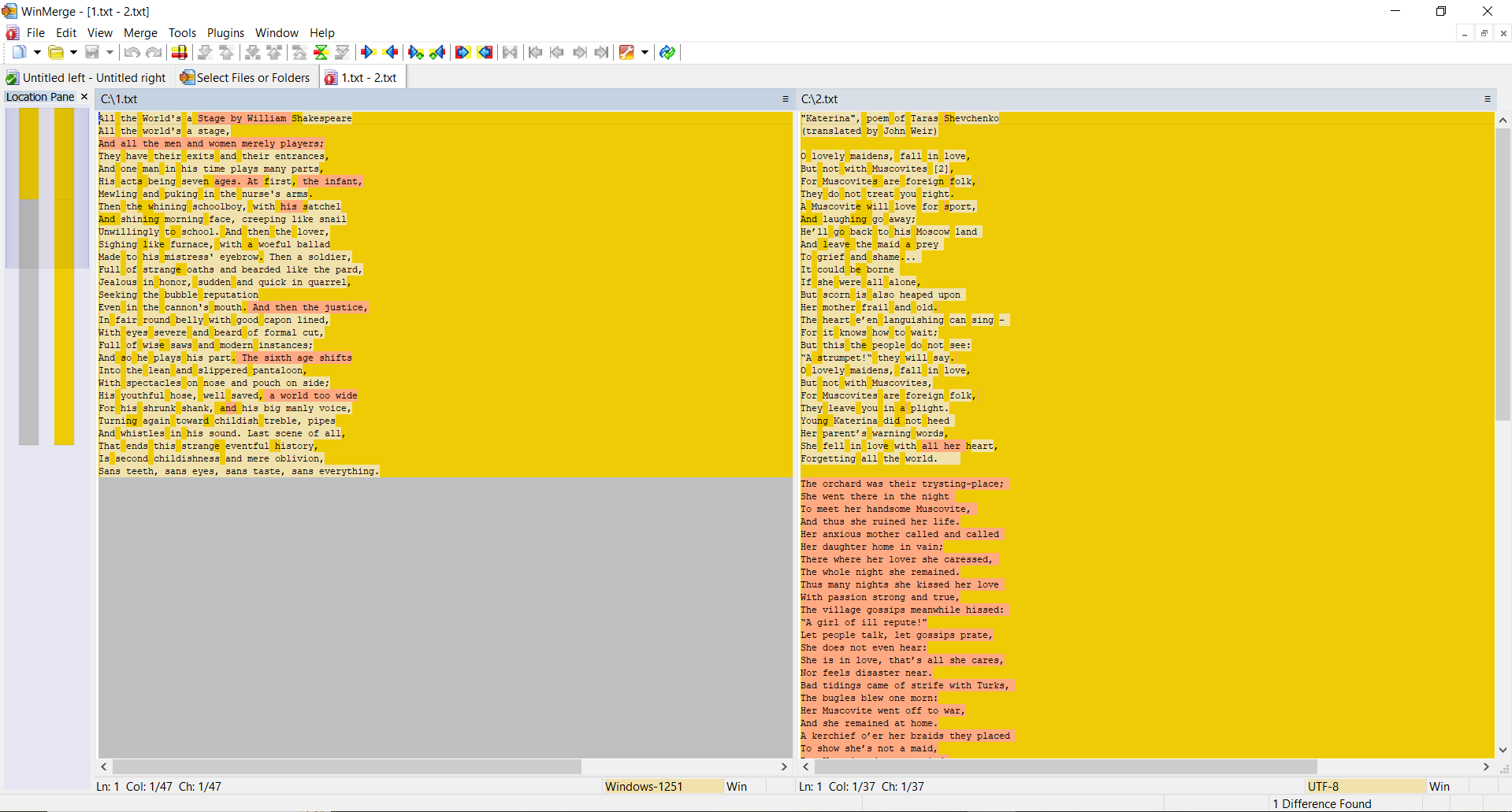
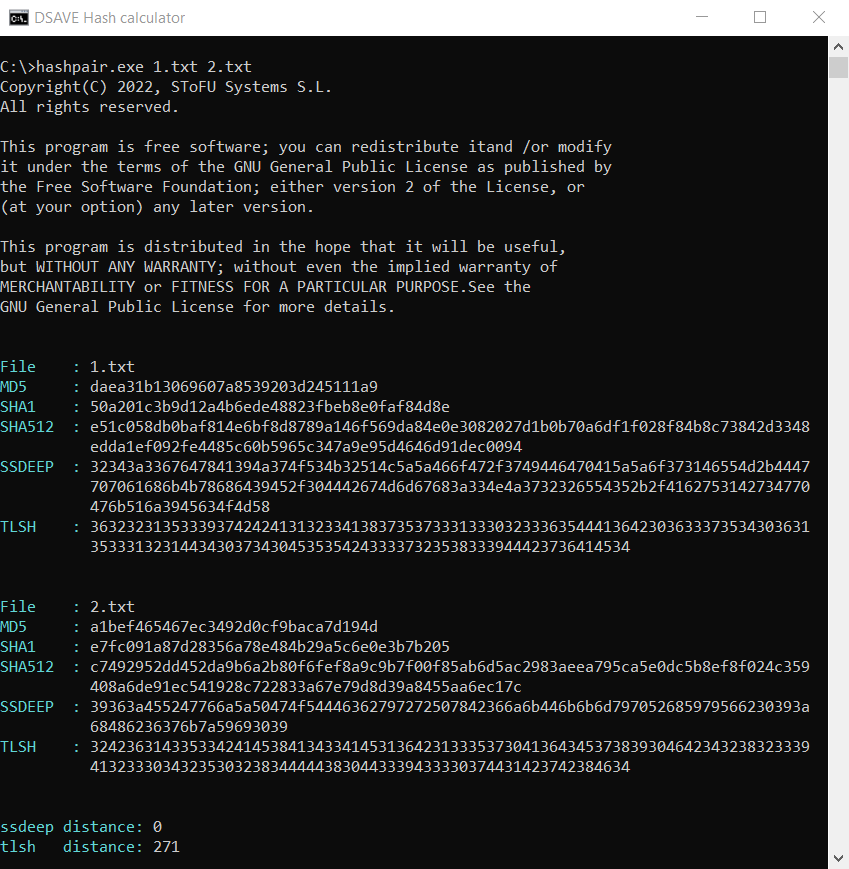
SSDEEP indique que les fichiers sont complètement différents, avec 0 % de correspondances. Cependant, TLSH affirme que les fichiers ne sont différents que de 27,1 %.
Pourquoi cela ? Après tout, nous considérons la distance entre deux fichiers texte complètement différents, n'est-ce pas ?
La chose est que, comme nous l'avons dit ci-dessus, l'algorithme TLSH prend en compte les fréquences.
Malgré le fait que les textes soient différents, ils sont néanmoins rédigés dans la même langue, utilisent le même alphabet et comportent un certain nombre de mots identiques. Cette caractéristique de cet algorithme de hachage aide à détecter les modifications de fichiers malveillants.
TEST 4 : comparer 2 fichiers système Windows
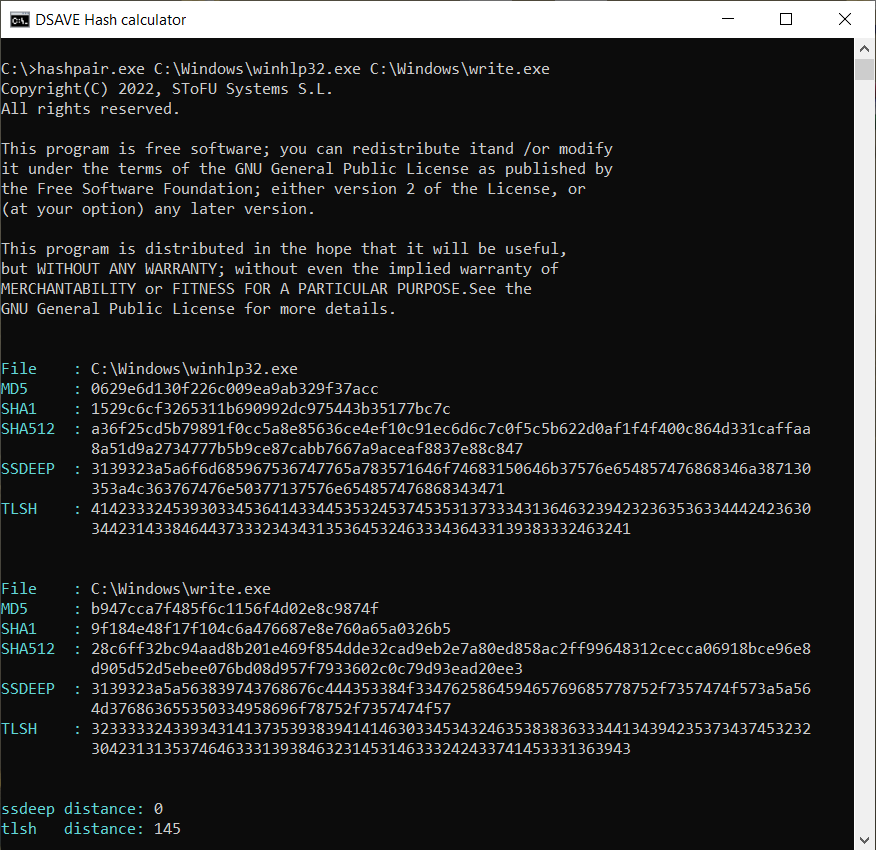
SSDEEP indique que les fichiers sont complètement différents, avec 0% de correspondances.
Cependant, l'algorithme TLSH indique que les fichiers ne diffèrent que de 14,5%. Cela est en partie dû au fait que les fichiers ont très probablement été compilés par le même compilateur, par la même entreprise, utilisant possiblement les mêmes modèles de code. Les fichiers ont des en-têtes VERSION_INFO et MZ similaires.
TEST 5 : comparer 2 fichiers système et notre fichier hashpair.exe
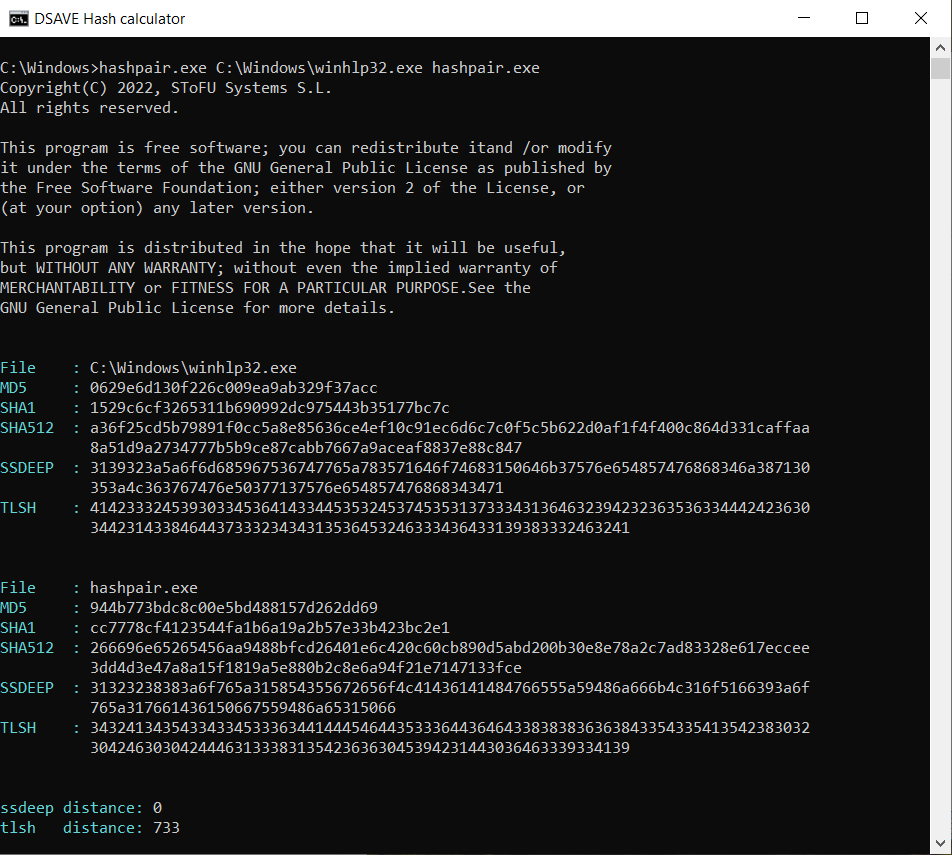
SSDEEP indique que les fichiers sont complètement différents, avec 0 % de correspondances.
L'algorithme TLSH indique que les fichiers diffèrent significativement, de 73,3%. Ces fichiers ont été compilés par différentes entreprises, utilisant différentes bibliothèques et différents compilateurs. Ces fichiers ont des VERSION_INFO différents et des en-têtes MZ différents. Ainsi, l'algorithme TLSH vous permet de catégoriser les fichiers exécutables, aidant à identifier des fichiers malveillants similaires ou des fichiers malveillants de la même famille.
Liste des outils utilisés
1. WinMerge: https://winmerge.org
WinMerge est un outil de différenciation et de fusion Open Source pour Windows. WinMerge peut comparer à la fois des dossiers et des fichiers, présentant les différences dans un format de texte visuel facile à comprendre et à manipuler.
2. Notepad++: https://notepad-plus-plus.org/downloads
Notepad++ est un éditeur de code source gratuit (au sens de « libre expression » et également en tant que « bière gratuite ») et un remplacement de Notepad qui prend en charge plusieurs langues. Fonctionnant dans l'environnement MS Windows, son utilisation est régie par la licence publique générale GNU.
GITHUB
Vous pouvez trouver le code de l'ensemble du projet sur notre github :
https://github.com/SToFU-Systems/DSAVE
QU'EST-CE QUI SUIT ?
Nous apprécions votre soutien et attendons avec impatience votre participation continue dans notre communauté
Dans le prochain article, nous écrirons ensemble le parseur de ressources PE le plus simple.
Toutes questions concernant les auteurs de l'article peuvent être envoyées à l'email : articles@stofu.io
Merci de votre attention et passez une bonne journée !




